Searchable Dynamic Content With AJAX Crawling

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend. Celebrating 10 million developers
Celebrating 10 million developers



Google Search likes simple, easy-to-crawl websites. You like dynamic websites that show off your work and that really pop. But search engines can’t run your JavaScript. That cool AJAX routine that loads your content is hurting your SEO.
Google’s robots parse HTML with ease; they can pull apart Word documents, PDFs and even images from the far corners of your website. But as far as they’re concerned, AJAX content is invisible.
The Problem With AJAX
AJAX has revolutionized the Web, but it has also hidden its content. If you have a Twitter account, try viewing the source of your profile page. There are no tweets there — just code! Almost everything on a Twitter page is built dynamically through JavaScript, and the crawlers can’t see any of it. That’s why Google developed AJAX crawling.
Because Google can’t get dynamic content from HTML, you will need to provide it another way. But there are two big problems: Google won’t run your JavaScript, and it doesn’t trust you.
Google indexes the entire Web, but it doesn’t run JavaScript. Modern websites are little applications that run in the browser, but running those applications as they index is just too slow for Google and everyone else.
The trust problem is trickier. Every website wants to come out first in search results; your website competes with everyone else’s for the top position. Google can’t just give you an API to return your content because some websites use dirty tricks like cloaking to try to rank higher. Search engines can’t trust that you’ll do the right thing.
Google needs a way to let you serve AJAX content to browsers while serving simple HTML to crawlers. In other words, you need the same content in multiple formats.
Two URLs For The Same Content
Let’s start with a simple example. I’m part of an open-source project called Spiffy UI. It’s a Google Web Toolkit (GWT) framework for REST and rapid development. We wanted to show off our framework, so we made SpiffyUI.org using GWT.
GWT is a dynamic framework that puts all of our content in JavaScript. Our index.html file looks like this:
<body>
<script type="text/javascript" language="javascript"
src="org.spiffyui.spsample.index.nocache.js"></script>
</body>Everything is added to the page with JavaScript, and we control our content with hash tags (I’ll explain why a little later). Every time you move to another page in our application, you get a new hash tag. Click on the “CSS” link and you’ll end up here:
https://www.spiffyui.org#cssThe URL in the address bar will look like this in most browsers:
https://www.spiffyui.org/?cssWe’ve fixed it up with HTML5. I’ll show you how later in this article.
This simple hash works well for our application and makes it bookmarkable, but it isn’t crawlable. Google doesn’t know what a hash tag means or how to get the content from it, but it does provide an alternate method for a website to return content. So, we let Google know that our hash is really JavaScript code instead of just an anchor on the page by adding an exclamation point (a “bang”), like this:
https://www.spiffyui.org#!cssThis hash bang is the secret sauce in the whole AJAX crawling scheme. When Google sees these two characters together, it knows that more content is hidden by JavaScript. It gives us a chance to return the full content by making a second request to a special URL:
https://www.spiffyui.org?_escaped_fragment_=cssThe new URL has replaced the #! with ?_escapedfragment=. Using a URL parameter instead of a hash tag is important, because parameters are sent to the server, whereas hash tags are available only to the browser.
That new URL lets us return the same content in HTML format when Google’s crawler requests it. Confused? Let’s look at how it works, step by step.
Snippets Of HTML
The whole page is rendered in JavaScript. We needed to get that content into HTML so that it is accessible to Google. The first step was to separate SpiffyUI.org into snippets of HTML.
Google still thinks of a website as a set of pages, so we needed to serve our content that way. This was pretty easy with our application, because we have a set of pages, and each one is a separate logical section. The first step was to make the pages bookmarkable.
Bookmarking
Most of the time, JavaScript just changes something within the page: when you click that button or pop up that panel, the URL of the page does not change. That’s fine for simple pages, but when you’re serving content through JavaScript, you want give users unique URLs so that they can bookmark certain areas of your application.
JavaScript applications can change the URL of the current page, so they usually support bookmarking via the addition of hash tags. Hash tags work better than any other URL mechanism because they’re not sent to the server; they’re the only part of the URL that can be changed without having to refresh the page.
The hash tag is essentially a value that makes sense in the context of your application. Choose a tag that is logical for the area of your application that it represents, and add it to the hash like this:
https://www.spiffyui.org#cssWhen a user accesses this URL again, we use JavaScript to read the hash tag and send the user to the page that contains the CSS.
You can choose anything you want for your hash tag, but try to keep it readable, because users will be looking at it. We give our hashes tags like css, rest and security.
Because you can name the hash tag anything you want, adding the extra bang for Google is easy. Just slide it between the hash and the tag, like this:
https://www.spiffyui.org#!cssYou can manage all of your hash tags manually, but most JavaScript history frameworks will do it for you. All of the plug-ins that support HTML4 use hash tags, and many of them have options for making URLs bookmarkable. We use History.js by Ben Lupton. It’s easy to use, it’s open source, and it has excellent support for HTML5 history integration. We’ll talk more about that shortly.
Serving Up Snippets
The hash tag makes an application bookmarkable, and the bang makes it crawlable. Now Google can ask for special escaped-fragment URLs like so:
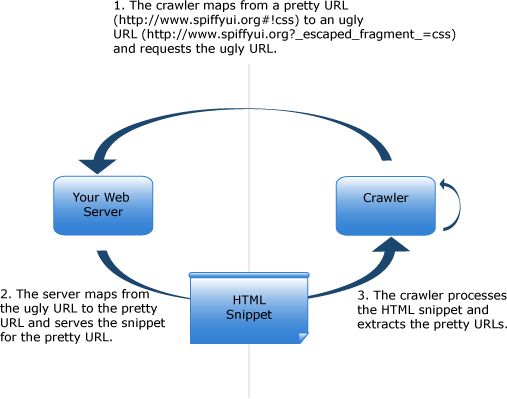
When the crawler accesses our ugly URL, we need to return simple HTML. We can’t handle that in JavaScript because the crawler doesn’t run JavaScript in the crawler. So, it all has to come from the server.
You can implement your server in PHP, Ruby or any other language, as long as it delivers HTML. SpiffyUI.org is a Java application, so we deliver our content with a Java servlet.
The escaped fragment tells us what to serve, and the servlet gives us a place to serve it from. Now we need the actual content.
Getting the content to serve is tricky. Most applications mix the content in with the code; but we don’t want to parse the readable text out of the JavaScript. Luckily, Spiffy UI has an HTML-templating mechanism. The templates are embedded in the JavaScript but also included on the server. When the escaped fragment looks for the ID css, we just have to serve CSSPanel.html.
The template without any styling looks very plain, but Google just needs the content. Users see our page with all of the styles and dynamic features:
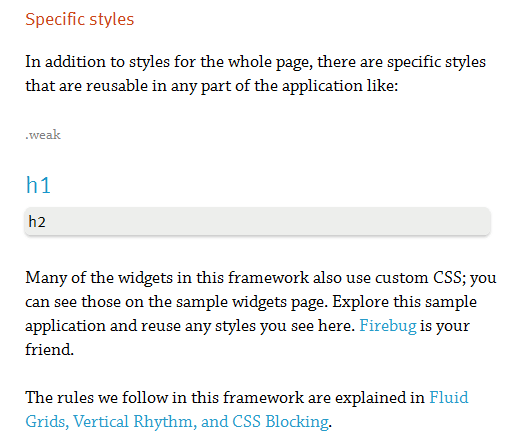
Google gets only the unstyled version:

You can see all of the source code for our SiteMapServlet.java servlet. This servlet is mostly just a look-up table that takes an ID and serves the associated content from somewhere on our server. It’s called SiteMapServlet.java because this class also handles the generation of our site map.
Tying It All Together With A Site Map
Our site map tells the crawler what’s available in our application. Every website should have a site map; AJAX crawling doesn’t work without one.
Site maps are simple XML documents that list the URLs in an application. They can also include data about the priority and update frequency of the app’s pages. Normal entries for site maps look like this:
<url>
<loc>https://www.spiffyui.org/</loc>
<lastmod>2011-07-26</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>Our AJAX-crawlable entries look like this:
<url>
<loc>https://www.spiffyui.org/#!css</loc>
<lastmod>2011-07-26</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>The hash bang tells Google that this is an escaped fragment, and the rest works like any other page. You can mix and match AJAX URLs and regular URLs, and you can use only one site map for everything.
You could write your site map by hand, but there are tools that will save you a lot of time. The key is to format the site map well and submit it to Google Webmaster Tools.
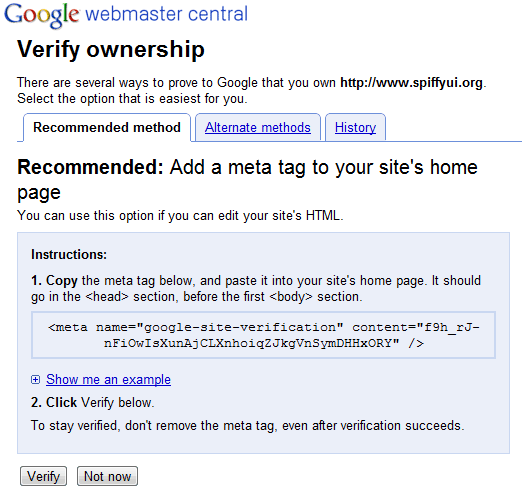
Google Webmaster Tools
Google Webmaster Tools gives you the chance to tell Google about your website. Log in with your Google ID, or create a new account, and then verify your website.
Once you’ve verified, you can submit your site map and then Google will start indexing your URLs.
And then you wait. This part is maddening. It took about two weeks for SpiffyUI.org to show up properly in Google Search. I posted to the help forums half a dozen times, thinking it was broken.
There’s no easy way to make sure everything is working, but there are a few tools to help you see what’s going on. The best one is Fetch as Googlebot, which shows you exactly what Google sees when it crawls your website. You can access it in your dashboard in Google Webmaster Tools under “Diagnostics.”
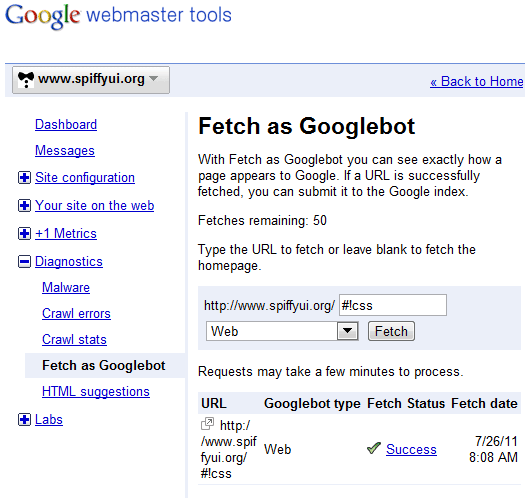
Enter a hash bang URL from your website, and click “Fetch.” Google will tell you whether the fetch has succeeded and, if it has, will show you the content it sees.
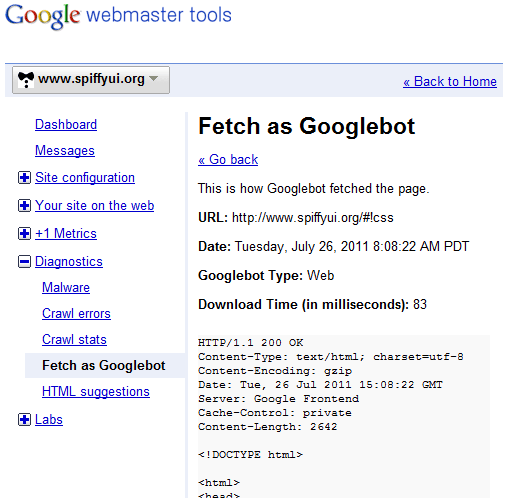
If Fetch as Googlebot works as expected, then you’re returning the escaped URLs correctly. But you should check a few more things:
- Validate your site map.
- Manually try the URLs in your site map. Make sure to try the hash-bang and escaped versions.
- Check the Google result for your website by searching for
site:www.yoursite.com.
Making Pretty URLs With HTML5
Twitter leaves the hash bang visible in its URLs, like this:
https://twitter.com/#!/ZackGrossbartThis works well for AJAX crawling, but again, it’s slightly ugly. You can make your URLs prettier by integrating HTML5 history.
Spiffy UI uses HTML5 history integration to turn a hash-bang URL like this…
https://www.spiffyui.org#!css… into a pretty URL like this:
https://www.spiffyui.org?cssHTML5 history makes it possible to change this URL parameter, because the hash tag is the only part of the URL that you can change in HTML4. If you change anything else, the entire page reloads. HTML5 history changes the entire URL without refreshing the page, and we can make the URL look any way we want.
This nicer URL works in our application, but we still list the hash-bang version on our site map. And when browsers access the hash-bang URL, we change it to the nicer one with a little JavaScript.
Cloaking
Earlier, I mentioned cloaking. It is the practice of trying to boost a website’s ranking in search results by showing one set of pages to Google and another to regular browsers. Google doesn’t like cloaking and may remove offending websites from its search index.
AJAX-crawling applications always show different results to Google than to regular browsers, but it isn’t cloaking if the HTML snippets contain the same content that the user would see in the browser. The real mystery is how Google can tell whether a website is cloaking or not; crawlers can’t compare content programmatically because they don’t run JavaScript. It’s all part of Google’s Googley power.
Regardless of how it’s detected, cloaking is a bad idea. You might not get caught, but if you do, you’ll be removed from the search index.
Hash Bang Is A Little Ugly, But It Works
I’m an engineer, and my first response to this scheme is “Yuck!” It just feels wrong; we’re warping the purpose of URLs and relying on magic strings. But I understand where Google is coming from; the problem is extremely difficult. Search engines need to get useful information from inherently untrustworthy sources: us.
Hash bangs shouldn’t replace every URL on the Web. Some websites have had serious problems with hash-bang URLs because they rely on JavaScript to serve content. Simple pages don’t need hash bangs, but AJAX pages do. The URLs do look a bit ugly, but you can fix that with HTML5.
Other Resources
We’ve covered a lot in this article. Supporting AJAX crawling means that you need to change your client’s code and your server’s code. Here are some links to find out more:
- “Making AJAX Applications Crawlable,” Google Code
- sitemaps.org
- Google Webmaster Tools
- Spiffy UI source code, with a complete example of AJAX crawling.
Thanks to Kristen Riley for help with some of the images in this article.
Further Reading
- Learning JavaScript: Essentials And Guidelines
- Why AJAX Isn’t Enough
- Server-Side Rendering With React, Node And Express
- A Beginner’s Guide To jQuery-Based JSON API Clients


