Strategies For Headless Projects With Structured Content Management Systems

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.




 Celebrating 10 million developers
Celebrating 10 million developers Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.This is the guide I wish I had the last couple of years when running projects with headless Content Management Systems (CMSs). I’ve been a developer, a user-experience and technology consultant, a project manager, information architect, and an author. The different hats have made me realize that even if we’ve had so-called “headless” CMSs for a while now, there’s still a way to go about thinking how to use them best.
We are now at a place where many of us rely on JavaScript frameworks for frontend work, using design systems made of components and compositions, rather than just implementing flat page layouts. There’s a lot of traction towards the JAMstacks and isomorphic/universal apps that run both on the server and the client. The final piece of the puzzle then is how we manage all the content.
Traditional CMSs are adding APIs to serve content through network requests and the JSON format. In addition, “headless” CMSs have emerged to exclusively serve content through APIs. My argument in this article though, is that we should spend less time talking about “headless”, and more about “structured content”. Because that is the essential quality of these systems. There are lots of implications for our craft implied by these systems, and we still have a way to go in terms of figuring out the good patterns of how we should deal with these technologies.
Coming to technology consulting from a background in humanities, I have learned a lot about how to organize and work with web projects that take a content-centric approach — both with the newer API-based as well as the traditional CMSs. I have come to appreciate how getting started early with actual live content from a CMS; doing so in a cross-disciplinary setting has not only made it possible to uncover complexities at an earlier stage but also lends agency to everyone involved, and gives opportunities to reflect on the challenges and possibilities of technology and design in its broadest sense.
Headless WordPress
Everyone knows that if a website is slow, users will abandon it. Let’s take a closer look at the basics of creating a decoupled WordPress. Read a related article →
In this article, I’ll suggest some overarching strategies, with some concrete, real-world examples on how to think about working with structured content. At the time of writing, I have just started working for a SaaS company that provides such a content management service, for hosting content delivered over APIs. I will make references to it, both because of my past experience with it in projects I was involved in as a consultant, but also because I think it aptly illustrates the points I want to make. So consider this a disclaimer of sorts.
That being said, I have been thinking about writing this article for a couple of years, and I have strived to make it applicable to whatever platform you choose to go with. So without further ado, let’s jump twenty years back in time in order to understand a bit more where we are today.
First Moves With Web Standards
In the early 2000s, the Web Standards movement inspired a field to change their ways of working. From a “layout-first” approach, they directed our attention towards how content on a page should be marked up semantically using HTML: A website’s menu isn’t a <table>, it’s a <nav>; A heading is not a <b>, it’s an <h1>. It was a significant step towards thinking about the different roles content web plays in order to help users find, identify and take it in.
The Web Standards movement introduced the argument that semantic markup improved accessibility, which also improved its ranking in the Google search results. It also marked a shift in how we thought about web content. Your website wasn’t longer the only place your content was represented. You also had to think about how your web pages were presented in other visual contexts, like in search results or screen readers. This was later fueled by social media and embedded previews of shared links. The mindset shifted from how the content should look, to what it should mean. This also happens to be the key to working with structured content.
With the adoption of pocket-size devices connected to the Internet, the web suddenly got a serious contender in apps. The competition, however, was mostly for the eyeballs of the end user. Many organizations still needed to distribute information about their products and services in both their apps and their different web presences. Concurrently, the web matured, and JavaScript and AJAX made it easier to connect different sources of content through APIs. Today, we have GraphQL and tooling that make content fetching and state management simpler. And so the bits of the technological puzzle begin to fall into place.
“Create Once, Publish Everywhere”
Though it’s mostly described as a “technological shift”, the embedding of content in JSON payloads (traveling along HTTP tubes) has an outsized impact of how we think about digital content and surrounding workflows. In some ways, it already has. Almost ten years ago, National Public Radio’s (NPR) Daniel Jacobson guest blogged at programmableweb.com about their approach, summed up in in the acronym COPE which stands for “Create Once, Publish Everywhere”. In the article, he introduces a content management system providing content to multiple digital interfaces through an API — not through an HTML rendering machine — as most CMSs at the time (and arguably now) did.
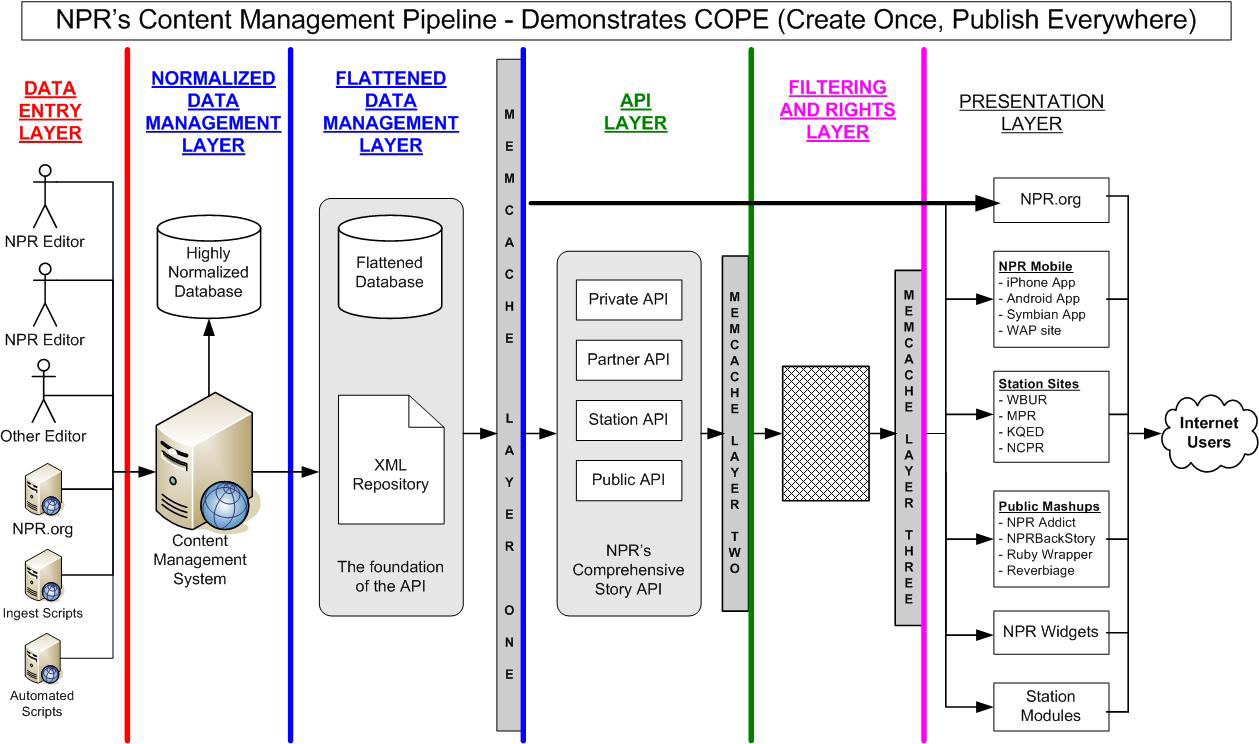
NPR’s COPE “data management layer” is what would become the notion of “a headless CMS”. In the early days of COPE, it was achieved by structuring the content in XML. Today, JSON has become the dominant data format for transferring data over APIs, including internet of things devices, and other systems outside the web. If you want to exchange content with chatbots, voice interfaces, and even software for visual prototyping, you very often talk HTTP with a JSON accent.
“Uncoining” The Term “Headless CMS”
According to Google Trends, searches for “headless CMS” gained in popularity as late as 2015, i.e. six years after NPR’s COPE article. The term “headless” (at least in relation to digital technology and not late 18th-century French aristocracy), has been used a good while longer to talk about systems that run without a graphical user interface.
Note: One could argue that a command line interface is indeed “graphical” such as software on servers or testing environments (but let’s save that for another article).
I’m of two minds calling these new CMSs “headless”. We could as well call them “polycephalic” — that which has many heads. They are the Hydras and Cerbeuses of CMSs. “Headless” is also defining these systems by the capability they lack (i.e., a template engine for rendering web pages), instead of defining them by their true strength: making it possible to structure content without the constraints of the web. That being said, as of today, many of the solutions in this category could also be called “Nearly Headless Nick”. Because the editing interface is still tightly coupled to the system. Their “headlessness“ arises from their lack of a templating engine, that is, the machinery producing markup from content.
Note: I would almost definitely use a CMS called “Mimsy-Porpington” (known from the Harry Potter universe) though.
Instead, they make content available through an API, hence giving you more flexibility for how, what, and where you want to display and use this content. This makes them perfect companions to popular JavaScript frontend frameworks such as React, Angular, and Vue. And despite the claim of being able to deliver content to “websites, apps, and devices”, most of them are still limited by how web content works. This is most noticeable in the way most handle rich text — storing it either as HTML or Markdown.
Traditional CMSs have also started adding somewhat generic APIs in addition to their template rendering systems and call this “decoupled” as a way to distinguish themselves from their fresh competitors. “All this, and APIs, too!”* is the claim. Some of these CMSs are also pretty agnostic when it comes to the content modeling. For example, Craft CMS, makes almost no assumptions about your content model when you first install it. Wordpress is also moving towards using APIs for content delivery. I suspect the gap between the old players in the CMS field and the new will get narrower as we go along.
Nonetheless, putting content management behind APIs (instead of an HTML renderer) is an important step to more sophisticated ways of working in an age where an organization’s text, images, videos, and media are digitized and exposed to internal and external users and customers. It’s time though, to move away from defining their lacking frontend rendering capabilities, to what they really can do for us: give us a way to work with structured content. So, should we be calling them “Structured Content Management Systems”? As in, “No Bob, this isn’t your usual CMS. This is a SCMS, trust me, it’s going to be a thing.”
It’s Not About The Heads, It’s About Structured Content
The most radical change that the Structured Content Management Systems (SCMS) imposes is a move away from arranging content according to a page hierarchy to where you are free to structure content for whatever purpose you see fit. Avoiding duplicate content is a clear advantage because it increases reliability and decreases administrative burden (you don’t have to cope with duplicated content across multiple channels). In other words: Create Once, Publish Everywhere. If you just have to update your product description once — in one system — and it updates wherever your product is exposed to the user, that’s clearly an advantage.
While SCMS vendors frequently use “your website and an app” to justify thinking differently on page structure, you don’t have to cross the river to draw benefits from a structured content structure. With the popularity of JavaScript frameworks, it’s more and more common to build websites as a composition of individual components, that can be “filled” with different content depending on state and context. You may have a product card that appears in many different contexts throughout your web application. We’re seeing that modern web development moves away from setting documents and pages to composing components according to a mixture of user input, algorithms, and customization.
These trends for how design systems are made, and how we are encouraged to work in teams through processes of testing, learning, and iteration, makes the field of content management ripe for some new ways of thinking. Some patterns have emerged, but we still have many ways to go. Therefore, based on my experience from working in teams and projects that have put content front and center, and as now part of a team that builds a service for it (and I urge you to be aware of any bias here), I want to put forth some strategies that I believe can be helpful and create points for further discussion.
1. Approach Content In Multi-Disciplinary Teams
I believe that it is a thing of the past that a graphic designer can hand over stale, pixel-perfect pages to a frontend developer whose responsibility was to “implement” the design. We now make design systems consisting of smaller components, laid out in compositions that come with multiple possible states out of the box. More often than not, these components have to be resilient to user-generated input, which means that the sooner you introduce live content into the process, the better. A frontend developer’s responsibility isn’t to reproduce the vision of a graphic designer’s; it’s to maneuver a complex field of how browsers render HTML, CSS, and JavaScript, making sure that the user interfaces are responsive, accessible and performant.
When working as a technology consultant at Netlife (a consultancy specialized in user experience), I saw great steps being made towards collaboration between developers, designers, and user researchers. Even though our content editors were always involved in the project from the get-go, their contributions didn’t enter design workflow mainly because of technical friction.
The bottleneck was often a legacy CMS we couldn’t touch, or that it took time to build the content structure because it was dependent on the design layout. This often resulted in work being doubled: We made an HTML prototype, often based on content parsed from Markdown-files, which had to be re-implemented in the CMS-stack when the user testing was done, and everyone was pixel-perfect happy. This was often an expensive process as limitations in the CMS were discovered late in the process. It also creates pressure on all parts to “get it right the first time” and left less space for the kind of experimentation you would want in a design project.
Multi-Disciplinary Work Requires Nimble Systems
Moving to a SCMS in which it took minutes to code up a content model (where fields and API were ready instantly) turned our process upside down — and for the better. I remember sitting with the content editor of the new u4.no in the project’s first days. Talking through how they worked and would like to work with their content. Rather quickly, we translated our conclusions into simple JavaScript-objects that were instantly transformed to an editing environment in the browser. Figuring out helpful titles and descriptions for the titles. We talked about how they wanted text-snippets they could reuse across different pages and contexts, which they in-house called “nuggets”, which we then created then and there.
Allowing for this kind of exploration early in the project development — a content editor and a developer talking together while the interface was being made in front of us — felt powerful. Knowing that we could continue designing the frontend in React while she and her colleagues began working with the content. And not worrying about painting ourselves into a corner, like we often did with CMSs in which the structure was tightly coupled with how you had to code up the frontend part of it.
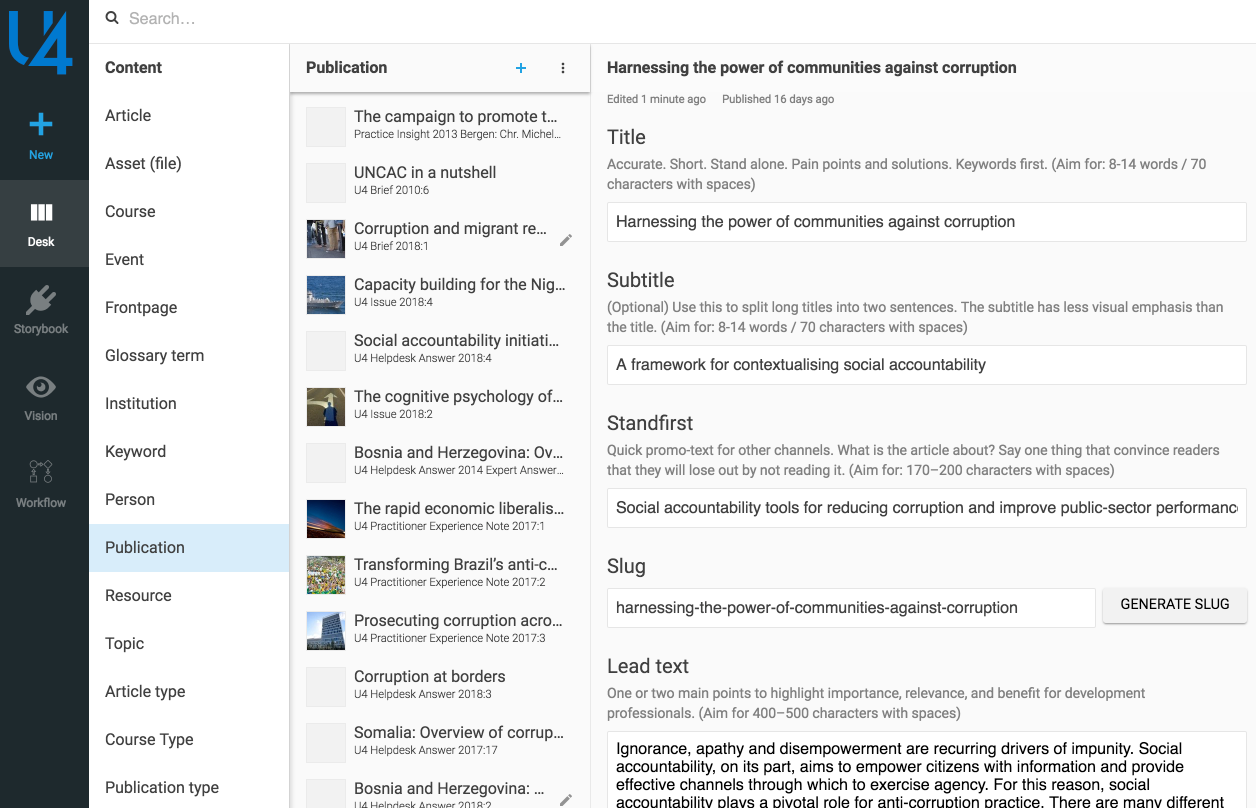
A Content System Should Allow For Experimentation And Iteration
Creative redesign projects aside, a system for structured content should also allow you to continue improving, testing and iterate your content as part of your whole design system. UX designers should be able to quickly prototype with real content using tools like Sketch or Framer X. You should be able to augment content management with quantitative measurements, be it readability scales or how the content performs where it’s used.
Note: I used the term “UX designers” above despite having the opinion that we all should — in some way — relate to the process of making good user experiences. We’re all UX designers in our different strands of design.
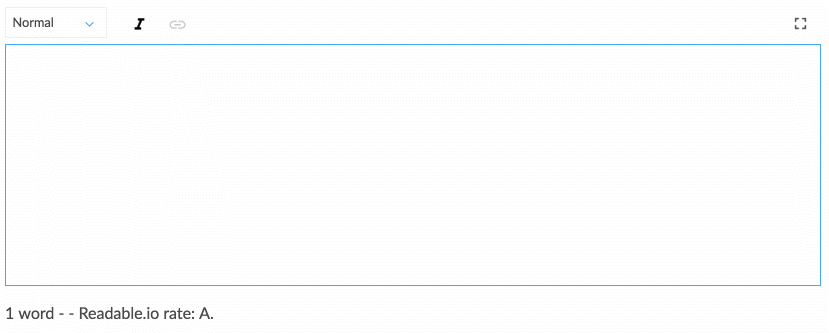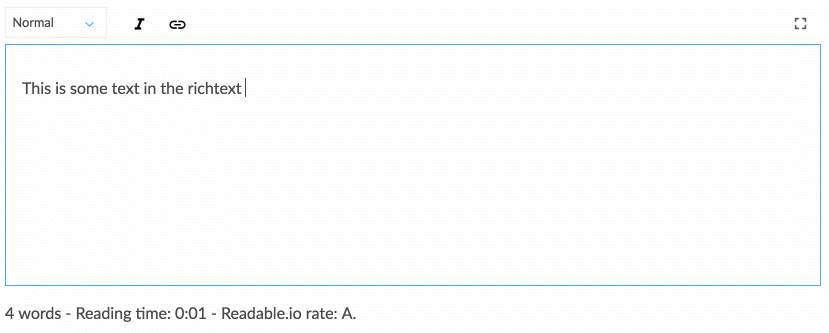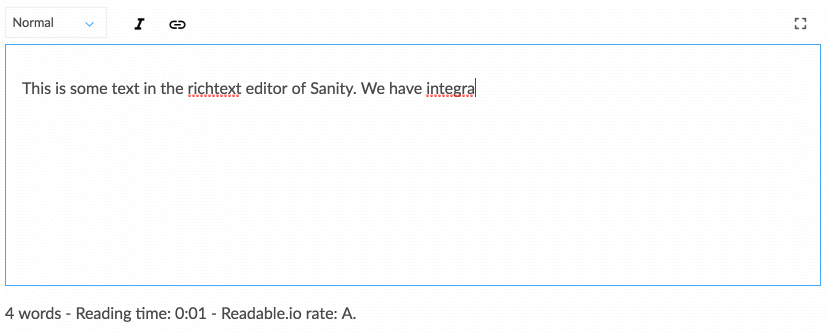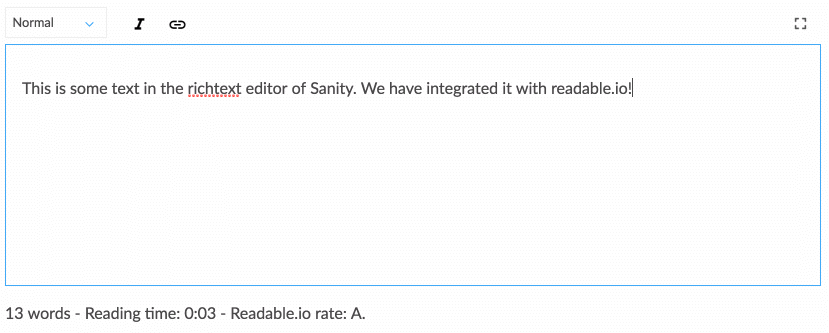
Working with structured content requires a bit of getting used to if you’re used to just WYSIWYG-ing content directly on your web page layout. Yet, it lends itself to a conversation that is more in line with how the digital design field is moving. Structured content lets a team of designers, developers, content editors, user researchers, and project managers collectively think about how a system should work to support users’ needs and strategic goals. This also requires you to think differently about how content structures, which takes us to the next strategy.
2. You Might Not Need A Pecking Order
One of the most notable changes for many is that systems for structured content are geared towards collections and lists of documents and not folder-like hierarchies that reflect website navigation structures. These structures stop making sense as soon as some of the content is to be used in other contexts — be it chatbots, print media or other websites. Traditional CMSs have tried to mitigate this by allowing for reusable content blocks, but they still need to be placed on page layouts and cumbersome to reason with through APIs.

Each Page To Its Own
As laid out in The Core Model, when one of your main referrers is either Google or sharing on social media, you should consider every page a landing page. And if you look at the distribution of page views, you will notice that some of your pages are way more popular than others. Unless you are a news website, those tend not to be the news, but those that let the user achieve whatever they hoped to achieve on your website. They are where business is actually happening.
Your digital content should be in service of the intersection of your own strategic goals and individual goals of your users. When the digital agency Bengler (sanity.io’s predecessor) made the new website for oma.eu, they didn’t structure the content after an elaborate hierarchy of pages. They made content types that reflected the organizational everyday reality, i.e. after projects, persons, and publications. In fact, the OMA-website is almost completely flat in terms of a content hierarchy, and the front page is generated from a mix of algorithmic and editorial rules.
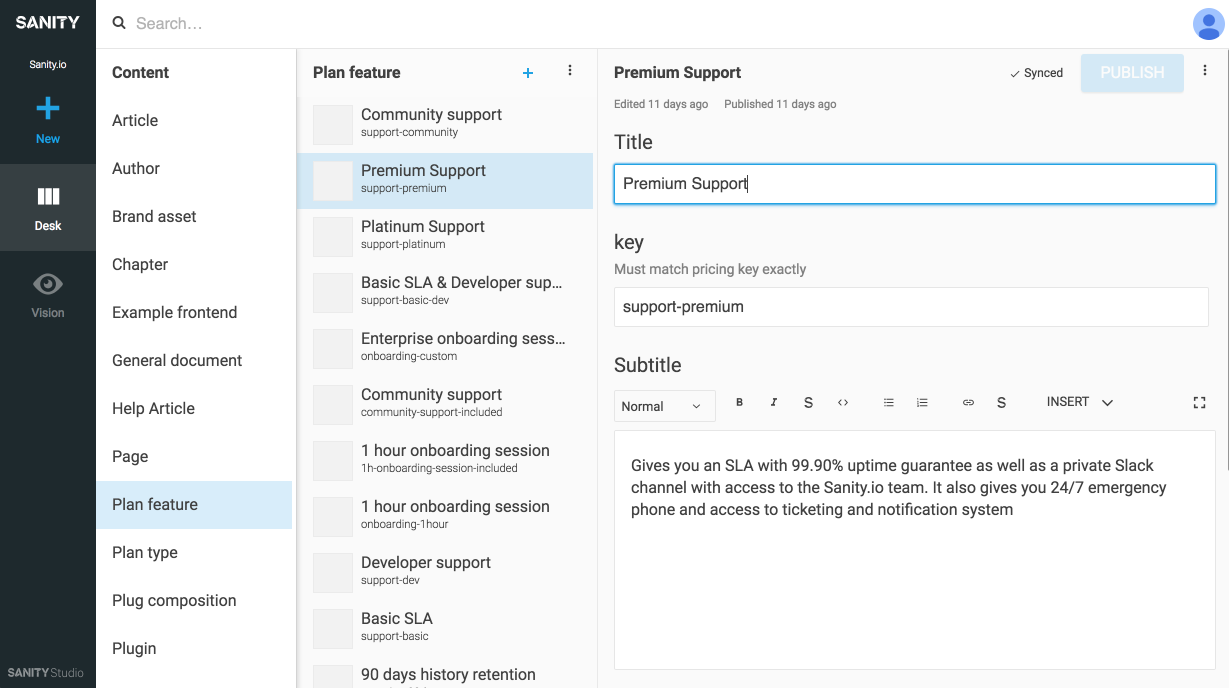
So, how to go about it? I believe a mix of thinking about your content as a reflection of how your organization’s mental model and what it needs to be to be useful for whatever your users need it for.
Here’s a basic example: When building a page of employees, you should probably start with a content type called person. A person can have a name, contact info, an image, different organizational roles, and a short biography. A person document can be reused in contact lists, article author bylines, chat support interfaces, and building access badges. Perhaps you already have an in-house system that knows who these people are and that comes with an API? Great, then synchronize with that.
Don’t Get Lost In An Ontological Rabbit Hole
It’s useful to return to Google’s way of indexing web pages and how they’re trying to index the world’s information. That’s why they are expending time and effort on linked data (RDFa, microformat, JSON-LD). If you annotate your web pages with JSON-LD elements, you will appear more prominently in search results. It’s also relevant when your information should be spoken by voice assistants and displayed in an assistant UI. If your content is already structured and easily available in an API, it will be relatively easy for you to implement it in these microformats.
I’m not sure I would recommend going all in on the ontologies of schema.org and various linked data resources though, at least not for editor purposes. You can quickly get lost in a rabbit hole of trying to make perfect platonic structures where it all fits.
Newsflash: It never will, because the world is a messy place, and because people think about stuff differently.
It’s more important to structure your content in a system that makes intuitive sense and lends itself to be adapted as needs change. This is why it’s important to start with content modelling early on in the design and development process — you need to learn about how it needs to be used.
Abstract From Reality, Not From CMS Conventions
It can be tempting to just follow whatever conventions your CMS comes with. Remember how Wordpress will give you “Posts” and “Pages”, and suddenly everything needs to be fitted into those boxes? A WYSIWYG rich text field is flexible in that it allows you to put in whatever, but the content will not be structured and easily adaptable — it’s only flexible once. But you need some place to begin your mapping of a content model. My suggestion is to begin with talking to people, i.e. the authors and readers.
How do people talk about the content internally? What do people call different things? You could run a free-listing exercise, a method used by ethnographers to map folk-taxonomies. For example, you could ask:
“Name the different types of content in our organization.”
Or, on a more specific level:
“Can you name the different types of reports we have in this organization?”
The point with this survey is to tease out the internalized taxonomies people carry, and not their opinions or feelings about things (something that often tends to derail design processes). You don’t have to ask particularly many before having a pretty exhaustive list you can work from. You’ll probably find that parts of your list come from conventions in your current CMS (that’s good to know if you are to do some remodelling). Now you should talk with your editor and try to pin down what they need the content to do.
Some questions you can ask could be the following:
- Do you need to use this content in more than one place? Where?
- What are the different relationships between the content types?
- Where do we need the content to be displayed today, and tomorrow?
- In which ways do we need content to be sorted? Can the ordering be done algorithmically, by the user, or does it have to be manually?
- Are there systems or databases in other systems that we can synchronize with in order to prevent duplication?
- Where do we want the canonical content to live? Should the SCMS be the source for it, or just augment existing content, e.g. marketing copy for products living in a product management system?
This doesn’t mean that you have to throw the traditional information architecture out with the now lukewarm bathwater. It still makes sense to have articles as a content type, if articles are a part of your organization’s content reality. But perhaps you don’t really need the abstract convention of categories, because how these articles have references to the type of services or products in them. And this relation allows for querying these articles in circumstances where it makes sense, without requiring someone to have “article category management” as part of their job description.
The article is also what makes it hard to decouple content completely from the presentation layer. We are so used to thinking about the layout and styling of the article, but in an age where you are expected to host your own content on your own domain, and then syndicate it to platforms such as medium.com, you already have given up control over visual presentation. This takes us to the next strategy.
3. Presentation Contexts Are Also Content Types
Be Redesign Ready
You want to be able to adapt and quickly change the navigation structure of your website as well, without having to either rebuild your whole content architecture or fight against a stringent folder-like interface. You also want to be able to have some content hierarchy, because it sometimes makes sense, and sometimes it gets deeper than two levels, where most interfaces in the department of API-first CMSs fail to deliver much help.
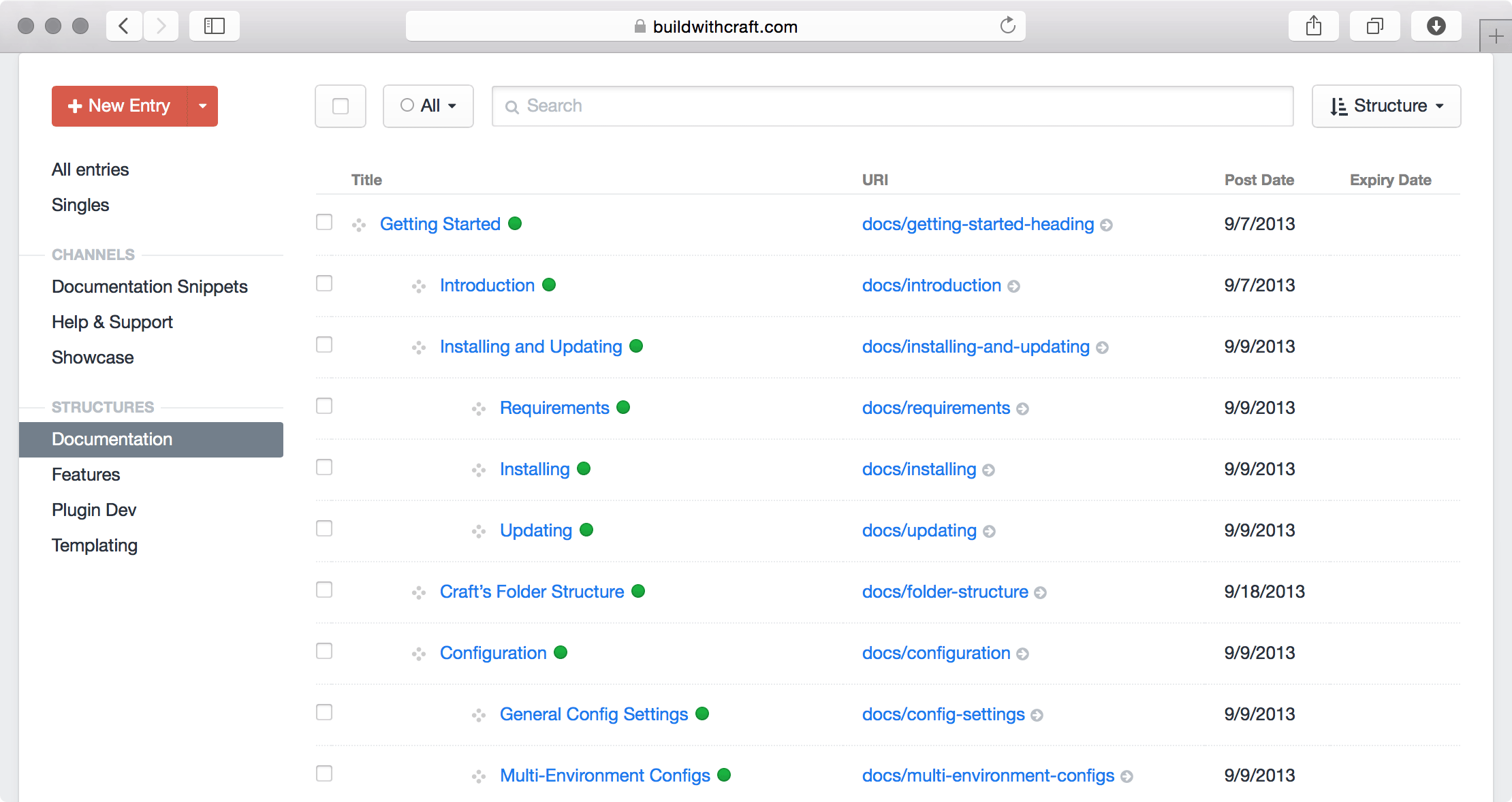
Interestingly, content management systems for chatbots tend to use similar hierarchical structures for arranging intent trees and dialog flows. This goes to say that content hierarchies play different roles in different channels, but often they provide ways of navigating through content. A way to approach this is to make types for navigation, where you can arrange content by references, and either build routes for web pages, menus, or paths for conversational interfaces.
Relationship Advice
References (or relationships) is what makes a system for structured content possible, and it’s really the core of everything we’re dealing with when it comes to content on the web (it’s the reason it’s metaphorically called the web in the first place). To be able to make references between bits of content is a very powerful thing, but it can also be costly in terms of how the backends are able to write and retrieve such data. So you may have to think differently if you have multitudes of documents since scale seldom comes for free.
It’s also worth considering that you don’t always need an explicit reference to join data; most often it can be done by criteria that has to do with the content, e.g. “give me all persons and all buildings within this geolocation”. The building and persons don’t need to have an explicit reference to each other, as long as it’s implied in a location field on both content types.
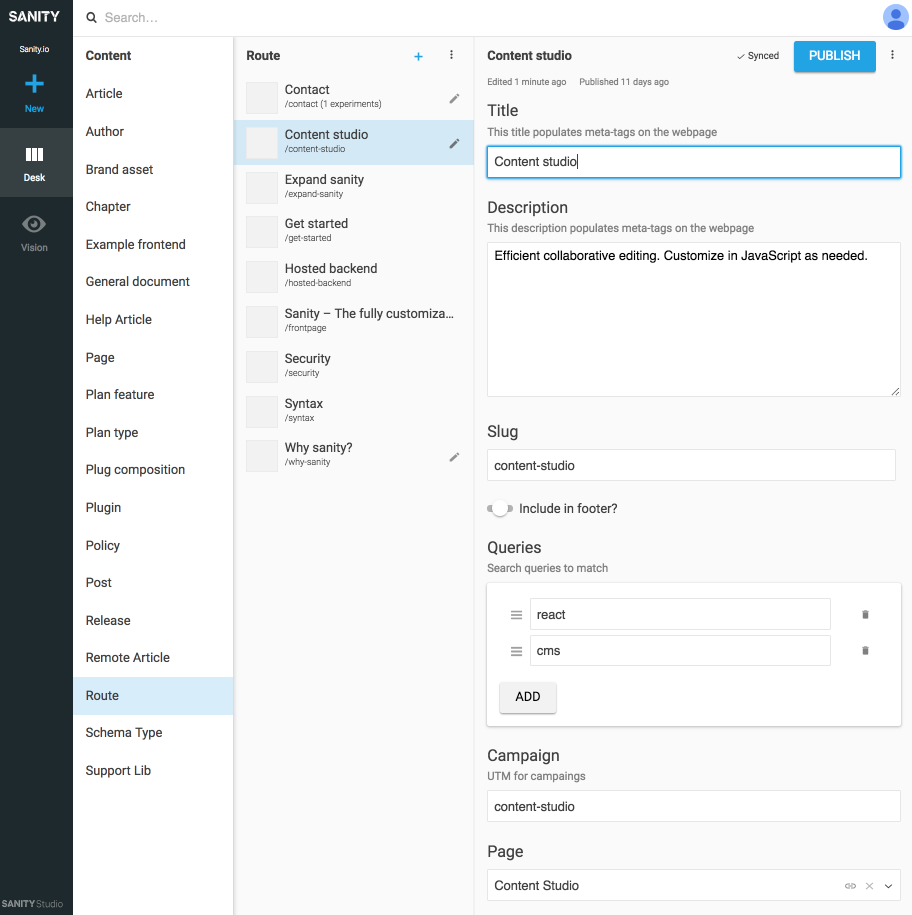
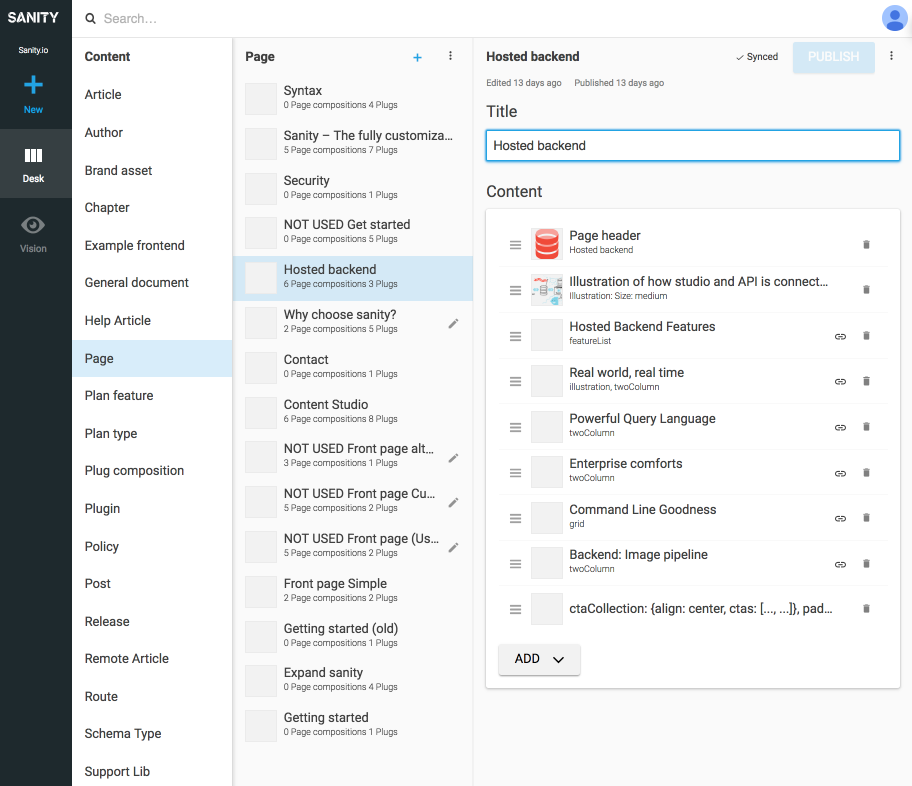
References between presentation types and other content types is useful when you can’t leave it to an algorithm in the presentation layer to join data. It may seem a bit cumbersome to explicitly draw these presentation types and make compositions of referred content, but it’s a solution to a problem you’ll often meet with SCMSs: It’s hard to know where content is being used. By including navigation types, you’ll explicitly tie content to presentation, but not just one. This makes it possible to reason to work with navigational structures independently of the content they lead to.
For example, in the screenshots we have tied Google Experiments to the routes type, allowing for adding multiple pages composed by references to content, which means that we can run A/B-tests with next to no content duplication. Since we also get a warning if we try to delete content that is referenced by other documents, this way of structuring will keep us from deleting something we shouldn’t.
Relationships across content types is a double-edged sword. It increases sustainability and is key to avoid duplication. On the other hand, you can easily cut yourself because you make dependencies between content, which (if not made transparent) can lead to unintended changes across the channels where your data is displayed. It would, for example, be bad if we could remove a “page” used by a “route” without warning.
This leads us to the next strategy, which (granted!) is partly beyond the power of the normal user as of today since it has to do with how different systems are architected. Still, it’s worth thinking about.
4. Don’t Put Rich Text In A Corner
Rich Text Is More Than HTML
I can understand why HTML is given such prevalence in digital content, but know it also comes from something; it’s a subset of SGML, a generalized way of structuring machine-readable documents. As Claire L. Evans points out in the wonderful book “Broad Band: The Untold Story of the Women who made the Internet” (2018), there was already a vibrant community of people thinking about linked documents when HTML was introduced. Tim Berners-Lee’s proposal was a lot simpler than many of the other systems at the time, but that’s probably why it caught on and made the — as of now — open, free web possible.
When you’re in a browser on the world wide web, HTML is great. If you’re a writer who wants to publish something that ends up in simple HTML, Markdown is great. If you want your rich text content to be easily integrated into something that isn’t a browser, or a popular JavaScript-framework that lets you augment HTML with JavaScript in complex components (yes, we’re talking about React and Vue.js), having HTML in your API responses begins to be a bit of a hassle — especially if you need to parse it.
Almost everyone does it though, even the new kids on the block: I went through all the vendors on headlesscms.org and browsed through the documentation, and also signed up for those who didn’t mention it. With two exceptions, they all stored rich text either as HTML or Markdown. That’s fine if all you do is use Jekyll to render a website, or if you enjoy using dangerouslySetInnerHTML in React. But what if you want to reuse your content in interfaces that aren’t on the web? Or if you want more control and functionality in your rich text editor? Or just want it to be easier to render your rich text in one of the popular frontend frameworks, and have your components take care of different parts of your rich text content? Well, you’ll either have to find a smart way to parse that markdown or HTML into what you need, or, more conveniently, just have it stored more sensically in the first place.
For example, what if you want to output your rich text to a voice interface? We know that voice assistants are increasing in popularity. The most popular platforms for these assistants have the capabilities to get the text for spoken content through APIs. Then you want to take advantage of something like Speech Synthesis Markup Language. A system for portable text takes a more agnostic approach to rich text, which lets you adapt the same content for different kinds of interfaces.
Recommended reading: Experimenting With The SpeechSynthesis Interface
Portable Text As An Agnostic Rich Text Model
Portable text is also useful when you’re primarily doing content for the web. What if you want to have the possibility to nest and augment your text with data structures, such as a rich text footnote, or an inline editorial comment? Or an alternative phrase or wording for A/B-testing cases? Markdown and HTML quickly fall short, and you’ll have to rely on adding something like special shortcode tags, just like Wordpress has solved it. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you’ll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn’t widely adopted, but we’re seeing movements towards it. The specification isn’t very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn’t just used for your organization’s online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it’s about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can’t know prior to solving the problem whether the user tasks are best solved by making carousels (newsflash: most probably not), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile (there’s my coin for the swear jar) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn’t a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we’ve taken for granted for many years, but that’s probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.
Further Reading
- Modern Methods For Improving Drupal’s Largest Contentful Paint Core Web Vital
- Visual Editing Comes To The Headless CMS
- Iconography In Design Systems: Easy Troubleshooting And Maintenance
- 50 Resources And Tools To Turbocharge Your Copywriting Skills


