Integrating Amazon S3 With WordPress

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.


 Celebrating 10 million developers
Celebrating 10 million developers
 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.
The reason for using Amazon S3 to store important data follows from the “3-2-1” backup rule, coined by Peter Krogh. According to the 3-2-1 rule, you would keep three copies of any critical data: the original data, a backup copy on removable media, and a second backup at an off-site location (in our case, Amazon’s S3 cloud).
Cloud Computing, Concisely
Cloud computing is an umbrella term for any data or software hosted outside of your local system. Cloud computing is categorized into three main service types: infrastructure as a service (IaaS), platform as a service (PaaS) and software as a service (SaaS).
- Infrastructure as a service. IaaS provides virtual storage, virtual machines and other hardware resources that clients can use on a pay-per-use basis. Amazon S3, Amazon EC2 and RackSpace Cloud are examples of IaaS.
- Platform as a service. PaaS provides virtual machines, application programming interfaces, frameworks and operating systems that clients can deploy for their own applications on the Web. Force.com, Google AppEngine and Windows Azure are examples of PaaS.
- Software as a service. Perhaps the most common type of cloud service is SaaS. Most people use services of this type daily. SaaS provides a complete application operating environment, which the user accesses through a browser rather than a locally installed application. SalesForce.com, Gmail, Google Apps and Basecamp are some examples of SaaS.
For all of the service types listed above, the service provider is responsible for managing the cloud system on behalf of the user. The user is spared the tedium of having to manage the infrastructure required to operate a particular service.
Amazon S3 In A Nutshell
Amazon Web Services (AWS) is a bouquet of Web services offered by Amazon that together make up a cloud computing platform. The most essential and best known of these services are Amazon EC2 and Amazon S3. AWS also includes CloudFront, Simple Queue Service, SimpleDB, Elastic Block Store. In this article, we will focus exclusively on Amazon S3.
Amazon S3 is cloud-based data-storage infrastructure that is accessible to the user programmatically via a Web service API (either SOAP or REST). Using the API, the user can store various kinds of data in the S3 cloud. They can store and retrieve data from anywhere on the Web and at anytime using the API. But S3 is nothing like the file system you use on your computer. A lot of people think of S3 as a remote file system, containing a hierarchy of files and directories hosted by Amazon. Nothing could be further from the truth.
Amazon S3 is a flat-namespace storage system, devoid of any hierarchy whatsoever. Each storage container in S3 is called a “bucket,” and each bucket serves the same function as that of a directory in a normal file system. However, there is no hierarchy within a bucket (that is, you cannot create a bucket within a bucket). Each bucket allows you to store various kinds of data, ranging in size from 1 B to a whopping 5 TB (terabytes), although the largest object that can be uploaded in a single PUT request is 5 GB. Obviously, I’ve not experimented with such enormous files.
A file stored in a bucket is referred to as an object. An object is the basic unit of stored data on S3. Objects consist of data and meta data. The meta data is a set of name-value pairs that describe the object. Meta data is optional but often adds immense value, whether it’s the default meta data added by S3 (such as the date last modified) or standard HTTP meta data such as Content-Type.
So, what kinds of objects can you store on S3? Any kind you like. It could be a simple text file, a style sheet, programming source code, or a binary file such as an image, video or ZIP file. Each S3 object has its own URL, which you can use to access the object in a browser (if appropriate permissions are set — more on this later).
You can write the URL in two formats, which look something like this:


The bucket’s name here is deliberately simple, codediesel. It can be more complex, reflecting the structure of your application, like codediesel.wordpress.backup or codediesel.assets.images.
Every S3 object has a unique URL, formed by concatenating the following components:
- Protocol (
https://orhttps://), - S3 end point (
s3.amazonaws.com), - Bucket’s name,
- Object key, starting with
/.
In order to be able to identify buckets, the S3 system requires that you assign a name to each bucket, which must be unique across the S3 bucket namespace. So, if a user has named one of their buckets company-docs, you cannot create a bucket with that name anywhere in the S3 namespace. Object names in a bucket, however, must be unique only to that bucket; so, two different buckets can have objects with the same name. Also, you can describe objects stored in buckets with additional information using meta data.
Bucket names must comply with the following requirements:
- May contain lowercase letters, numbers, periods (
.), underscores (_) and hyphens (-); - Must begin with a number or letter;
- Must be between 3 and 255 characters long;
- May not be formatted as an IP address (e.g.
265.255.5.4).
In short, Amazon S3 provides a highly reliable cloud-based storage infrastructure, accessible via a SOAP or REST API. Some common usage scenarios for S3 are:
- Backup and storage. Provide data backup and storage services.
- Host applications. Provide services that deploy, install and manage Web applications.
- Host media. Build a redundant, scalable and highly available infrastructure that hosts video, photo or music uploads and downloads.
- Deliver software. Host your software applications that customers can download.
Amazon S3’s Pricing Model
Amazon S3 is a paid service; you need to attach a credit card to your Amazon account when signing up. But it is surprisingly low priced, and you pay only for what you use; if you use no resources in your S3 account, you pay nothing. Also, as part of the AWS “Free Usage Tier,” upon signing up, new AWS customers receive 5 GB of Amazon S3 storage, 20,000 GET requests, 2,000 PUT requests, and 15 GB of data transfer out each month free for one year.
So, how much do you pay after the free period. As a rough estimate, if you stored 5 GB of data per month, with data transfers of 15 GB and 40,000 GET and PUT requests a month, the cost would be around $2.60 per month. That’s lower than the cost of a burger — inexpensive by any standard. The prices may change, so use the calculator on the S3 website.
Your S3 usage is charged according to three main parameters:
- The total amount of data stored,
- The total amount of data transferred in and out of S3 per month,
- The number of requests made to S3 per month.
Your S3 storage charges are calculated on a unit known as a gigabyte-month. If you store 1 GB for one month, you’ll be charged for one gigabyte-month, which is $0.14.
Your data transfer charges are based on the amount of data uploaded and downloaded from S3. Data transferred out of S3 is charged on a sliding scale, starting at $0.12 per gigabyte and decreasing based on volume, reaching $0.050 per gigabyte for all outgoing data transfer in excess of 350 terabytes per month. Note that there is no charge for data transferred within an Amazon S3 “region” via a COPY request, and no charge for data transferred between Amazon EC2 and Amazon S3 within the same region or for data transferred between the Amazon EC2 Northern Virginia region and the Amazon S3 US standard region. To avoid surprises, always check the latest pricing policies on Amazon.
Introduction To The Amazon S3 API And CloudFusion
Now with the theory behind us, let’s get to the fun part: writing code. But before that, you will need to register with S3 and create an AWS account. If you don’t already have one, you’ll be prompted to create one when you sign up for Amazon S3.
Before moving on to the coding part, let’s get acquainted with some visual tools that we can use to work with Amazon S3. Various visual and command-line tools are available to help you manage your S3 account and the data in it. Because the visual tools are easy to work with and user-friendly, we will focus on them in this article. I prefer working with the AWS Management Console for security reasons.
AWS Management Console
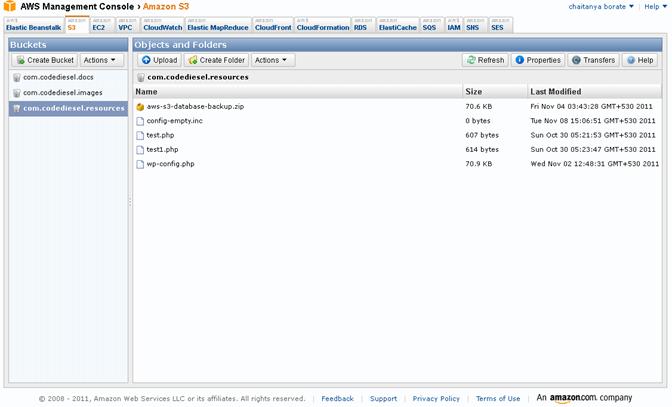
The Management Console is a part of the AWS. Because it is a part of your AWS account, no configuration is necessary. Once you’ve logged in, you have full access to all of your S3 data and other AWS services. You can create new buckets, create objects, apply security policies, copy objects to different buckets, and perform a multitude of other functions.
S3Fox Organizer
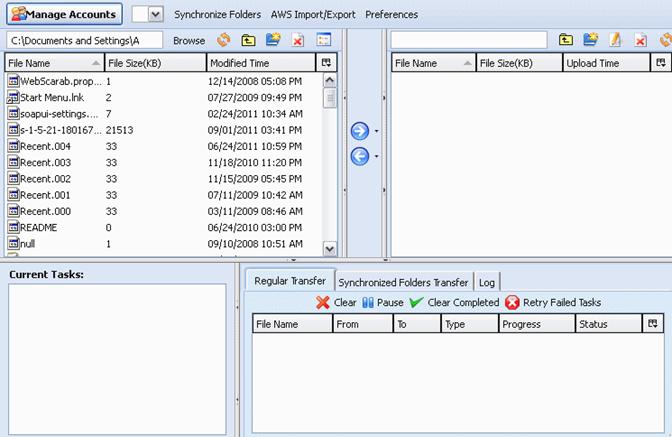
The other popular tool is S3Fox Organizer. S3Fox Organizer is a Firefox extension that enables you to upload and download files to and from your Amazon S3 account. The interface, which opens in a Firefox browser tab, looks very much like a regular FTP client with dual panes. It displays files on your PC on the left, files on S3 on the right, and status messages and information in a panel at the bottom.
Onto The Coding
As stated earlier, AWS is Amazon’s Web service infrastructure that encompasses various cloud services, including S3, EC2, SimpleDB and CloudFront. Integrating these varied services can be a daunting task. Thankfully, we have at our disposal an SDK library in the form of CloudFusion, which enables us to work with AWS effortlessly. CloudFusion is now the official AWS SDK for PHP, and it encompasses most of Amazon’s cloud products: S3, EC2, SimpleDB, CloudFront and many more. For this post, I downloaded the ZIP version of the CloudFusion SDK, but the library is also available as a PEAR package. So, go ahead: download the latest version from the official website, and extract the ZIP to your working directory or to your PHP include path. In the extracted directory, you will find the config-sample.inc.php file, which you should rename to config.inc.php. You will need to make some changes to the file to reflect your AWS credentials.
In the config file, locate the following lines:
define('AWS_KEY', ’);
define('AWS_SECRET_KEY', ’);Modify the lines to mirror your Amazon AWS’ security credentials. You can find the credentials in your Amazon AWS account section, as shown below.
Get the keys, and fill them in on the following lines:
define('AWS_KEY', 'your_access_key_id');
define('AWS_SECRET_KEY', 'your_secret_access_key');You can retrieve your access key and secret key from your Amazon account page:
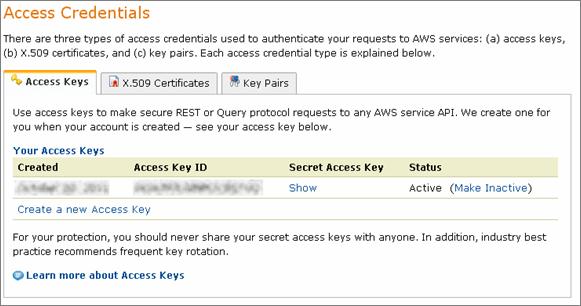
With all of the basic requirements in place, let’s create our first bucket on Amazon S3, with a name of your choice. The following example shows a bucket by the name of com.smashingmagazine.images. (Of course, by the time you read this, this name may have already be taken.) Choose a structure for your bucket’s name that is relevant to your work. For each bucket, you can control access to the bucket, view access logs for the bucket and its objects, and set the geographical region where Amazon S3 will store the bucket and its contents.
/* Include the CloudFusion SDK class */
require_once( ‘sdk-1.4.4/sdk.class.php');
/* Our bucket name */
$bucket = 'com.smashingmagazine.images’;
/* Initialize the class */
$s3 = new AmazonS3();
/* Create a new bucket */
$resource = $s3->create_bucket($bucket, AmazonS3::REGION_US_E1);
/* Check if the bucket was successfully created */
if ($resource->isOK()) {
print("'${bucket}' bucket createdn");
} else {
print("Error creating bucket '${bucket}'n");
}Let’s go over each line in the example above. First, we included the CloudFusion SDK class in our file. You’ll need to adjust the path depending on where you’ve stored the SDK files.
require_once( 'sdk-1.4.4/sdk.class.php');Next, we instantiated the Amazon S3 class:
$s3 = new AmazonS3();In the next step, we created the actual bucket; in this case, com.smashingmagazine.images. Again, your bucket’s name must be unique across all existing bucket names in Amazon S3. One way to ensure this is to prefix a word with your company’s name or domain, as we’ve done here. But this does not guarantee that the name will be available. Nothing prevents anyone from creating a bucket named com.microsoft.apps or com.ibm.images, so choose wisely.
$bucket = 'com.smashingmagazine.images’;
$resource = $s3->create_bucket($bucket, AmazonS3::REGION_US_E1);
To reiterate, bucket names must comply with the following requirements:
- May contain lowercase letters, numbers, periods (
.), underscores (_) and hyphens (-); - Must start with a number or letter;
- Must be between 3 and 255 characters long;
- May not be formatted as an IP address (e.g.
265.255.5.4).
Also, you’ll need to select a geographical location for your bucket. A bucket can be stored in one of several regions. Reasons for choosing one region over another might be to optimize for latency, to minimize costs, or to satisfy regulatory requirements. Many organizations have privacy policies and regulations on where to store data, so consider this when selecting a location. Objects never leave the region they are stored in unless you explicitly transfer them to another region. That is, if your data is stored on servers located in the US, it will never be copied or transferred by Amazon to servers outside of this region; you’ll need to do that manually using the API or AWS tools. In the example above, we have chosen the REGION_US_E1 region.
Here are the permitted values for regions:
AmazonS3::REGION_US_E1AmazonS3::REGION_US_W1AmazonS3::REGION_EU_W1AmazonS3::REGION_APAC_SE1AmazonS3::REGION_APAC_NE1
Finally, we checked whether the bucket was successfully created:
if ($resource->isOK()) {
print("'${bucket}' bucket createdn");
} else {
print("Error creating bucket '${bucket}'n");
}Now, let’s see how to get a list of the buckets we’ve created on S3. So, before proceeding, create a few more buckets to your liking. Once you have a few buckets in your account, it is time to list them.
/* Include the CloudFusion SDK class */
require_once ('sdk-1.4.4/sdk.class.php');
/* Our bucket name */
$bucket = 'com.smashingmagazine.images;
/* Initialize the class */
$s3 = new AmazonS3();
/* Get a list of buckets */
$buckets = $s3->get_bucket_list();
if($buckets) {
foreach ($buckets as $b) {
echo $b . "n";
}
}The only new part in the code above is the following line, which gets an array of bucket names:
$buckets = $s3->get_bucket_list();Finally, we printed out all of our buckets’ names.
if($buckets) {
foreach ($buckets as $b) {
echo $b . "n";
}
}This concludes our overview of creating and listing buckets in our S3 account. We also learned about S3Fox Organizer and the AWS console tools for working with your S3 account.
Uploading Data To Amazon S3
Now that we’ve learned how to create and list buckets in S3, let’s figure out how to put objects into buckets. This is a little complex, and we have a variety of options to choose from. The main method for doing this is create_object. The method takes the following format:
create_object ( $bucket, $filename, [ $opt = null ] )The first parameter is the name of the bucket in which the object will be stored. The second parameter is the name by which the file will be stored on S3. Using only these two parameters is enough to create an empty object with the given file name. For example, the following code would create an empty object named config-empty.inc in the com.magazine.resources bucket:
$s3 = new AmazonS3();
$bucket = 'com.magazine.resources';
$response = $s3->create_object($bucket, 'config-empty.inc');
// Success?
var_dump($response->isOK());
Once the object is created, we can access it using a URL. The URL for the object above would be:
https://s3.amazonaws.com/com.magazine.resources/config-empty.inc
Of course, if you tried to access the URL from a browser, you would be greeted with an “Access denied” message, because objects stored on S3 are set to private by default, viewable only by the owner. You have to explicitly make an object public (more on that later).
To add some content to the object at the time of creation, we can use the following code. This would add the text “Hello World” to the config-empty.inc file.
$response = $s3->create_object($bucket, config-empty.inc ‘,
array(
'body' => Hello World!'
));
As a complete example, the following code would create an object with the name simple.txt, along with some content, and save it in the given bucket. An object may also optionally contain meta data that describes that object.
/* Initialize the class */
$s3 = new AmazonS3();
/* Our bucket name */
$bucket = 'com.magazine.resources’;
$response = $s3->create_object($bucket, 'simple.txt',
array(
'body' => Hello World!'
));
if ($response->isOK())
{
return true;
}You can also upload a file, rather than just a string, as shown below. Although many options are displayed here, most have a default value and may be omitted. More information on the various options can be found in the “AWS SDK for PHP 1.4.7.”
require_once( ‘sdk-1.4.4/sdk.class.php');
$s3 = new AmazonS3();
$bucket = 'com.smashingmagazine.images’;
$response = $s3->create_object($bucket, 'source.php',
array(
'fileUpload' => 'test.php',
'acl' => AmazonS3::ACL_PRIVATE,
'contentType' => 'text/plain',
'storage' => AmazonS3::STORAGE_REDUCED,
'headers' => array( // raw headers
'Cache-Control' => 'max-age',
'Content-Encoding' => 'text/plain',
'Content-Language' => 'en-US',
'Expires' => 'Thu, 01 Dec 1994 16:00:00 GMT',
)
));
// Success?
var_dump($response->isOK());Details on the various options will be explained in the coming sections. For now, take on faith that the above code will correctly upload a file to the S3 server.
Writing Our Amazon S3 WordPress Plugin
With some background on Amazon S3 behind us, it is time to put our learning into practice. We are ready to build a WordPress plugin that will automatically back up our WordPress database to the S3 server and restore it when needed.
To keep the article focused and at a reasonable length, we’ll assume that you’re familiar with WordPress plugin development. If you are a little sketchy on the fundamentals, read “How to Create a WordPress Plugin” to get on track quickly.
The Plugin’s Framework
We’ll first create a skeleton and then gradually fill in the details. To create a plugin, navigate to the wp-content/plugins folder, and create a new folder named s3-backup. In the new folder, create a file named s3-backup.php. Open the file in the editor of your choice, and paste the following header information, which will describe the plugin for WordPress:
/*
Plugin Name: Amazon S3 Backup
Plugin URI: https://cloud-computing-rocks.com
description: >-
Plugin to back up WordPress database to Amazon S3
Version: 1.0
Author: Mr. Sameer
Author URI: https://www.codediesel.com
License: GPL2
*/Once that’s done, go to the plugin’s page in the admin area, and activate the plugin.
Now that we’ve successfully installed a bare-bones WordPress plugin, let’s add the meat and create a complete working system. Before we start writing the code, we should know what the admin page for the plugin will ultimately look like and what tasks the plugin will perform. This will guide us in writing the code. Here is the main settings page for our plugin:
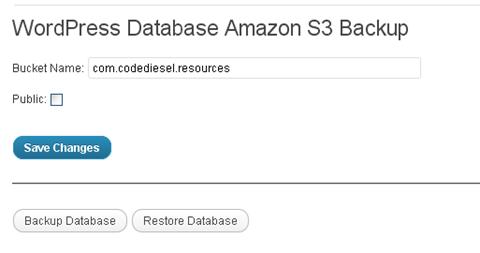
The interface is fairly simple. The primary task of the plugin will be to back up the current WordPress database to an Amazon S3 bucket and to restore the database from the bucket. The settings page will also have a function for naming the bucket in which the backup will be stored. Also, we can specify whether the backup will be available to the public or accessible only to you.
Below is a complete outline of the plugin’s code. We will elaborate on each section in turn.
/*
Plugin Name: Amazon S3 Backup
Plugin URI: https://cloud-computing-rocks.com
description: >-
Plugin to back up WordPress database to Amazon S3
Version: 1.0
Author: Mr. Sameer
Author URI: https://www.codediesel.com
License: GPL2
*/
$plugin_path = WP_PLUGIN_DIR . "/" . dirname(plugin_basename(__FILE__));
/* CloudFusion SDK */
require_once($plugin_path . '/sdk-1.4.4/sdk.class.php');
/* WordPress ZIP support library */
require_once(ABSPATH . '/wp-admin/includes/class-pclzip.php');
add_action('admin_menu', 'add_settings_page');
/* Save or Restore Database backup */
if(isset($_POST['aws-s3-backup'])) {
…
}
/* Generic Message display */
function showMessage($message, $errormsg = false) {
…
}
/* Back up WordPress database to an Amazon S3 bucket */
function backup_to_AmazonS3() {
…
}
/* Restore WordPress backup from an Amazon S3 bucket */
function restore_from_AmazonS3() {
…
}
function add_settings_page() {
…
}
function draw_settings_page() {
…
}
Here is the directory structure that our plugin will use:
plugins (WordPress plugin directory)
---s3-backup (our plugin directory)
-------s3backup (restored backup will be stored in this directory)
-------sdk-1.4.4 (CloudFusion SDK directory)
-------s3-backup.php (our plugin source code)
Let’s start coding the plugin. First, we’ll initialize some variables for paths and include the CloudFusion SDK. A WordPress database can get large, so to conserve space and bandwidth, the plugin will need to compress the database before uploading it to the S3 server. To do this, we will use the class-pclzip.php ZIP compression support library, which is built into WordPress. Finally, we’ll hook the settings page to the admin menu.
$plugin_path = WP_PLUGIN_DIR . "/" . dirname(plugin_basename(__FILE__));
/* CloudFusion SDK */
require_once($plugin_path . '/sdk-1.4.4/sdk.class.php');
/* WordPress ZIP support library */
require_once(ABSPATH . '/wp-admin/includes/class-pclzip.php');
/* Create the admin settings page for our plugin */
add_action('admin_menu', 'add_settings_page');
Every WordPress plugin must have its own settings page. Ours is a simple one, with a few buttons and fields. The following is the code for it, which will handle the mundane work of saving the bucket’s name, displaying the buttons, etc.
function draw_settings_page() {
?>
<div class="wrap">
<h2><?php echo('WordPress Database Amazon S3 Backup') ?></h2>
<form method="post" action="options.php">
<input type="hidden" name="action" value="update" />
<input type="hidden" name="page_options" value="aws-s3-access-public, aws-s3-access-bucket" />
<?php
wp_nonce_field('update-options');
$access_options = get_option('aws-s3-access-public');
?>
<p>
<?php echo('Bucket Name:') ?>
<input type="text" name="aws-s3-access-bucket" size="64" value="<?php echo get_option('aws-s3-access-bucket'); ?>" />
</p>
<p>
<?php echo('Public:') ?>
<input type="checkbox" name="aws-s3-access-public" <?php checked(1 == $access_options); ?> value="1" />
</p>
<p class="submit">
<input type="submit" class="button-primary" name="Submit" value="<?php echo('Save Changes') ?>" />
</p>
</form>
<hr />
<form method="post" action="">
<p class="submit">
<input type="submit" name="aws-s3-backup" value="<?php echo('Backup Database') ?>" />
<input type="submit" name="aws-s3-restore" value="<?php echo('Restore Database') ?>" />
</p>
</form>
</div>
<?php
}
Setting up the base framework is essential if the plugin is to work correctly. So, double-check your work before proceeding.
Database Upload
Next is the main part of the plugin, its raison d’être: the function for backing up the database to the S3 bucket.
/* Back up WordPress database to an Amazon S3 bucket */
function backup_to_AmazonS3()
{
global $wpdb, $plugin_path;
/* Backup file name */
$backup_zip_file = 'aws-s3-database-backup.zip';
/* Temporary directory and file name where the backup file will be stored */
$backup_file = $plugin_path . "/s3backup/aws-s3-database-backup.sql";
/* Complete path to the compressed backup file */
$backup_compressed = $plugin_path . "/s3backup/" . $backup_zip_file;
$tables = $wpdb->get_col("SHOW TABLES LIKE '" . $wpdb->prefix . "%'");
$result = shell_exec('mysqldump --single-transaction -h ' .
DB_HOST . ' -u ' . DB_USER . ' --password="' .
DB_PASSWORD . '" ' .
DB_NAME . ' ' . implode(' ', $tables) . ' > ' .
$backup_file);
$backups[] = $backup_file;
/* Create a ZIP file of the SQL backup */
$zip = new PclZip($backup_compressed);
$zip->create($backups);
/* Connect to Amazon S3 to upload the ZIP */
$s3 = new AmazonS3();
$bucket = get_option('aws-s3-access-bucket');
/* Check if a bucket name is specified */
if(empty($bucket)) {
showMessage("No Bucket specified!", true);
return;
}
/* Set backup public options */
$access_options = get_option('aws-s3-access-public');
if($access_options) {
$access = AmazonS3::ACL_PUBLIC;
} else {
$access = AmazonS3::ACL_PRIVATE;
}
/* Upload the database itself */
$response = $s3->create_object($bucket, $backup_zip_file,
array(
'fileUpload' => $backup_compressed,
'acl' => $access,
'contentType' => 'application/zip',
'encryption' => 'AES256',
'storage' => AmazonS3::STORAGE_REDUCED,
'headers' => array( // raw headers
'Cache-Control' => 'max-age',
'Content-Encoding' => 'application/zip',
'Content-Language' => 'en-US',
'Expires' => 'Thu, 01 Dec 1994 16:00:00 GMT',
)
));
if($response->isOK()) {
unlink($backup_compressed);
unlink($backup_file);
showMessage("Database successfully backed up to Amazon S3.");
} else {
showMessage("Error connecting to Amazon S3", true);
}
}The code is self-explanatory, but some sections need a bit of explanation. Because we want to back up the complete WordPress database, we need to somehow get ahold of the MySQL dump file for the database. There are multiple ways to do this: by using MySQL queries within WordPress to save all tables and rows of the database, or by dropping down to the shell and using mysqldump. We will use the second method. The code for the database dump shown below uses the shell_exec function to run the mysqldump command to grab the WordPress database dump. The dump is further saved to the aws-s3-database-backup.sql file.
$tables = $wpdb->get_col("SHOW TABLES LIKE '" . $wpdb->prefix . "%'");
$result = shell_exec('mysqldump --single-transaction -h ' .
DB_HOST . ' -u ' . DB_USER .
' --password="' . DB_PASSWORD . '" ' .
DB_NAME . ' ' . implode(' ', $tables) .
' > ' . $backup_file);
$backups[] = $backup_file;
The SQL dump will obviously be big on most installations, so we’ll need to compress it before uploading it to S3 to conserve space and bandwidth. We’ll use WordPress’ built-in ZIP functions for the task. The PclZip class is stored in the /wp-admin/includes/class-pclzip.php file, which we have included at the start of the plugin. The aws-s3-database-backup.zip file is the final ZIP file that will be uploaded to the S3 bucket. The following lines will create the required ZIP file.
/* Create a ZIP file of the SQL backup */
$zip = new PclZip($backup_compressed);
$zip->create($backups);The PclZip constructor takes a file name as an input parameter; aws-s3-database-backup.zip, in this case. And to the create method we pass an array of files that we want to compress; we have only one file to compress, aws-s3-database-backup.sql.
Now that we’ve taken care of the database, let’s move on to the security. As mentioned in the introduction, objects stored on S3 can be set as private (viewable only by the owner) or public (viewable by everyone). We set this option using the following code.
/* Set backup public options */
$access_options = get_option('aws-s3-access-public');
if($access_options) {
$access = AmazonS3::ACL_PUBLIC;
} else {
$access = AmazonS3::ACL_PRIVATE;
}We have listed only two options for access (AmazonS3::ACL_PUBLIC and AmazonS3::ACL_PRIVATE), but there are a couple more, as listed below and the details of which you can find in the Amazon SDK documentation.
AmazonS3::ACL_PRIVATEAmazonS3::ACL_PUBLICAmazonS3::ACL_OPENAmazonS3::ACL_AUTH_READAmazonS3::ACL_OWNER_READAmazonS3::ACL_OWNER_FULL_CONTROL
Now on to the main code that does the actual work of uploading. This could have been complex, but the CloudFusion SDK makes it easy. We use the create_object method of the S3 class to perform the upload. We got a short glimpse of the method in the last section.
/* Upload the database itself */
$response = $s3->create_object($bucket, $backup_zip_file, array(
'fileUpload' => $backup_compressed,
'acl' => $access,
'contentType' => 'application/zip',
'encryption' => 'AES256',
'storage' => AmazonS3::STORAGE_REDUCED,
'headers' => array( // raw headers
'Cache-Control' => 'max-age',
'Content-Encoding' => 'application/zip',
'Content-Language' => 'en-US',
'Expires' => 'Thu, 01 Dec 1994 16:00:00 GMT',
)
));
/* Restore WordPress backup from an Amazon S3 bucket */
function restore_from_AmazonS3()
{
global $plugin_path;
/* Backup file name */
$backup_zip_file = 'aws-s3-database-backup.zip';
/* Complete path to the compressed backup file */
$backup_compressed = $plugin_path . "/s3backup/" . $backup_zip_file;
$s3 = new AmazonS3();
$bucket = get_option('aws-s3-access-bucket');
if(empty($bucket)) {
showMessage("No Bucket specified!", true);
return;
}
$response = $s3->get_object($bucket, $backup_zip_file, array(
'fileDownload' => $backup_compressed
));
if($response->isOK()) {
showMessage("Database successfully restored from Amazon S3.");
} else {
showMessage("Error connecting to Amazon S3", true);
}
}As you can see, the code for restoring is much simpler than the code for uploading. The function uses the get_object method of the SDK, the definition of which is as follows:
get_object ( $bucket, $filename, [ $opt = null ] )The details of the method’s parameters are enumerated below:
$bucketThe name of the bucket where the backup file is stored. The bucket’s name is stored in our WordPress settings variableaws-s3-access-bucket, which we retrieve using theget_option('aws-s3-access-bucket')function.$backup_zip_fileThe file name of the backup object. In our case,aws-s3-database-backup.zip.'fileDownload' => $backup_compressedThe file system location to download the file to, or an open file resource. In our case, thes3backupdirectory in our plugin folder. It must be a server-writable location.
At the end of the function, we check whether the download was successful and inform the user.
In addition to the above functions, there are some miscellaneous support functions. One is for displaying a message to the user:
/* Generic message display */
function showMessage($message, $errormsg = false) {
if ($errormsg) {
echo '<div id="message" class="error">';
} else {
echo '<div id="message" class="updated">';
}
echo "<p><strong>$message</strong></p></div>";
}Another is to add a hook for the settings page to the admin section.
function add_settings_page() {
add_options_page('Amazon S3 Backup', 'Amazon S3 Backup',8,
's3-backup', 'draw_settings_page');
}
The button commands for backing up and restoring are handled by this simple code:
/* Save or Restore Database backup */
if(isset($_POST['aws-s3-backup'])) {
backup_to_AmazonS3();
} elseif(isset($_POST['aws-s3-restore'])) {
restore_from_AmazonS3();
}This rounds out our tutorial on creating a plugin to integrate Amazon S3 with WordPress. Although we could have added more features to the plugin, the functionality was kept bare to maintain focus on Amazon S3’s basics, rather then on the calisthenics of plugin development.
In Conclusion
This has been a relatively long article, the aim of which was to acquaint you with Amazon S3 and how to use it in your PHP applications. Together, we’ve developed a WordPress plugin to back up our WordPress database to the S3 cloud and to retrieve it when needed. To reiterate, S3 is a complex service with many features and functions, which we have not covered here due to space considerations. Perhaps in future articles we’ll elaborate on the other features of S3 and add more features to the plugin we developed here.
Further Reading on SmashingMag:
- The Ultimate Guide To Choosing A WordPress Host
- Moving A WordPress Website Without Hassle
- How To Speed Up Your WordPress Website
- Don’t Get Crushed By The Load: Optimization Techniques


