Building A Pub/Sub Service In-House Using Node.js And Redis

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.



 Celebrating 10 million developers
Celebrating 10 million developersToday’s world operates in real time. Whether it’s trading stock or ordering food, consumers today expect immediate results. Likewise, we all expect to know things immediately — whether it’s in news or sports. Zero, in other words, is the new hero.
This applies to software developers as well — arguably some of the most impatient people! Before diving into BrowserStack’s story, it would be remiss of me not to provide some background about Pub/Sub. For those of you who are familiar with the basics, feel free to skip the next two paragraphs.
Many applications today rely on real-time data transfer. Let’s look closer at an example: social networks. The likes of Facebook and Twitter generate relevant feeds, and you (via their app) consume it and spy on your friends. They accomplish this with a messaging feature, wherein if a user generates data, it will be posted for others to consume in nothing short of a blink. Any significant delays and users will complain, usage will drop, and if it persists, churn out. The stakes are high, and so are user expectations. So how do services like WhatsApp, Facebook, TD Ameritrade, Wall Street Journal and GrubHub support high volumes of real-time data transfers?
All of them use a similar software architecture at a high level called a “Publish-Subscribe” model, commonly referred to as Pub/Sub.
“In software architecture, publish–subscribe is a messaging pattern where senders of messages, called publishers, do not program the messages to be sent directly to specific receivers, called subscribers, but instead categorize published messages into classes without knowledge of which subscribers, if any, there may be. Similarly, subscribers express interest in one or more classes and only receive messages that are of interest, without knowledge of which publishers, if any, there are.“
— Wikipedia
Bored by the definition? Back to our story.
At BrowserStack, all of our products support (in one way or another) software with a substantial real-time dependency component — whether its automate tests logs, freshly baked browser screenshots, or 15fps mobile streaming.
In such cases, if a single message drops, a customer can lose information vital for preventing a bug. Therefore, we needed to scale for varied data size requirements. For example, with device logger services at a given point of time, there may be 50MB of data generated under a single message. Sizes like this could crash the browser. Not to mention that BrowserStack’s system would need to scale for additional products in the future.
As the size of data for each message differs from a few bytes to up to 100MB, we needed a scalable solution that could support a multitude of scenarios. In other words, we sought a sword that could cut all cakes. In this article, I will discuss the why, how, and results of building our Pub/Sub service in-house.
Through the lens of BrowserStack’s real-world problem, you will get a deeper understanding of the requirements and process of building your very own Pub/Sub.
Our Need For A Pub/Sub Service
BrowserStack has around 100M+ messages, each of which is somewhere between approximately 2 bytes and 100+ MB. These are passed around the world at any moment, all at different Internet speeds.
The largest generators of these messages, by message size, are our BrowserStack Automate products. Both have real-time dashboards displaying all requests and responses for each command of a user test. So, if someone runs a test with 100 requests where the average request-response size is 10 bytes, this transmits 1×100×10 = 1000 bytes.
Now let’s consider the larger picture as — of course — we don’t run just one test a day. More than approximately 850,000 BrowserStack Automate and App Automate tests are run with BrowserStack each and every day. And yes, we average around 235 request-response per test. Since users can take screenshots or ask for page sources in Selenium, our average request-response size is approximately 220 bytes.
So, going back to our calculator:
850,000×235×220 = 43,945,000,000 bytes (approx.) or only 43.945GB per day
Now let’s talk about BrowserStack Live and App Live. Surely we have Automate as our winner in form of size of data. However, Live products take the lead when it comes to the number of messages passed. For every live test, about 20 messages are passed each minute it turns. We run around 100,000 live tests, which each test averaging around 12 mins meaning:
100,000×12×20 = 24,000,000 messages per day
Now for the awesome and remarkable bit: We build, run, and maintain the application for this called pusher with 6 t1.micro instances of ec2. The cost of running the service? About $70 per month.
Choosing To Build Vs. Buying
First things first: As a startup, like most others, we were always excited to build things in-house. But we still evaluated a few services out there. The primary requirements we had were:
- Reliability and stability,
- High performance, and
- Cost-effectiveness.
Let’s leave the cost-effectiveness criteria out, as I can’t think of any external services that cost under $70 a month (tweet me if know you one that does!). So our answer there is obvious.
In terms of reliability and stability, we found companies that provided Pub/Sub as a service with 99.9+ percent uptime SLA, but there were many T&C’s attached. The problem is not as simple as you think, especially when you consider the vast lands of the open Internet that lie between the system and client. Anyone familiar with Internet infrastructure knows stable connectivity is the biggest challenge. Additionally, the amount of data sent depends on traffic. For example, a data pipe that’s at zero for one minute may burst during the next. Services providing adequate reliability during such burst moments are rare (Google and Amazon).
Performance for our project means obtaining and sending data to all listening nodes at near zero latency. At BrowserStack, we utilize cloud services (AWS) along with co-location hosting. However, our publishers and/or subscribers could be placed anywhere. For example, it may involve an AWS application server generating much-needed log data, or terminals (machines where users can securely connect for testing). Coming back to the open Internet issue again, if we were to reduce our risk we would have to ensure our Pub/Sub leveraged the best host services and AWS.
Another essential requirement was the ability to transmit all types of data (Bytes, text, weird media data, etc.). With all considered, it did not make sense to rely on a third-party solution to support our products. In turn, we decided to revive our startup spirit, rolling up our sleeves to code our own solution.
Building Our Solution
Pub/Sub by design means there will be a publisher, generating and sending data, and a Subscriber accepting and processing it. This is similar to a radio: A radio channel broadcasts (publishes) content everywhere within a range. As a subscriber, you can decide whether to tune into that channel and listen (or turn off your radio altogether).
Unlike the radio analogy where data is free for all and anyone can decide to tune in, in our digital scenario we need authentication which means data generated by the publisher could only be for a single particular client or subscriber.
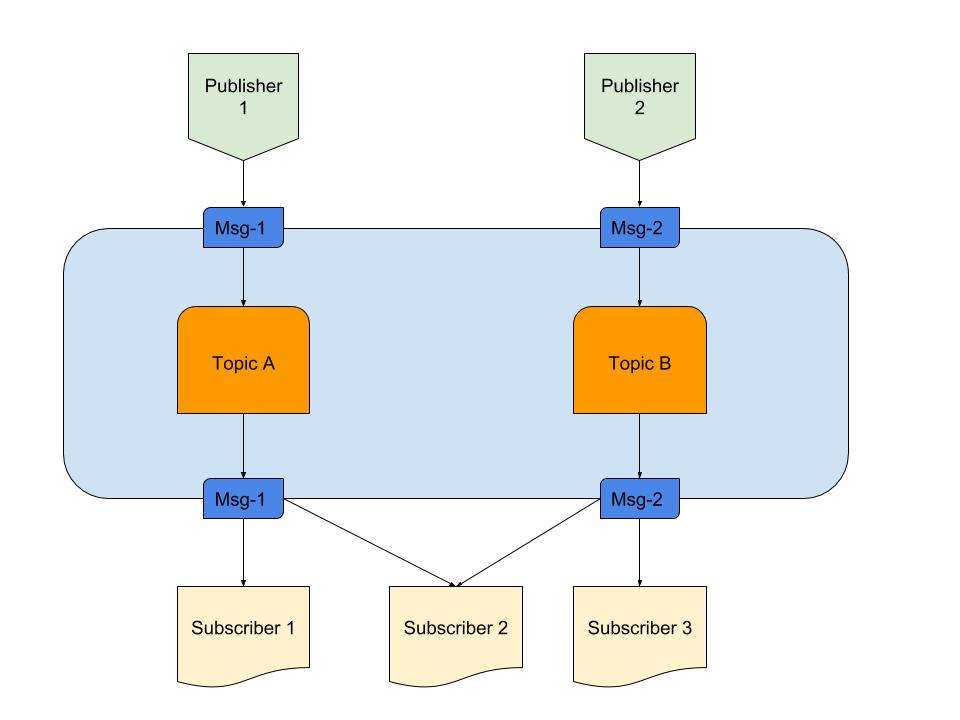
Above is a diagram providing an example of a good Pub/Sub with:
- Publishers
Here we have two publishers generating messages based on pre-defined logic. In our radio analogy, these are our radio jockeys creating the content. - Topics
There are two here, meaning there are two types of data. We can say these are our radio channels 1 and 2. - Subscribers
We have three that each read data on a particular topic. One thing to notice is that Subscriber 2 is reading from multiple topics. In our radio analogy, these are the people who are tuned into a radio channel.
Let’s start understanding the necessary requirements for the service.
- An evented component
This kicks in only when there is something to kick in. - Transient storage
This keeps data persisted for a short duration so if the subscriber is slow, it still has a window to consume it. - Reducing the latency
Connecting two entities over a network with minimum hops and distance.
We picked a technology stack that fulfilled the above requirements:
- Node.js
Because why not? Evented, we wouldn’t need heavy data processing, plus it’s easy to onboard. - Redis
Supports perfectly short-lived data. It has all the capabilities to initiate, update and auto-expire. It also puts less load on the application.
Node.js For Business Logic Connectivity
Node.js is a nearly perfect language when it comes to writing code incorporating IO and events. Our particular given problem had both, making this option the most practical for our needs.
Surely other languages such as Java could be more optimized, or a language like Python offers scalability. However, the cost of starting with these languages is so high that a developer could finish writing code in Node in the same duration.
To be honest, if the service had a chance of adding more complicated features, we could have looked at other languages or a completed stack. But here it is a marriage made in heaven. Here is our package.json:
{
"name": "Pusher",
"version": "1.0.0",
"dependencies": {
"bstack-analytics": "*****", // Hidden for BrowserStack reasons. :)
"ioredis": "^2.5.0",
"socket.io": "^1.4.4"
},
"devDependencies": {},
"scripts": {
"start": "node server.js"
}
}
Very simply put, we believe in minimalism especially when it comes to writing code. On the other hand, we could have used libraries like Express to write extensible code for this project. However, our startup instincts decided to pass on this and to save it for the next project. Additional tools we used:
- ioredis
This is one of the most supported libraries for Redis connectivity with Node.js used by companies including Alibaba. - socket.io
The best library for graceful connectivity and fallback with WebSocket and HTTP.
Redis For Transient Storage
Redis as a service scales is heavily reliable and configurable. Plus there are many reliable managed service providers for Redis, including AWS. Even if you don’t want to use a provider, Redis is easy to get started with.
Let’s break down the configurable part. We started off with the usual master-slave configuration, but Redis also comes with cluster or sentinel modes. Every mode has its own advantages.
If we could share the data in some way, a Redis cluster would be the best choice. But if we shared the data by any heuristics, we have less flexibility as the heuristic has to be followed across. Fewer rules, more control is good for life!
Redis Sentinel works best for us as data lookup is done in just one node, connecting at a given point in time while data is not sharded. This also means that even if multiple nodes are lost, the data is still distributed and present in other nodes. So you have more HA and less chances of loss. Of course, this removed the pros from having a cluster, but our use case is different.
Architecture At 30000 Feet
The diagram below provides a very high-level picture of how our Automate and App Automate dashboards work. Remember the real-time system that we had from the earlier section?
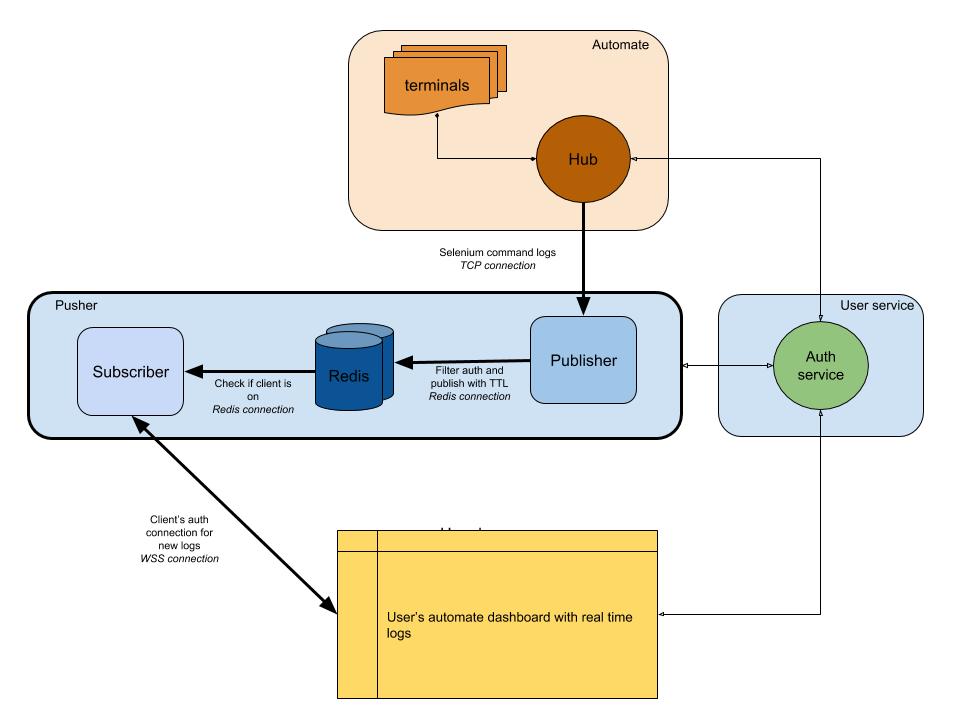
In our diagram, our main workflow is highlighted with thicker borders. The “automate” section consists of:
- Terminals
Comprised of the pristine versions of Windows, OSX, Android or iOS that you get while testing on BrowserStack. - Hub
The point of contact for all your Selenium and Appium tests with BrowserStack.
The “user service” section here is our gatekeeper, ensuring data is sent to and saved for the right individual. It is also our security keeper. The “pusher” section incorporates the heart of what we discussed in this article. It consists of the usual suspects including:
- Redis
Our transient storage for messages, where in our case automate logs are temporarily stored. - Publisher
This is basically the entity that obtains data from the hub. All your request responses are captured by this component which writes to Redis withsession_idas the channel. - Subscriber
This reads data from Redis generated for thesession_id. It is also the web server for clients to connect via WebSocket (or HTTP) to get data and then sends it to authenticated clients.
Finally, we have the user’s browser section, representing an authenticated WebSocket connection to ensure session_id logs are sent. This enables the front-end JS to parse and beautify it for users.
Similar to the logs service, we have pusher here that is being used for other product integrations. Instead of session_id, we use another form of ID to represent that channel. This all works out of pusher!
Conclusion (TLDR)
We’ve had considerable success in building out Pub/Sub. To sum up why we built it in-house:
- Scales better for our needs;
- Cheaper than outsourced services;
- Full control over the overall architecture.
Not to mention that JS is the perfect fit for this kind of scenario. Event loop and massive amount of IO is what the problem needs! JavaScript is magic of single pseudo thread.
Events and Redis as a system keep things simple for developers, as you can obtain data from one source and push it to another via Redis. So we built it.
If the usage fits into your system, I recommend doing the same!
Further Reading
- Building And Dockerizing A Node.js App With Stateless Architecture With Help From Kinsta
- The End Of My Gatsby Journey
- Event Calendars For Web Made Easy With These Commercial Options
- New CSS Viewport Units Do Not Solve The Classic Scrollbar Problem


