CSS-Driven Internationalization In JavaScript

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.


 Celebrating 10 million developers
Celebrating 10 million developers Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.

Writing front-end code often requires developers to address the problem of internationalization at some level. Despite the current standard, which introduces a bunch of new tags, simply adding support for different languages in a JavaScript plugin is still complicated. As a result, for any new project, you have to build a solution from scratch or adapt various existing APIs from other plugins that you use.
In this article, I’ll describe my approach with better-dom to solve the internationalization problem. Since the last article about this, “Writing a Better JavaScript Library for the DOM,” I’ve revisited the concept to solve the issues raised through feedback.
The solution was originally intended to be a set of internationalization APIs for plugins, extensions, etc. It doesn’t rely heavily on the better-dom library, so it could be adapted to any existing JavaScript library.
A Typical Solution To The Problem
Different APIs exist for changing languages in JavaScript. Most of them contain three main functions:
- The first function registers a localized string by key and language.
- The second sets a localized string for a particular element.
- The third is used to change the current language.
Let’s look at an example based on the Validator plugin from the jQuery Tools library. The plugin supports the localization of validation errors via JavaScript. Default error messages are stored in the $.tools.validator.messages object.
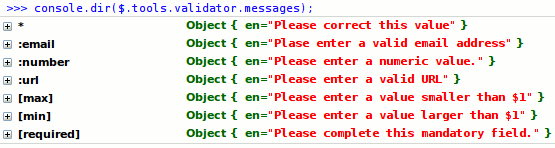
$.tools.validator.messages object. (View large version)For keys, the plugin uses CSS selectors (to simplify the code). If you want to provide error messages in other languages, you would use the $.tools.validator.localize method, as follows:
$.tools.validator.localize("fi", {
":email" : "Virheellinen sähköpostiosoite",
":number" : "Arvon on oltava numeerinen",
"[max]" : "Arvon on oltava pienempi, kuin $1",
"[min]" : "Arvon on oltava suurempi, kuin $1",
"[required]" : "Kentän arvo on annettava"
});
This method populates for Finnish localization. The $.tools.validator.messages object would look like this:
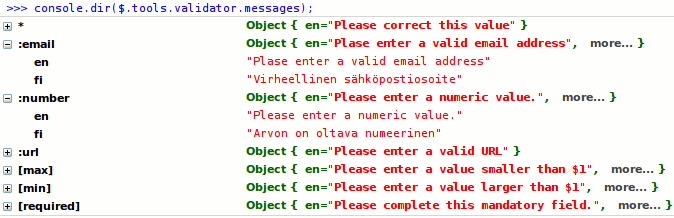
$.tools.validator.messages object populated for Finnish localization (View large version)Now, if you want to use the Finnish localization in your form, then you need to change the default language (English) via the lang configuration option:
$("#myForm").validator({lang: "fi"});
The plugin implements the typical solution that we have at present. Having looked at approaches similar to this one, I found several common shortcomings:
- Obtrusive You have to add a JavaScript function call if the current page’s language is different from the default (usually English) used in a plugin.
- Ineffective To change a language dynamically, you have to call a particular function and then touch the DOM of every related element to update the
innerHTML, depending on the new language. - Hard to maintain Every plugin has its own set of APIs.
The first shortcoming is the most critical. If your project has a lot of components, switching to the non-default language on initial page load for every plugin will be painful. If the project fetches data using AJAX calls, then the same steps would have to be done for future content as well. Let’s try to solve all of these shortcomings. First, we need to go through the technical stuff.
The :lang Pseudo-Class
Remember the :lang pseudo-class from CSS2? It’s rarely used, but when I first read about it in the specification, I was curious what the standard’s authors intended to solve with it:
"If the document language specifies how the human language of an element is determined, it is possible to write selectors in CSS that match an element based on its language."
A typical example cited in the specification is the symbol for quotations. The symbol varies between languages. To address this for the <q> element (which marks up a short quotation, usually wrapped in quotation marks), we can use the :lang pseudo-class:
:lang(fr) > q { quotes: '« ' ' »' }
:lang(de) > q { quotes: '»' '«' '\2039' '\203A' }
An important difference between the :lang pseudo-class and a simple attribute selector like [lang=fr] is that the latter matches only elements that have the lang attribute. Therefore, the :lang pseudo-class is always safer than the attribute variant because it works properly even if the :lang attribute has not been set on an element.
The example above illustrates how to change the representation of content according to the current language using CSS. This is important because it enables us to put the logic related to changing the language into CSS.
The example of the symbol for quotation marks is nice, but it addresses a small number of cases and so can’t be used in typical scenarios — ordinary strings are usually very different in different languages. We need a trick that allows us to change an element’s content completely.
Changing An Element’s Content With CSS
Browsers that support the CSS2 specification introduced pseudo-elements, which, rather than describing a particular state like pseudo-classes, enable us to style certain parts of a document.
Note that Internet Explorer 8 has a known issue in its implementation in that it does not support the double-colon syntax for defining pseudo-elements. The problem was fixed in Internet Explorer 9, so if you need to support version 8, make sure to use the single-colon syntax for any pseudo-element.
The real gems are ::before and ::after, which enable you to add extra content before or after an element’s innerHTML. They might look simple, but they have a ton of use cases that solve problems in a very clean way.
Let’s start with the basics. Both ::before and ::after introduce a CSS property, content. This new property defines what content to prepend or append to an element’s innerHTML. The value of the content attribute may be any of the following:
- text string (but not an HTML string),
- image,
- counter,
- attribute value(s).
Our main interest is adding a text string. Imagine we have CSS like this:
#hello::before {
content: "Hello ";
}
If the element with the ID of hello contains the string world, then the browser would display Hello world.
<p id="hello">world</p>
We could rewrite our CSS using the attr function:
#hello::before {
content: attr(id) " ";
}
Then, the element would display hello world in lowercase, because the id attribute has a lowercased string value.
Now, imagine that the hello element didn’t have any inner content. We could change its representation completely using CSS. This becomes handy when we use the trick in combination with the :lang pseudo-class:
#hello::before {
content: "Hello";
}
#hello:lang(de)::before {
content: "Hallo";
}
#hello:lang(ru)::before {
content: "Привет";
}
Our element hello will now change according to the current web page’s language — no need to call any function to change its representation according to the current web page’s language. The localization is handled by the value of the lang attribute on the <html> element and several extra CSS rules. This is what I call CSS-driven internationalization.
CSS-Driven Internationalization: Improved!
Since publishing the original idea, I’ve heard several people complain that those rules could add a lot of CSS. Because my initial goal was to use it for small JavaScript plugins, I didn’t even think it could be used widely on the page. However, the philosophy of CSS is to contain the presentation logic, and I was trying to use it to store various multilingual strings, which actually belong to the web page’s content. It didn’t seem right.
After some thinking, I developed an improved version that solves this issue. Instead of putting text strings into CSS, I use the attr function to read a language-specific data-i18n-* attribute that contains a localized string. This restricts the number of CSS rules we can add: one rule per new language.
Let’s rewrite the localization of the hello element above with this improved method. This time, let’s give our web page some global CSS to support German and Russian, in addition to English:
/* English (default language)*/
[data-i18n]::before {
content: attr(data-i18n);
}
/* German */
[data-i18n-de]:lang(de)::before {
content: attr(data-i18n-de);
}
/* Russian */
[data-i18n-ru]:lang(ru)::before {
content: attr(data-i18n-ru);
}
Note that the code above doesn’t contain any string constant: The CSS rules are generic.
Now, instead of putting localized text strings into CSS, let’s add several custom language-specific data-* attributes that contain the appropriate values. Our hello element should look like the following, which will display different content according to the current web page’s language:
<p id="hello" data-18n="Hello" data-i18n-de="Hallo" data-i18n-ru="Привет"><p>
That’s it! We’re left with minimal extra CSS, which describes only the global logic for changing an element’s representation according to the current language, and our localized strings are fully HTML.
Building A High-Level API
In better-dom, there are two functions to support CSS-driven internationalization: $Element.prototype.i18n and DOM.importStrings. The first function changes the localized string for a particular element. To keep it simple, I usually use the English strings as keys and default values. It makes the JavaScript more readable and easier to understand. For instance:
myelement.i18n("Hello");
This sets a localized Hello string as the inner content of myelement, where myelement is an instance of the $Element class, which happens to be a wrapper type for a native DOM element in better-dom. The line above does several things behind the scenes:
- It determines the current set of registered languages.
- For each language, it reads a string with the key
Helloin the internal storage of registered localizations, and it uses the value to set an appropriatedata-i18n-*attribute for the element. - It cleans up the element’s
innerHTMLto prevent a weird result from displaying.
You can see the source code of $Element.prototype.i18n on GitHub. The goal of this i18n method is to update our custom language-specific data-* attributes. For example:
<p id="hello"><p>
After the call, this empty element would become the following, if we have registered all of the localized strings for German and Russian:
<p id="hello" data-i18n="Hello" data-i18n-de="Hallo" data-i18n-ru="Привет"><p>
Additionally, the i18n method supports an optional second argument, a key-value map of the variables:
// Use {varName} in the string template to define
// various parts of a localized string.
myelement.i18n("Hello {user}", {user: username});
// Use array and {varNumber} to define a numeric
// set of variables.
myelement.i18n("Hello {0}", [username]);
To register a localized string, use the static method DOM.importStrings to pass three arguments:
- the target language,
- the localized string key (usually just an English string),
- the localized string value.
For the example above, before invoking the i18n method, we would need to make the following calls:
DOM.importStrings("de", "Hello {user}", "Hallo {user}");
DOM.importStrings("ru", "Hello {user}", "Привет {user}");
DOM.importStrings("de", "Hello {0}", "Hallo {0}");
DOM.importStrings("ru", "Hello {0}", "Привет {0}")
Behind the scenes, DOM.importStrings is going through a couple of steps. First, it checks whether the target language has been registered. If not, it adds a global CSS rule:
[data-i18n-{lang}]:lang({lang})::before {
content: attr(data-i18n-{lang});
}
Then, it saves a localized string, the key-value pair, in internal storage. You can see the source code of DOM.importStrings on GitHub.
With DOM.importStrings, we can also override existing English strings. This could be useful if you need to adapt strings to your needs without changing the source code:
DOM.importStrings("en", "Hello {user}", "Hey {user}");
DOM.importStrings("en", "Hello {0}", "Hey {0}");
As you can see, these helpers free us from having to write boilerplate code and enable us to use CSS-driven internationalization on our web pages very easily.
Advantages Of CSS-Driven Internationalization
Let’s review the list of issues identified in the first part of the article.
Is It Unobtrusive?
With the original solution, we said you had to add a JavaScript function call if the current page’s language was different from the default (usually English) used in the plugin. A big advantage of CSS-driven internationalization is that it uses the :lang pseudo-class to switch to the target language. This means that having an appropriate value of the lang attribute on the <html> element is enough to choose the localized string that you need.
Therefore, with CSS-driven internationalization, you do not need to make any calls on page load, even if the web page’s language is different from the default language. So, it’s unobtrusive.
Is It Effective?
To change a language dynamically, you had to call a particular function and then touch the DOM of every related element to update the innerHTML, depending on the new language. Now, the representation of an element is handled by the ::before pseudo-element. To switch to another language dynamically at a global level, just change the lang attribute of the <html> element (using native APIs, for example). Or, to localize the language change, just change the lang attribute of a particular subtree.
Also, you don’t need to update the innerHTML of all related elements in order to change the current language dynamically. This is handled by CSS. So, our code is now more effective.
Is It Easy To Maintain?
Every plugin originally had to have its own set of APIs. A robust solution for internationalization should be a part of every serious library that touches the DOM. CSS-driven internationalization has been a part of my better-dom project since the beginning because I had to address this problem. I used it in better-form-validation to customize the form-validation tooltips. Later, I used it in better-dateinput-polyfill and better-prettydate. Having APIs for internationalization built into the core library reduces my boilerplate code and makes it more consistent, stabler and — you guessed it — easier to maintain.
Limitations Of CSS-Driven Internationalization
What about cons of CSS-driven internationalization?
JavaScript
First, the solution depends on JavaScript. Putting localized strings into data-* attributes on static web pages isn’t a good idea because the markup would look weird, semantically speaking. Therefore, I’d recommend using a set of JavaScript APIs (like what’s described above) to make the concept workable.
Make sure to use it in parts of your pages that are not critical to SEO, because search engine crawlers will find the resulting markup difficult to index correctly. Remember that this solution was originally developed as a set of localization APIs for JavaScript plugins and extensions.
Pseudo-Elements
Some limitations also come from using the ::before and ::after pseudo-elements:
- The
contentproperty does not work on empty elements or on certain form elements, including<input>and<select>. - The
contentproperty cannot display HTML tags. - There is no way to localize the values of an HTML element’s attributes (such as
placeholderandtitle).
As for the first limitation, the lack of support for empty elements is not a big problem. The elements do not contain any content, so there is nothing to localize. But the problem became real when I was working with the <input> element in better-dateinput-polyfill. To solve this, I hid the original element and added an extra <span> element as a wrapper that contained the localized string I needed to display. Not very elegant, but it worked.
The second and third limitations are easier to avoid for now. I have some ideas on how to solve them, but I don’t have use cases for them. An elegant solution is welcome, of course.
Solving Accessibility Problems
Update (24.06.2014): Several people have noted in the comments section below that using pseudo-elements to display localized strings has important accessibility problems. The first problem is that a content, generated via ::before and ::after is not selectable via mouse. The second is that such content is completely missed by screen readers. Therefore, I’ve improved the concept to address these issues and invite you to check out the demo. It is not part of better-dom APIs yet, but it will be added in the nearest version.
The main difference is that instead of the pseudo-elements, the content is displayed inside of language-specific <span> elements. It is not possible to have several <span>s to be displayed at the same time because <span>s for non-current language are hidden via the display:none rule. Screen readers skip such hidden elements which is what we need exactly.
Using inner <span>s instead of pseudo-elements also fixes text selection via mouse and lack of being able to use HTML tags inside of localized strings. Nevertheless, problems with form elements and localization of attribute values still exist in the present.
Conclusion
Hopefully, a simple solution to the problem of internationalization in JavaScript will be added to the specification soon. Until then, we front-end developers will have to reinvent the wheel or adapt each other’s wheels.
While building this CSS-driven internationalization solution, I was actually inspired by ideas contained in the CSS2 specification itself. Maybe the authors already had it in mind. Who knows?
After several iterations, the solution solidified. Sure, it still has limitations. Yet its advantages, like being fully unobtrusive, will make your code substantially cleaner and easier to maintain. Hopefully, this article has helped you to understand what I did behind the scenes to achieve that.
Feel free to share your thoughts on the better-dom library GitHub or in the comments section below.
Front page image credits: Dmitry Baranovskiy.
Further Reading
- Don’t Get Lost In Translation: How To Conduct Website Localization
- Should You Ask The User Or Their Browser?
- 12 Commandments Of Software Localization
- Building Web Layouts For Dual-Screen And Foldable Devices


