YQL: Using Web Content For Non-Programmers

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.

 Celebrating 10 million developers
Celebrating 10 million developers


 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.Delivering great presentations is an art, and preparing the slides for them very much so, too. But we’re not going to talk about that. We’re also not going to get into the debate about whether to use open or closed technologies to create slide decks — this is something you need to hash out yourself, and there are some interesting discussions going on.
What I will talk about is how I (and you, of course) can use the Web to find content for your talks, record them, share them with others and save them for future audiences. I’ll also explain how to share it all for free and how to convert closed formats into open ones by using the Web.
Consider Some of Our Following Articles
- Talks To Help You Become A Better Front-End Engineer In 2013
- Useful Talks And Videos From Web Design Conferences
- 25 User Experience Videos That Are Worth Your Time
In 2010 I delivered a boatload of talks that people attended, downloaded, commented on and remixed for their own training sessions and presentations. I love to share my research and information, because when you set them free they can inspire and help others to get their own voices heard. Here’s how I did it.
Free Tools For Recording And Spicing Up Talks
Let’s begin with the only paid-for system I use in the whole process: I write my slides in Apple’s iLife application Keynote. I use it because when I do my work I’m usually offline (on trains, in airport lounges, in hotel rooms without free connectivity, etc.).
Keynote is great: I can resize and mask images, embed video, export as PDF, and there are a lot of beautiful, subtle and effective animations and transitions. Creators of slide tools should view Keynote as a model, and 280slides actually did so. Apple should also consider using a standardized format for HTML slides to import; in fact, this is one of the interesting discussions going on.
If I need to use high-quality images, I don’t spend money or time getting licensed content. Instead, I go to the advanced search option on Flickr, find photos with Creative Commons licenses and use these. All I need to do then is publish a link with each photo in my slides. Even I can do that much for copyright law.
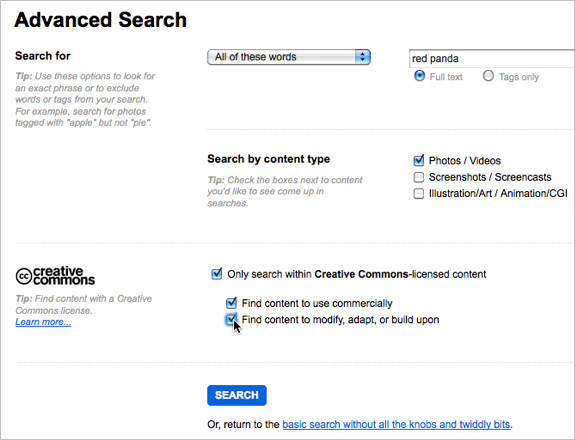
Flickr’s advanced search interface lets you specify the license of photos. You’ll probably want “Creative Commons” or “license-free.” Also check out The Commons for good old photos that have been donated to Flickr by libraries and museums.
Sharing Slides, Archiving The Originals
When I finish working, I give my talk using Keynote and export it as a PDF for sharing on the Web. I share my talk by uploading it to SlideShare, which entails the following:
- The talk gets converted to an embeddable Flash movie;
- The talk becomes an HTML transcript shown on the SlideShare website;
- The talk is hosted on its server, which means I don’t have to pay for traffic;
- People can “favorite,” bookmark and comment on my slides.
In addition to hosting my work on SlideShare, I usually also zip the original Keynote file; Keynote doesn’t format presentations as individual files, but rather as a folder of resources. I upload them to Amazon S3, where I pay a few pennies a month to store heaps of data. This is my back-up archive should anything terrible happen to SlideShare or my computer.
Asking For Feedback, Offering Code Examples
Another interesting service for speakers is SpeakerRate, where people can — wouldn’t you guess? — rate speakers and their talks. SpeakerRate also has an API that allows you to pull out the ratings in case you want to show them off on your portfolio.
I normally host code examples from my presentations on GitHub. There, they are accessible, and I can update and edit the code without having to create my own ZIP files for people to download. It’s incredibly useful for making quick changes in response to what people have requested in comments and for reacting to questions you received during the talk.
Hosting your code on GitHub automatically begins the process of versioning. People can embed and alter your original examples, and the code is displayed with color-coding, making it readable.
Setting up an account on GitHub and getting your code in there is pretty straightforward — just follow the simple tutorial.
Recording Talks
I normally record my talks so that I can listen to them in the gym and other places where I can’t write. There’s a free tool for this that works across all platforms. It’s called Audacity. Just hit the record button and it will create the audio file where you specify.
Editing in Audacity is as easy as cropping the things you don’t want:
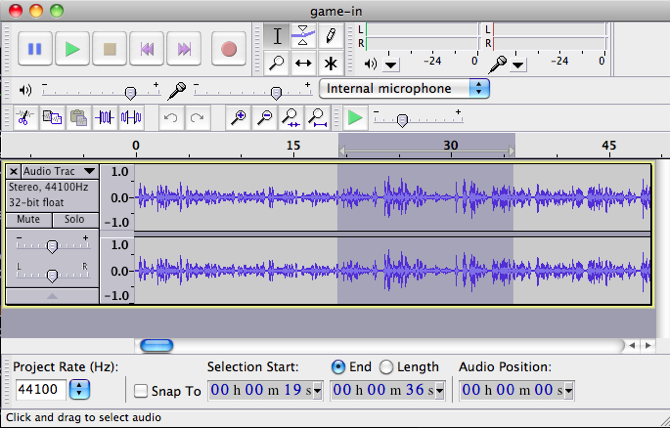
You can save the audio in MP3 or OGG (among other formats). I usually save them as MP3s and then add them to iTunes for tagging so that I can add cover art and other extras to prep them for the iPod.
Syncing Audio And Slides
With SlideShare, you can also create a “Slidecast” of your talks, which means syncing the audio and the slides. It’s a cool feature, but I don’t like the editor as it is; the handles used to define the start and end times of slides don’t allow them to be close together — and that can throw off the syncing. It’s also a time-consuming process. I’m working on some alternatives, and correspondence with SlideShare indicates that it is, too. Regardless, I’ve found that Slidecasts get a lot of visitors, so it can be worth it.
Recording Video
There was seldom a camera to record me wherever I spoke last year, and an amazing amount of recorded talks never see the light of day. If no camera is available to record your talk, then you can record the screen as you present.
One of Keynote’s lesser-known features is that you can record a video of your slides with a voiceover. Simply go to Play → Record Slideshow before giving your talk:
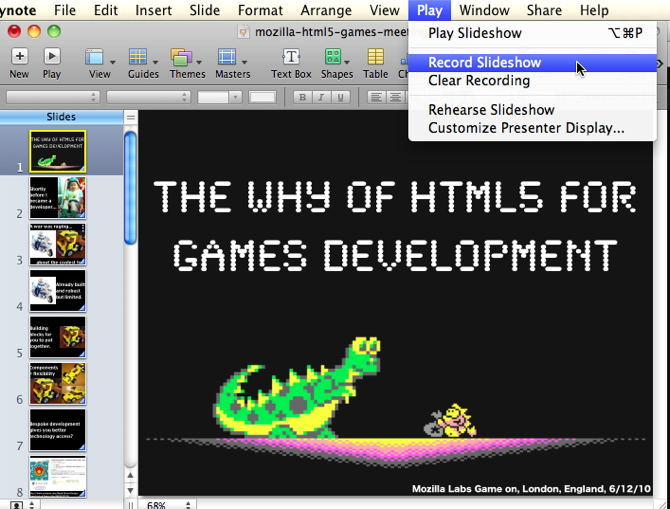
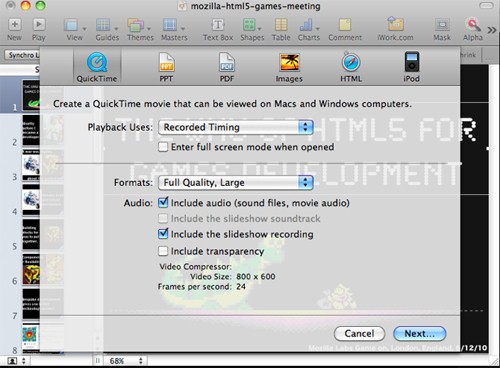
When you’re finished, export the video to QuickTime by going to File → Export:
If you don’t use Keynote or if you jump in and out of your presentation, then record the presentation on your computer screen. There are a few pieces of software to choose from for that.
VLC is a video player that’s free and compatible with all operating systems. It can also record the screen; go to File → Open Capture Device → Screen. You can record a high-quality video of everything that goes on. There’s even a feature that records a part of the screen by following the cursor.
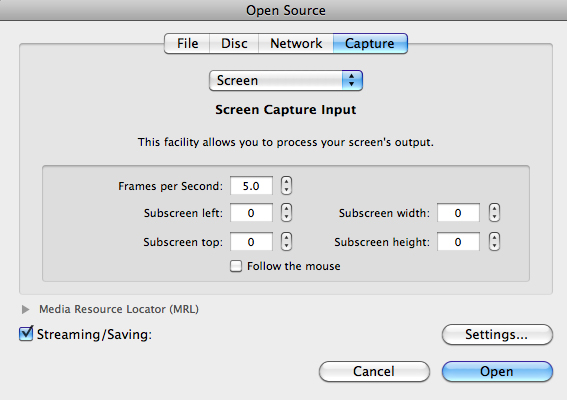
Simply check the “Streaming/Saving” checkbox, click “Advanced,” and define a suitable location and settings for your video:
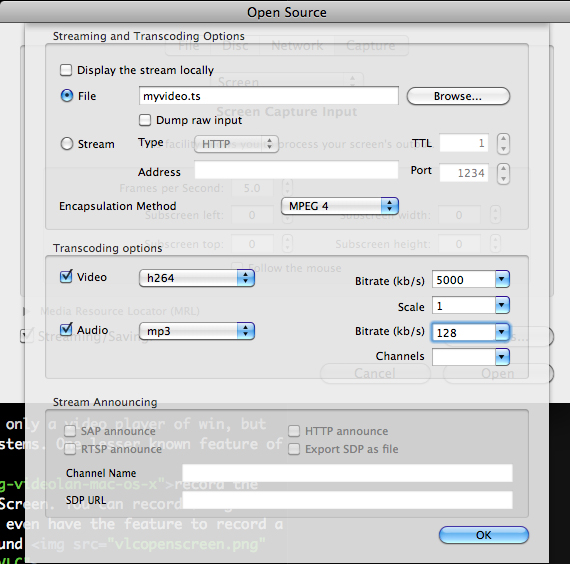
Screencasts are generally a great idea. Instead of performing live demos in my presentations, I record screencasts and embed them in Keynote. That way, I don’t need an Internet connection — they’re usually unreliable at conferences — and I can talk over the recording while on stage, rather than having to click, enter information and talk at the same time.
To screencast with a program other than VLC, I usually use the commercial app iShowU. When I was still using Windows, I had Camtasia. Both of these sit on your screen and let you record and pause easily:
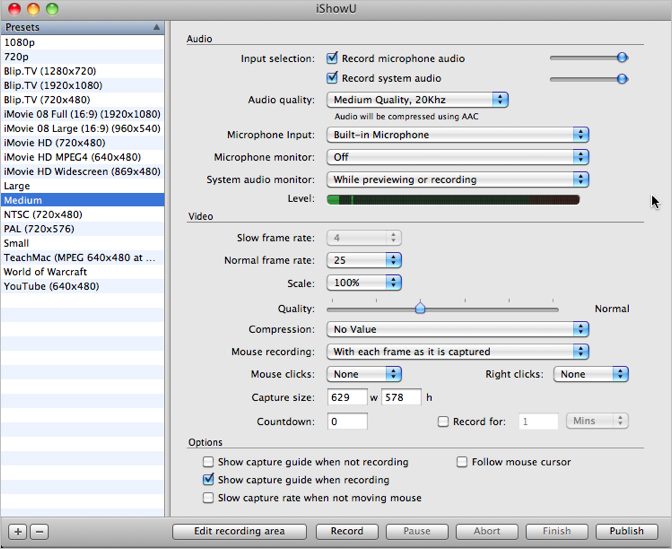
Nowadays, I also use hosted services.
Screenr is absolutely fabulous for this purpose. Just start the applet on the page, grant it access to your machine, and start recording. You have five minutes, with audio. When you’re finished, the movie is automatically converted, and you can export the video to YouTube. The video conversion happens more or less in real time. All you need to sign into Screenr is a Twitter account. With Screenr you can also tweet an embeddable version of the video. If you need similar service for longer videos, check out Screencast-o-matic.
Converting Video
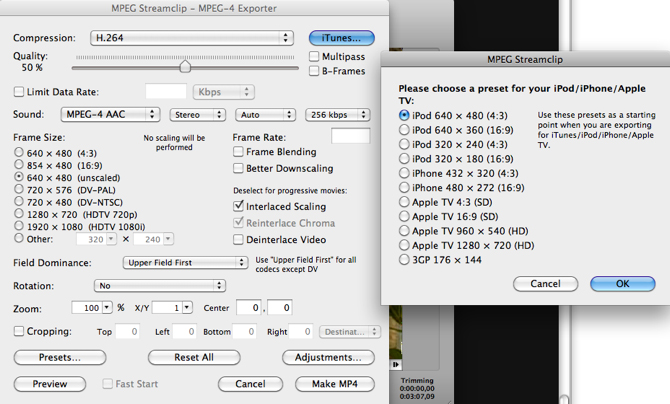
The free tool I use is MPEG Streamclip, and it’s available for Mac and Windows. Drag your video onto it, and select the format you need:
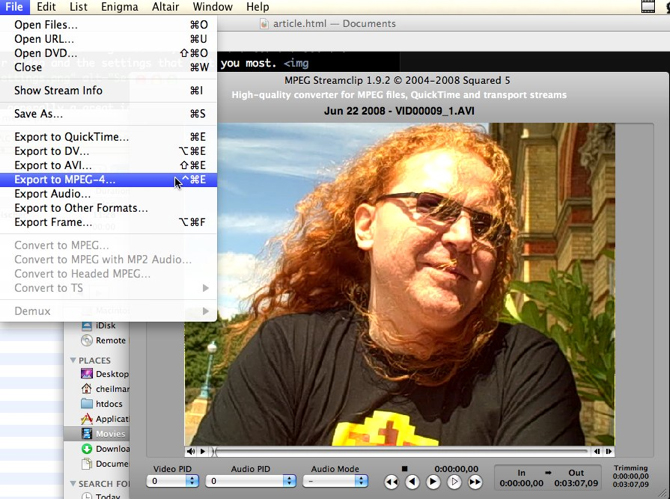
There are a lot of presets — iPod, iPad and so on:
Automatic Conversion And Hosting For Audio And Video
As you know, embedding videos on websites with HTML5 can be a pain, particularly when it comes to encoding them. Different browsers require different codecs.
There is, however, a simple way: Archive.org hosts all kinds of useful content. (The WayBackMachine, which keeps snapshots of how websites looked at a certain time, is probably the best known.) And you can host content there if you license it with Creative Commons. The good news? Archive.org automatically converts your content to HTML5-friendly formats!
Check out the recording of my talk on HTML5 for gaming. I recorded it with Audacity and saved and uploaded it as an MP3. The Ogg version was created by Archive.org. To embed it on a Web page, I just need to do this (line breaks added for readability):
<audio controls>
<source src="https://www.archive.org/download/
TheWhyOfHtml5ForGames/
TheWhyOfHtml5ForGames.ogg">
<source src="https://www.archive.org/download/
TheWhyOfHtml5ForGames/
TheWhyOfHtml5ForGames.mp3">
</audio>The same goes for video: free, fast hosting without limits, and automatic conversion. What more could you want?
Converting SlideShare To HTML
SlideShare creates embeddable Flash versions of my Keynote files (saved as PDF). I want to go with open technology and convert them back to HTML and images. You can do this with the mobile version of SlideShare.
If you call up a SlideShare presentation on a mobile device, you’ll get an HTML version with JavaScript and images. You can simulate this by sending the user agent of, for example, an iPad to the page before displaying it. In PHP, this takes a few lines of code:
$url = 'https://www.SlideShare.net/cheilmann/
the-why-of-html5-for-games-development';
$url = preg_replace('/.net//','.net/mobile/',$url);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0(iPad; U; CPU iPhone OS 3_2
like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko)
Version/4.0.4 Mobile/7B314 Safari/531.21.10");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$page = curl_exec($ch);
curl_close($ch);
echo $page;
I’ve scraped and converted the results, and now I can embed the SlideShare presentation as HTML and images using the converter tool:
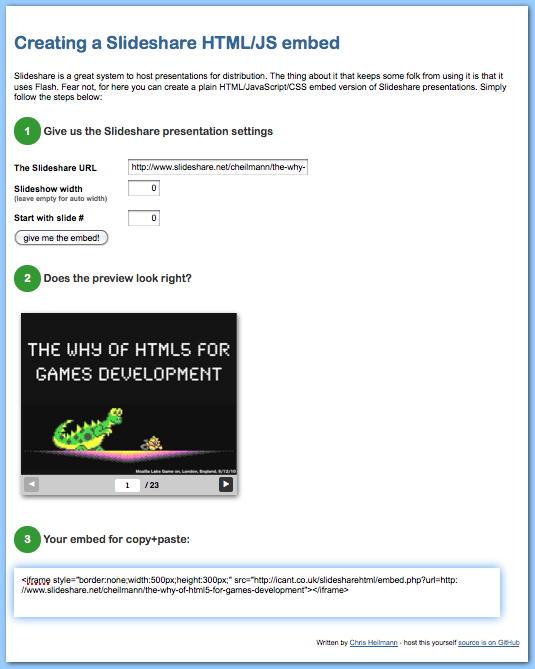
I still want to fix a few things, such as making the images preload intelligently and adding proper alternative text. SlideShare creates transcripts of your slides on the page, but if there are slides without images, then the two go out of sync. I’ve emailed the company about it, and a fix might be released soon.
Summary
When it comes to publishing presentations online, a lot can be automated by using the Web as a platform and taking advantage of conversion services. Many developers are working on Web-based presentation tools, and I am quite sure we’ll see a collaborative presentation platform come into existence this year, although the task might not be as easy as it sounds. I have listed the hidden requirements of presentation systems before, and some things still need to be fixed. Keep your eyes open and help the cause.


