A GraphQL Primer: Why We Need A New Kind Of API (Part 1)

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.


 Celebrating 10 million developers
Celebrating 10 million developers
In this series, I want to introduce you to GraphQL. By the end, you should understand not just what it is but also its origins, its drawbacks and the basics of how to work with it. In this first article, rather than jumping into the implementation, I want to go over how and why we have arrived at GraphQL (and similar tools) by looking at the lessons learned from the last 60 years of API development, from RPC to now. After all, as Mark Twain colorfully described, there are no new ideas.
"There is no such thing as a new idea. It is impossible. We simply take a lot of old ideas and put them into a sort of mental kaleidoscope."
— Mark Twain in "Mark Twain's Own Autobiography: The Chapters From The North American Review"
But first, I have to address the elephant in the room. New things are always exciting, but they can also feel exhausting. You may have heard about GraphQL and just thought to yourself: “Why…😩” Alternatively, maybe you thought something more like, “Why do I care about a new API design trend? REST is… fine.” These are legitimate questions so let me help explain why you should pay attention to this one.
Introduction
The benefits of bringing new tools to your team have to be weighed against its costs. There are lots of things to measure. There is the time it takes to learn, the time converting takes away from feature development, the overhead of maintaining two systems. With such high costs, any new tech has to be better, faster, or more productive by a huge amount. Incremental improvements, while exciting, just aren’t worth the investment. The types of APIs I want to talk about, GraphQL in particular, are in my opinion a huge step forward and deliver more than enough benefit to justify the cost.
Rather than exploring features first, it is helpful to put them into context and to understand how they came to exist. To do this, I am going to start with a bit of a recap of the history of APIs.
RPC
RPC was, arguably the first major API pattern and its origins go all the way back to early computing in the mid-60s. At the time, computers were still so big and expensive that the notion of API driven application development, as we think of it, was mostly just theoretical. Constraints like bandwidth/latency, computation power, shared compute time and physical proximity forced engineers to think in terms of distributed systems rather than of services that expose data. From ARPANET in the 60s, all the way up into the mid-90s with things like CORBA and Java’s RMI, most computers interacted with each other using Remote Procedure Calls (RPC) which is a client-server interaction model where a client causes a procedure (or method) to execute on a remote server.
There are a lot of nice things about RPC. Its main principle is allowing a developer to treat code in a remote environment as if it were in a local one, albeit a lot slower and less reliable which creates continuity in otherwise distinct and disparate systems. Like many things that came out ARPANET, it was ahead of its time since this type of continuity is something we still strive for when working with unreliable and asynchronous actions like DB access and external service calls.
Over the decades, there has been an enormous amount of research into how to allow developers to embed asynchronous behavior like this into the typical flow of a program; had there been things like Promises, Futures and ScheduledTasks available at the time, it is possible that our API landscape would look different.
Another great thing about RPC is that since it is unconstrained by the structure of data, highly specialized methods can be written for clients that request and retrieve exactly the information needed which can result in minimal network overhead and smaller payloads.
There are, however, things that make RPC difficult. First, continuity requires context. RPC, by design, creates quite a lot of coupling between local and remote systems — you lose the boundaries between your local and your remote code. For some domains, this is okay or even preferred like in client SDKs, but for APIs where client code is not well understood, it can be considerably less flexible than something more data-oriented.
More important though, is the potential for proliferation of API methods. In theory, an RPC service exposes a small thoughtful API that can handle any task. In practice, a huge number of external endpoints can accrete without much structure. It takes a tremendous amount of discipline to prevent overlapping APIs and duplication over time as team members come and go and projects pivot.
It is true that with proper tooling and documentation changes, like the ones I mentioned, can be managed but in my time writing software I have come across a scant few auto-documenting and disciplined services so, to me, this is a bit of a red herring.
SOAP
The next major API type to come along was SOAP, which was born in the late 90s at Microsoft Research. SOAP (Simple Object Access Protocol) is an ambitious protocol spec for XML based communication between applications. SOAP’s stated ambition was to address some of the practical drawbacks of RPC, XML-RPC in particular, by creating a well-structured foundation for complex web services. In effect, this just meant adding a behavioral type system to XML. Sadly, it created more impediments than it solved as evidenced by the fact that very few new SOAP endpoints are written today.
"SOAP is what most people would consider a moderate success."
— Don Box
SOAP did have some good things going for it despite its unbearable verbosity and terrible names. The enforceable contracts in the WSDL and WADL (pronounced “wizdle” and “waddle”) between the client and server guaranteed predictable, type-safe results, and the WSDL could be used to generate documentation or to create integrations with IDEs and other tools.
The big revelation of SOAP regarding API evolution was its gradual and possibly unintentional introduction of more resource-oriented calls. SOAP endpoints allow you to request data with a predetermined structure rather than think about the methods required to generate the data (assuming it is written this way).
The most significant downside of SOAP is that being so verbose; it is nearly impossible to use without lots of tooling. You need tooling to write tests, tooling to inspect responses from a server and tooling to parse all of the data. Many older systems still use SOAP, but the requirement of tooling makes it too cumbersome for most new projects, and the number of bytes needed for the XML structure makes it a poor choice for serving mobile devices or chatty distributed systems.
For more information, it’s worth reading the SOAP spec as well as the surprisingly interesting history of SOAP from Don Box, one of the original team members.
REST
Finally, we have come to the API design pattern du jour: REST. REST, introduced in a doctoral dissertation by Roy Fielding in 2000, swung the pendulum in a fully different direction. REST is, in many ways, the antithesis of SOAP and looking at them side by side makes you feel like his dissertation was a bit of a rage quit.
SOAP uses HTTP as a dumb transport and builds its structure in the request and response body. REST, on the other hand, throws out the client-server contracts, tooling, XML and bespoke headers, replacing them with HTTPs semantics as it is structure choosing instead to use HTTP verbs interact with data and URIs that reference a resource in some hierarchy of data.
| SOAP | REST | |
|---|---|---|
| HTTP Verbs | 🙅 | GET, PUT, POST, PATCH, DELETE |
| Data Format | XML | Whatever you want |
| Client/Server Contracts | All day ‘ery day! | Who needs those |
| Type System | ✔ | JavaScript has unsigned short right? |
| URLs | Describe operations | Named resources |
REST completely and explicitly changes API design from modeling interactions to simply modeling the data of a domain. Being fully resource-oriented when working with a REST API you no longer need to know, or care, what it takes to retrieve a given piece of data; nor are you required to know anything about the implementation of the backend services.
Not only was the simplicity a boon for developers but since URLs represent stable information it is easily cacheable, its statelessness makes it easy to scale horizontally and, since it models the data rather than anticipating consumers needs, it can dramatically reduce the surface area of APIs.
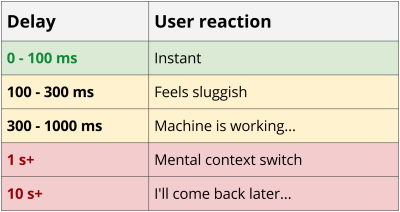
REST is great, and its ubiquity is an astonishing success but, like all solutions that came before it, REST is not without its flaws. To talk concretely about some of its shortcomings let’s go over a basic example. Let’s pretend that we have to build the landing page of a blog which displays a list of blog posts and their author’s name.
Let’s write the code that can retrieve the homepage data from a plain REST API. We will start with a few functions that wrap our resources.
const getPosts = () => fetch(`${API_ROOT}/posts`);
const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`);
const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);
Now, let’s orchestrate!
const getPostWithAuthor = postId => {
return getPost(postId)
.then(post => getAuthor(post.author))
.then(author => {
return Object.assign({}, post, { author })
})
};
const getHomePageData = () => {
return getPosts()
.then(postIds => {
const postDetails = postIds.map(getPostWithAuthor);
return Promise.all(postDetails);
})
};
So our code will do the following:
- Fetch all Posts;
- Fetch the details about each Post;
- Fetch Author resource for each Post.
The nice thing is that this is pretty easy to reason about, well organized and the conceptual boundaries of each resource are well drawn. The bummer here is that we just made eight network requests, many of which happen in serial.
GET /posts
GET /posts/234
GET /posts/456
GET /posts/17
GET /posts/156
GET /author/9
GET /author/4
GET /author/7
GET /author/2
Yes, you could criticize this example by suggesting that the API could have a paginated /posts endpoint but that is splitting hairs. The fact remains that you often have a collection of API calls to make that depend on each other to render a complete application or page.
Developing REST clients and servers is certainly better than what came before it, or at least more idiot proof, but a lot has changed in the two decades since Fielding’s paper. At the time, all computers were beige plastic; now they are aluminum! Seriously though, 2000 was near the peak of the explosion in personal computing. Every year processors were doubling in speed, and networks were getting faster at an incredible rate. Market penetration of internet was around 45% with nowhere to go but up.
Then, around 2008, mobile computing went mainstream. With mobile, we effectively regressed a decade in terms of speed/performance overnight. In 2017, we have nearly 80% domestic and over 50% global smartphone penetration, and it is the time to rethink some of our assumptions about API design.
REST’s Weaknesses
The following is a critical look at REST from the perspective of a client application developer, particularly one working in mobile. GraphQL and GraphQL-style APIs are not new and do not solve problems that are outside of the grasp of REST developers. GraphQL’s most significant contribution is its ability to solve these problems systematically and with a level of integration that is not readily available elsewhere. In other words, it is a “batteries included” solution.
The primary authors of REST, including Fielding, published a paper in late 2017 (Reflections on the REST Architectural Style and “Principled Design of the Modern Web Architecture”) reflecting on two decades of REST and the many patterns that it has inspired. It is short and absolutely worth the read for anybody interested in API design.
With some historical context and a reference app, let’s look at REST’s three main weaknesses.
REST Is Chatty
REST services tend to be at least somewhat “chatty” since it takes multiple round trips between client and server to get enough data to render an application. This cascade of requests has devastating performance impacts, especially on mobile. Going back to the blog example, even in a best-case scenario with a new phone and reliable network with a 4G connection you have spent almost .5s on just latency overhead before the first byte of data is downloaded.
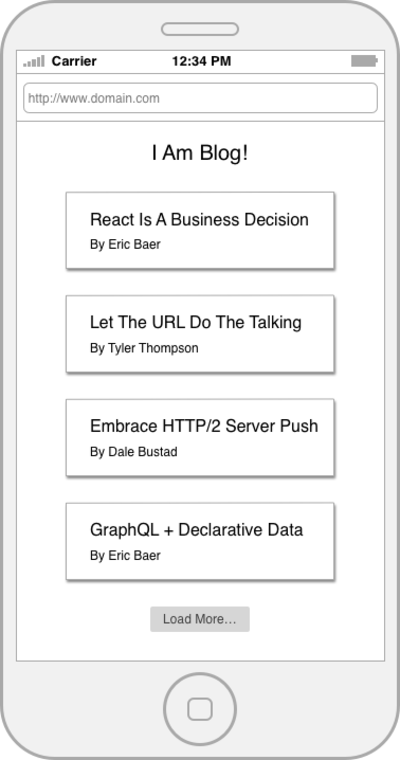
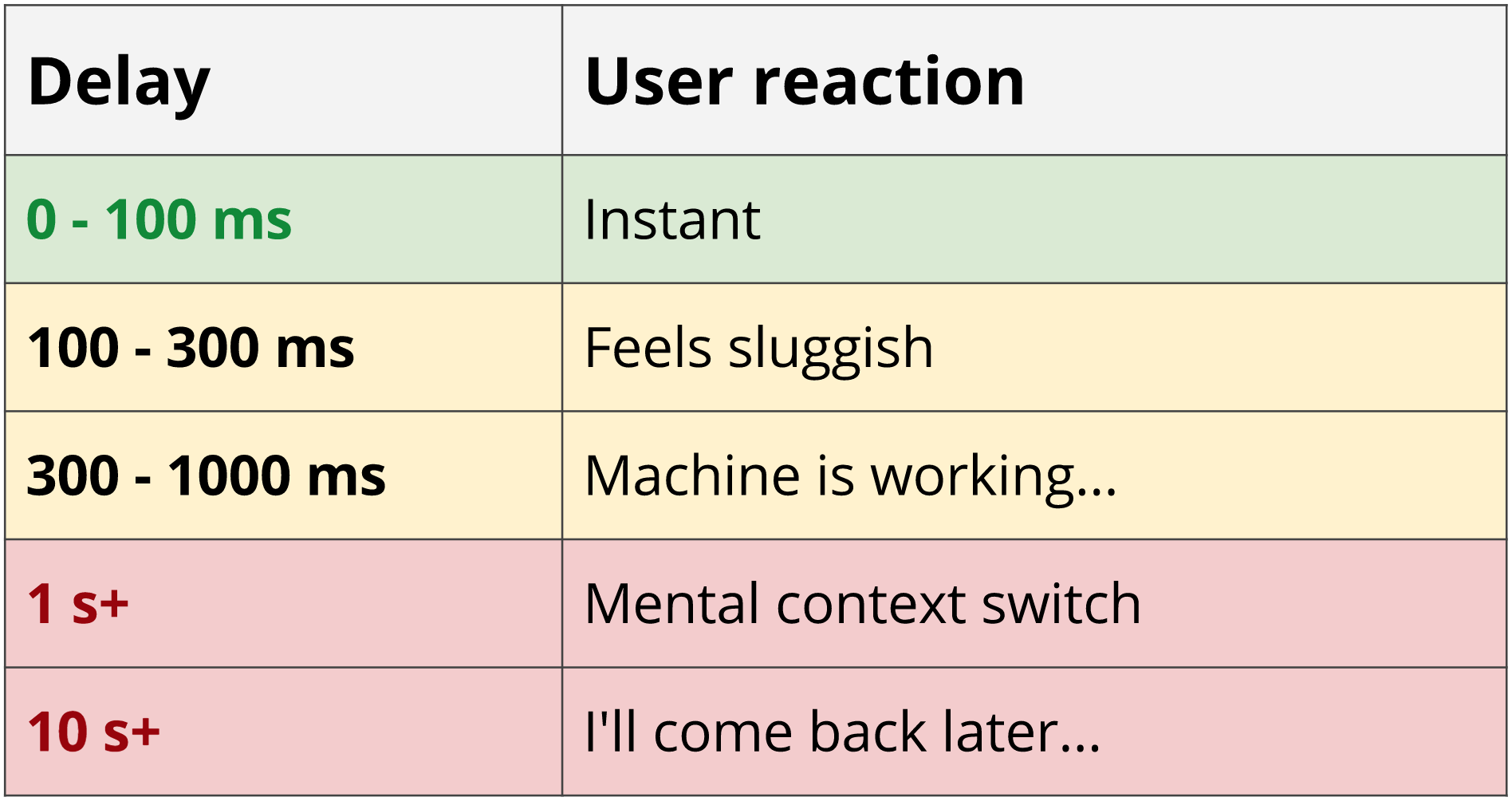
*55ms 4G latency * 8 requests = 440ms overhead*
Another problem with chatty services is that in many cases it takes less time to download one large request than many small ones. The reduced performance of small requests is true for many reasons including TCP Slow Start, lack of header compression and gzip efficiency and if you are curious about it, I highly recommend reading Ilya Grigorik’s High-Performance Browser Networking. The MaxCDN blog also has a great overview.
This problem is not technically with REST but with HTTP, specifically HTTP/1. HTTP/2 all but solves the problem of chattiness regardless of API style, and it has broad support in clients like browsers and native SDKs. Unfortunately, the rollout has been slow on the API side. Among the top 10k websites, adoption is around 20% (and climbing) as of late 2017. Even Node.js, much to my surprise, got HTTP/2 support in their 8.x release. If you have the ability, please update your infrastructure! In the meantime, let’s not dwell since this is only one part of the equation.
HTTP aside, the final piece of why chattiness matters, has to do with how mobile devices, and specifically their radios work. The long and short of it is that operating the radio is one of the most battery intensive parts of a phone so the OS turns it off at every opportunity. Not only does starting the radio drain the battery but it adds even more overhead to each request.
TMI (Overfetching)
The next problem with REST-style services is that the send way more information than is needed. In our blog example, all we need is each post’s title and its author’s name which is only about 17% of what was returned. That is a 6x loss for a very simple payload. In a real-world API, that kind of overhead can be enormous. E-commerce sites, for example, often represent a single product as thousands of lines of JSON. Like the problem of chattiness, REST services can handle this scenario today using “sparse fieldsets” to conditionally include or exclude parts of the data. Unfortunately, support for this is spotty, incomplete or problematic for network caching.
Tooling And Introspection
The final thing that REST APIs lack are mechanisms for introspection. Without any contract with information about the return types or structure of an endpoint, there is no way to reliably generate documentation, create tooling or interact with the data. It is possible to work within REST to solve this problem to varying degrees. Projects that fully implement OpenAPI, OData, or JSON API are often clean, well-specified and, to varying extents, well documented but backends like this are rare. Even Hypermedia, a relatively low hanging fruit, despite having been touted at conference talks for decades, still is not frequently done well, if at all.
Conclusion
Each of the API types is flawed, but every pattern is. This writing is not a judgment of the phenomenal groundwork that the giants in software have laid, only to be a sober assessment of each of these patterns, applied in their “pure” form from the perspective of a client developer. I hope that rather than coming away from this thinking a pattern like REST or RPC is broken, that you can come away thinking about how they each made tradeoffs and the areas where an engineering organization might focus its efforts to improve its own APIs.
In the next article, I will be exploring GraphQL and how it aims to address some of the problems I mentioned above. The innovation in GraphQL and similar tools is in their level of integration and not in their implementation. Please, if you or your team is not looking for a “batteries included” API, consider looking into something like the new OpenAPI spec that can help build a stronger foundation today!
If you enjoyed this article (or if you hated it) and would like to give me feedback, please find me on Twitter as @ebaerbaerbaer or LinkedIn at ericjbaer.
Further Reading
- A Guide To Redux Toolkit With TypeScript
- Knip: An Automated Tool For Finding Unused Files, Exports, And Dependencies
- Advanced Form Control Styling With Selectmenu And Anchoring API
- Why You Should Consider Graphs For Your Next GraphQL Project



{kind=link}
{kind=link}