When One Word Is More Meaningful Than A Thousand

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.


 Celebrating 10 million developers
Celebrating 10 million developers
You may be wondering why you’re reading about the good old semantics on Smashing Magazine. Why doesn’t this article deal with HTML5 or another fancy new language: anything but plain, clear, tired old semantics. You may even find the subject boring, being a devoted front-end developer. You don’t need a lecture on semantics. You’ve done a good job keeping up with the Web these last 10 years, and you know pretty much all there is to know.’
You may also want to take a look at the following related posts:
- HTML5 Semantics
- Microformats: What They Are and How To Use Them
- The Importance Of HTML5 Sectioning Elements
- The Semantic Grid System: Page Layout For Tomorrow
I’m writing about HTML semantics because I’ve noticed that semantic values are often handled sloppily and are sometimes neglected, even today. A huge void remains in semantic consistency and clarity, begging to be filled. We need better and more consistent naming conventions and smarter ways to construct HTML templates, to give us more consistent, clearer and readable HTML code. If that doesn’t sound like paradise, I don’t know what does.
The Bare Necessities Of Semantics
With all the functional mumbo jumbo hidden away in HTML5, some of us seem to have forgotten what HTML is really all about. Native video support is considered way cooler than the new header tags, somewhat understandably, but from a semantic and structural point of view, these latter elements present the most valuable improvement.
Semantic importance got a serious boost when accessibility became a big deal to us Web developers. But its powers go way beyond making our content available to those lacking the skills to surf the Web in regular ways. For one, making content recognizable to all kinds of crawlers (but most importantly search engines) could greatly improve the results of search queries on the Web. Rather than wading through trailers, film websites and product pages, wouldn’t it be much nicer to filter reviews directly and find out how a certain film has been received? Currently, no trustworthy mechanism exists to recognize or filter a broad range of content types, which is a serious loss for the Web as a whole.
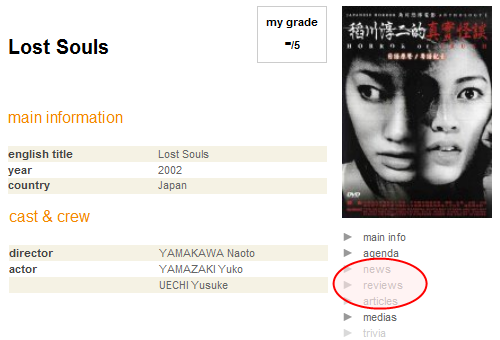
When looking for reviews, you don’t want to end up on a page with grayed-out links.
If all of that sounds like a far-off dream, then note that once you’ve distinguished between all the elements on your website, you will have little to no trouble styling or adding functional behavior to the page. The combination of context and proper semantics ensures a solid structure for all further front-end work, which is only made stronger by making sure every element is defined correctly.
The (Very Simple) Basics
Absolutely nothing is complex about semantics, and the basics have been preached for a long time now. A recap of the bare minimum won’t hurt anybody, though, so here it goes.
The HTML language has a range of tags with semantic meaning. If none of the available tags suits your needs, then two generic tags (span and div) are the HTML equivalents of the word “thing,” which can be used in combination with one or more classes to add (not necessarily standardized) semantic value to your elements. It’s the microformats idea without the actual microformats. Some basic examples:
- Main navigation:
nav.main(HTML5) ordiv.navMain; - An article:
article(HTML5) ordiv.article; - Article header:
article>header(HTML5) ordiv.article>div.header
That’s all there is to it, really. Adding semantic value is about choosing the correct tag(s) and/or applying the correct label(s) to an element. It really makes you wonder why applying this simple concept consistently to professionally developed websites has proven to be so difficult, even today.
For those of you who don’t like the microformats ideology, you could also go all HTML5 and look at the HTML5 Microdata proposition. What follows in this article reflects both methodologies equally, so the choice is entirely up to you.
Sampling The Web
To illustrate my point, I took some quick samples from some of today’s leading websites. By no means do these samples hold any scientific validity, nor is this a purposeful bash of the websites I’ve singled out. They are simply chosen because I believe they best represent their kind. I hope the data speaks for itself either way.
To grasp the semantic consistency within a website, I tried finding some common content types. Content types are easy to recognize and even easier to label. Before I get to the data, though, let’s look at one way we could label products in a Web store:
- Product detail:
div.product; - Products added to your basket:
.basket li.product; - Promo product in a list:
.categoryList .product.promo; - Etc.
Products are everywhere in a Web store, so it seems logical that the product class would reappear across the pages for every instance of a product on the website. After all, whether a product is located in a “Related items” list, added to a basket or shown in full doesn’t really change its semantic nature, so why change its structure or class name?
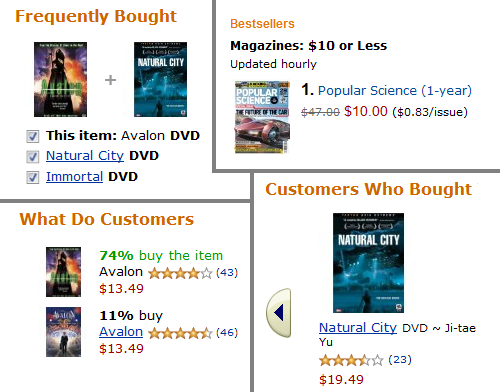
These are all products, appearing as variants or in different contexts.
For my sample, I picked five content types (story, product, video, person, blog post) and picked four websites to represent each content type. To check for semantic consistency, I looked at the labels on a shortlist (a list of content type instances) and the content type’s detail. The following table summarizes my findings:
| Type | Website | Shortlist | Detail |
|---|---|---|---|
| Story | BBC | div.hpData | table.storycontent |
| Story | New York Times | div.story | div#article |
| Story | CNN | ul.cnn_bulletbin li | div.cnn_storyarea |
| Story | MSN | li.ter | div.w649 (?) |
| Product | Amazon | div.asinItem | - |
| Product | Apple Store | li.product | div.product-selection |
| Product | Play.com | div.info | div.dvd |
| Product | YesAsia | div.item | div#productpage |
| Video | YouTube | div.video-cell | div.video-info |
| Video | Vimeo | div.item | div.video_container_hd |
| Video | Dailymotion | div.video | div.dmco_box |
| Video | eBaum’s World | div.mediaitem | div#videoContentContainer |
| Person | div.UIFullListing | div.profile_top_wash and div.profile_bottom_wash | |
| Person | Last.fm | div.user | div.user |
| Person | Virb | table.people td | div#profile_wrapper.artist |
| Person | div#following_list span.vcard | div#profile | |
| Blog post | Zeldman | - | - |
| Blog post | A List Apart | div.item | - or body.articles |
| Blog post | Jens Meiert | div.item | .content .col-1 |
| Blog post | Webaim | div#features | div.section |
Apart from last.fm, none of the websites I checked got it right, even though the content types I chose were very easy to label. Apple and the New York Times came quite close, but some of the others are miles away from what you’d expect to find. And that’s just looking at the root tag of the content type. The structure and classes within are often even worse, bordering on complete randomness. Another thing to note is that blogs about Web design seem to score the worst.
Think Components, Not Pages
There is, of course, not one single cause of this problem, nor is the solution simple. But you can make one important mental shift as a front-end developer to give your work more semantic consistency. The key is to stop thinking of a website as a collection of pages and to instead look for common components.
Front-end developers tend to work the same as designers: start with the home page, finish that, and then move on to the second wireframe — copy the reusable components, adapt if needed, and then repeat until all pages are done. This process requires a lot of copying, adapting and checking older pages to find reusable elements. It is a true killer of consistency — invoking spur-of-the-moment labels and destroying semantic consistency.
Because we want consistency, both in structure and semantics, focusing on a single component at a time is better. When you need to write the HTML code for a product, check each wireframe for variations within and across products. Write code that can handle all existing variants. Once that is done, you will have a consistent and solid model to describe your component that you can used wherever you want.
Making It All Happen
I know from experience that this mental shift takes some time to get used to, and the only way to get it working is to throw yourself in and practice. I’ll share some quick pointers to make the whole process a little less daunting.
Think Beyond Styling Needs and Performance
.productList li or .products li
ul li.productConsider the example above. As Web developers, we’ve been taught that the first option should be preferred. From a performance and styling perspective, this is indeed the case. But putting on your semantic hat, you’ll notice that to recognize the list items in the first example as products, you need to make a deduction. Singling out all products on a page isn’t as easy as looking for the product class. Automated systems should also account for the possibility that a product is defined as a list item inside a parent that refers to a collection of products. Not such a big deal for the human brain, but writing a foolproof, fully automated implementation isn’t as easy.
On top of that, the second option allows for more flexibility because it makes it possible to drop instances of other content types into the same list without running into styling hell, while at the same time ensuring semantic integrity. It wouldn’t be the first time I was asked to merge a news and event shortlist into one big list just because there wasn’t sufficient content to warrant separate lists. The second option would give you a smaller headache, especially if you’re nearing an important deadline.
Bottom line: try to minimize semantic deductions, and keep the code clear and simple. Pick unique class names for components, and stick with them throughout the entire project.
Don’t Mix Responsibilities
I know that many people like to mix wireframing, HTML and even design into one organic and homogeneous process. The downside to this is that you will have a hard time not compromising your work. When you’re designing, writing HTML and CSS is not priority number one; and once the design is done, you’ll find it tough to go back and rework your code to match HTML and CSS standards.
It’s also refreshing to try to build a website based purely on a set of wireframes, without the slightest notion of design. It helps you focus on meaning and makes it easier to spot components that are actually the same but could differ wildly design-wise. And if you’ve done it right, you’ll find that during CSS development, you don’t have to adapt the HTML at all, unless the design calls for major structural changes.
Try to build your HTML templates based on wireframes, and save the design and CSS for when your static HTML templates are completed.
Automate Your Job
Automation is a major key to success. Whether you use existing tools (such as a CMS) or build your own (as we do), automating the job of building static templates could help you to define a component once and reuse the code everywhere that the component is featured in your templates. The process itself (when done right) ensures semantic consistency and is sure to bring you new insight when constructing HTML templates.
At my current job, we build such a tool based on components (recurring HTML code blocks) and schemes (outlines of each template that refer to these components). Thrown in some simple program logic (if and loop statements, parameters) and allow for proper nesting methods, and you’re good to go.
Semantic Consistency Across Projects
Finally, keep a list of components you’ve made over multiple projects. Many components will be relevant for each new project and will be semantically identical, meaning that the HTML structure should be identical just as well (save some wrappers for visual CSS trickery, if you’re into that).
Once you have such a list of components, starting up a new project will be a lot faster, and you’ll have the added benefit of semantic consistency across all of your projects.
Banana ≠ Curvy Yellow Fruit
Semantics is all about identifying objects, but it goes beyond simply slapping a label on every object that comes your way. If you have a blog, and you randomly throw around classes like article, story, blogpost and news, then your website will lack semantic consistency, making all your hard work amount to very little. Semantics have no point when they are not applied consistently, even though today’s technology does very little with them — which, by the way, is no surprise given that locating a simple “product” on most Web stores is nearly impossible these days.

People looking for bananas might think twice before buying these.
The next time you begin a project, try to view a Web page as a collection of building blocks. Start by constructing these building blocks first, and worry about building the pages later. Come up with a single label for an HTML component, and use it consistently across your website. It won’t make styling harder, and it won’t affect the way you write JavaScript. Over time, you can take it further by being semantically consistent over multiple projects.
If your main job is to develop static HTML templates, try to automate your work. You’ll find that you spend more time writing flexible and solid HTML structures and less time copying and adapting code from point A to point B. It makes your job more interesting and makes the Web a better and more meaningful place.
Further Resources
- Microformats Summarizes the microformats ideology. Read more about using class names as semantic aids.
- HTML5 Microdata Explains how HTML5 is built to standardize the use of flexible semantics.


