Going Serverless With Cloudflare Workers

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
(This is a sponsored article.) It is a truth universally acknowledged, that a website in pursuit of success must be in want of speed. And so, it goes serverless.
At its core, serverless is a strategy for a website’s architecture, based on deploying static files (the good old HTML, CSS and image files) on cloud-based hosting, and augmenting the website’s capabilities by accessing cloud-based, charge-per-use dynamic functionality. There is nothing mystical or mysterious about serverless: its end result is simply a website or application.
In spite of its name, “serverless” doesn’t mean “without a server”. It simply means “without my own server”. This means that my site is still hosted on some server, but by offloading this responsibility to the cloud services provider, I can devote all my energies to developing my own product (the website) and not have to worry about the infrastructure.
Serverless is very appealing for several reasons:
- Low-cost
You only pay for what you use. Hosting static files on the cloud can cost just a few cents a month (or even be free in some cases). - Fast
Static files can be delivered to the user from a Content Delivery Network (CDN) located near the user. - Secure
The cloud provider constantly keeps the underlying platform up-to-date. - Easy to scale
The cloud provider’s business is to scale up the infrastructure on demand.
Serverless is also becoming increasingly popular due to the increasing availability of services offered by cloud providers, simple-yet-powerful template-based static site generators (such as Jekyll, Hugo or Gatsby) and convenient ways to feed data into the process (such as through one of the many git based CMS’s).
The Network Is The Computer: Introducing Cloudflare Workers
Cloudflare, one of the world’s largest cloud network platforms, is well versed in providing the benefits we are after through serverless: for some time now they have made their extensive CDN available to make our sites fast, offered DDoS protection to make our sites secure, and made their 1.1.1.1 DNS service free so we could afford having privacy on the Internet, among many other services.
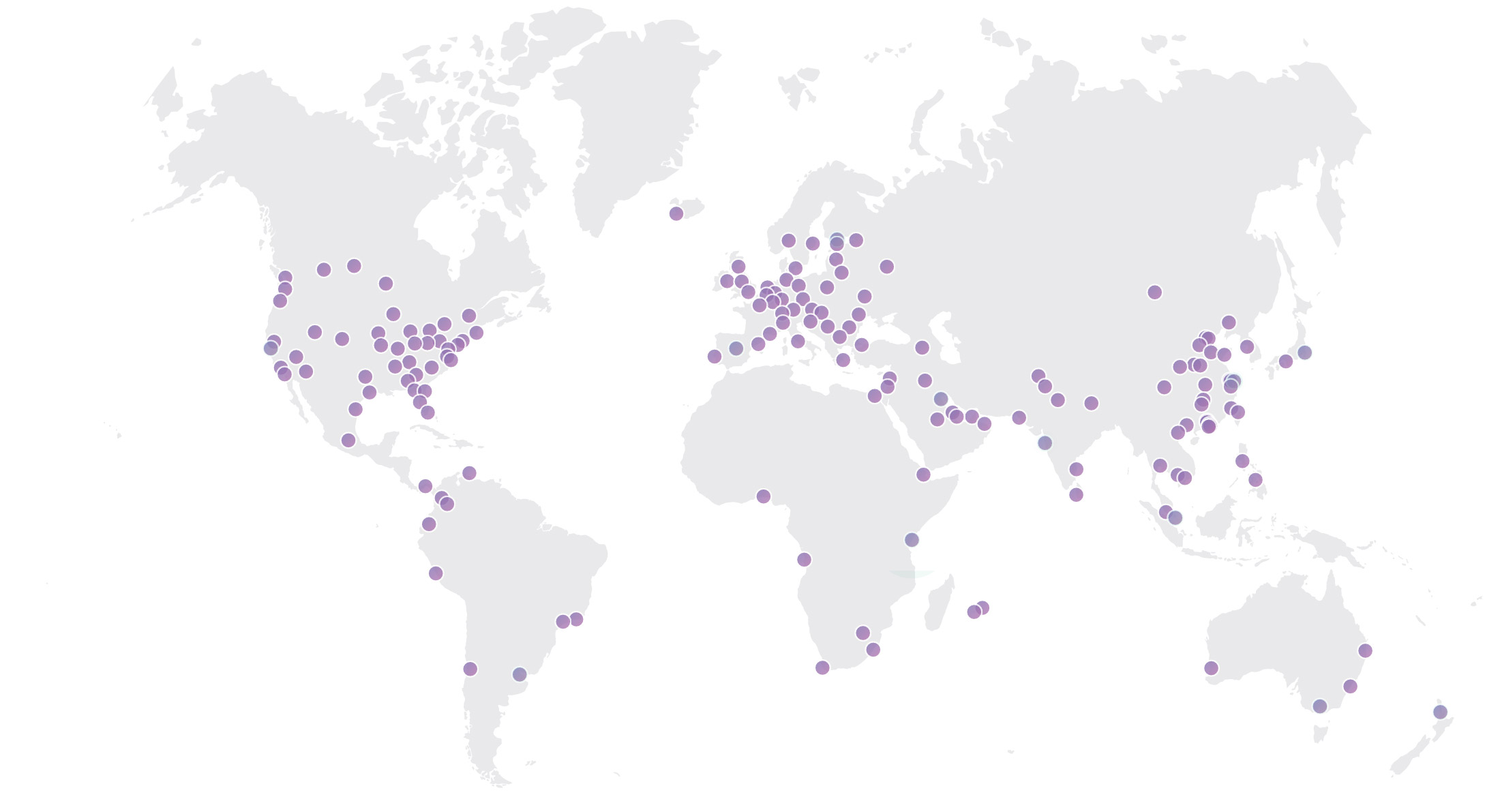
Their new serverless offering, Cloudflare Workers (or simply “Workers”), runs on the same global cloud network of over 165 data centers that powers those services. Cloudflare Workers is a service that provides a lightweight JavaScript execution environment to augment existing applications or create new ones.
Being stacked on top of Cloudflare’s widespread network makes Cloudflare Workers a big deal. Cloudflare can scale up its infrastructure based on spikes in demand, serving a serverless application from locations on five continents and supporting millions of users, making our applications fast, reliable, and scalable.
On top of that, Cloudflare Workers provides unique features that make it an even more compelling service. Let’s explore these in detail.
Architecture Based On V8 For Fast Access And Low Cost
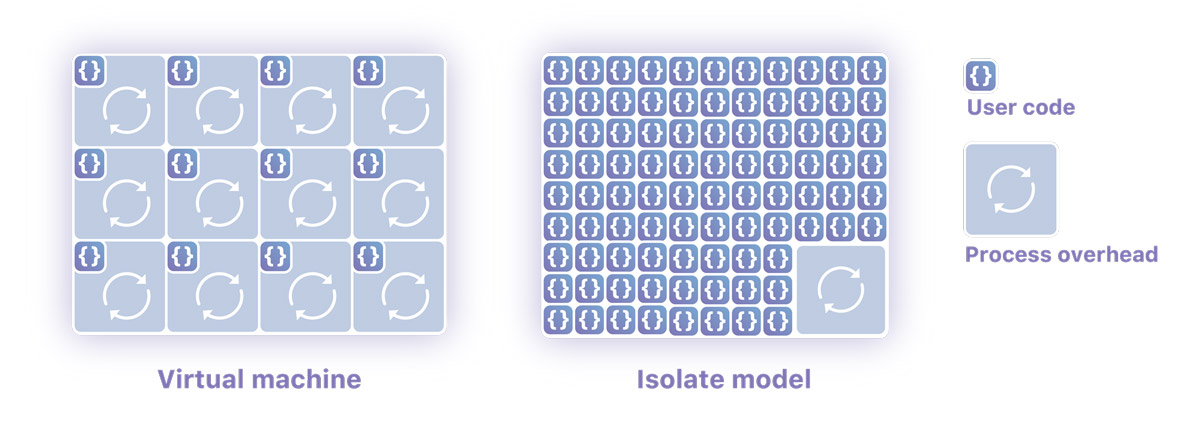
The Cloudflare engineers went out of their way to architect Workers, as they proudly explain in depth. Whereas almost every provider offering cloud computing has an architecture based on containers and virtual machines, Workers uses “Isolates”, the technology that allows V8 (Google Chrome’s JavaScript engine) to run thousands of processes on a single server in an efficient and secure manner.
Compared to virtual machines, Isolates greatly reduce the overhead required to execute user code, which translates into faster execution and lower use of memory.
Cloudflare Workers is not the first serverless cloud computing platform in operation: for instance, Amazon has offered AWS Lambda and Lambda@Edge. However, as a consequence of the lower overhead produced by Isolates, Cloudflare claims that when executing a similar task, Workers beats the competition where it matters most: speed and money.
Lower Price
While a Worker offering 50 milliseconds of CPU costs $0.50 per million requests, the equivalent Lambda costs $1.84 per million. Hence, running Workers ends up being around 3x cheaper than Lambda per CPU-cycle.
Faster Access
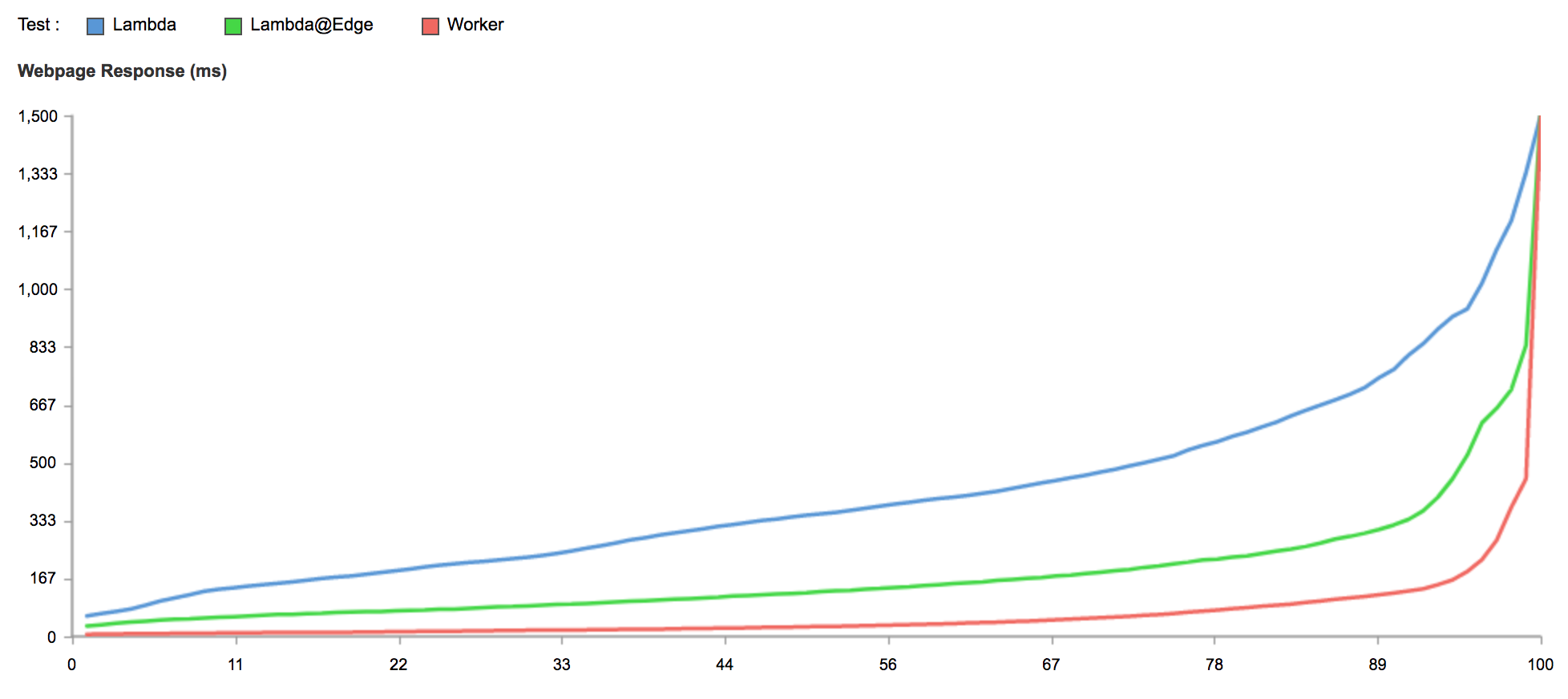
The Cloudflare team ran tests comparing Workers against AWS Lambda and Lambda@Edge, and came to the conclusion that Workers is 441% faster than a Lambda function and 192% faster than Lambda@Edge.
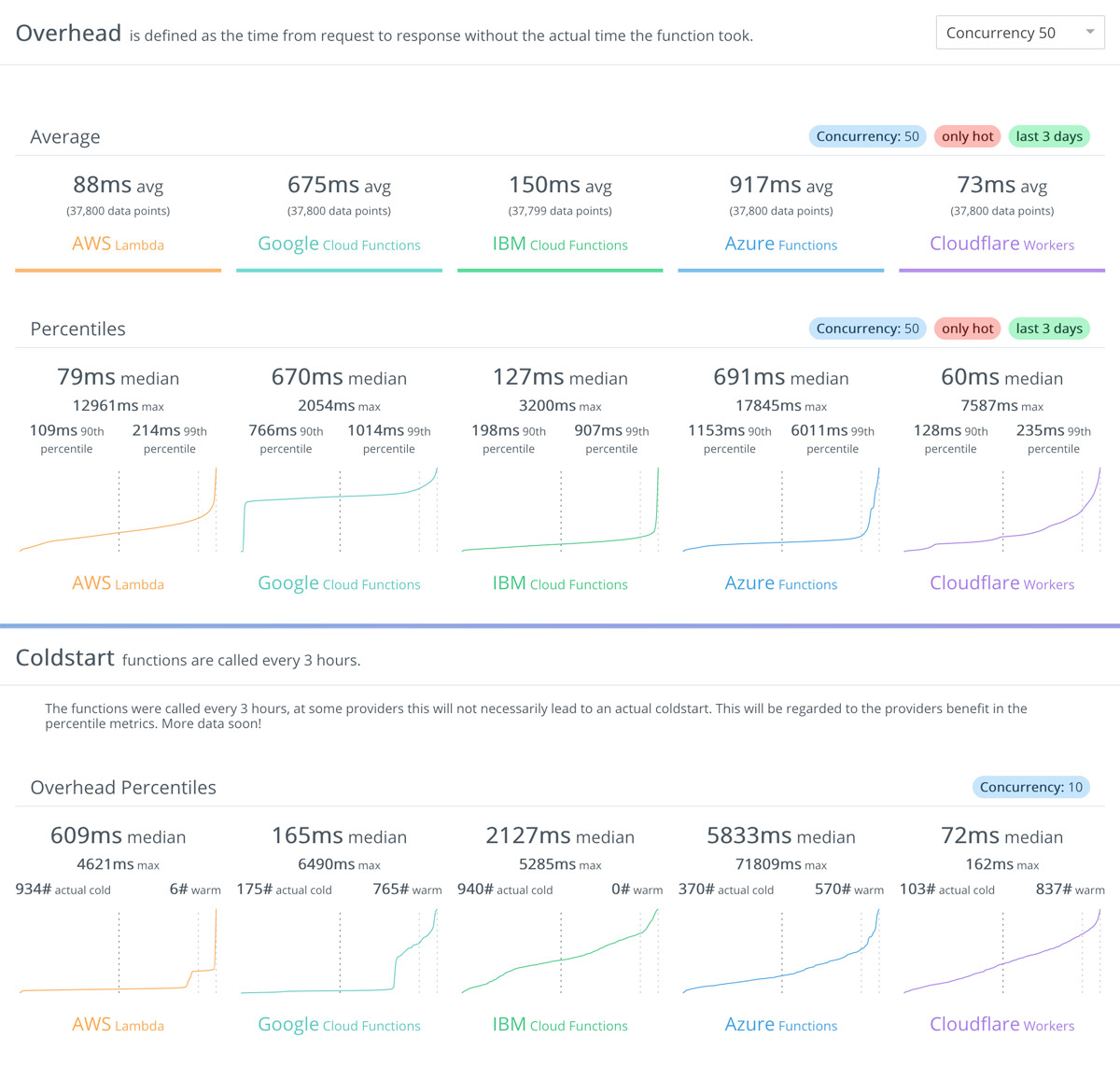
The better performance achieved by Cloudflare Workers is confirmed by the third-party site serverless-benchmark.com, which measures the performance of serverless providers and provides continuously updated statistics.
Coded In JavaScript, Modeled On The Service Workers API
Because it is based on V8, programming for Workers is done in those languages supported by V8: JavaScript and languages that support compilation to WebAssembly, such as Go and Rust. V8’s code is merged into Workers at least once a week, so we can always expect it to support the latest implemented flavor of ECMAScript.
Workers are modeled on the Service Workers available in modern web browsers, and they use the same API whenever possible. This is significant: Because Service Workers are part of the foundation to create a Progressive Web App (PWA), creating Workers is done through an API that developers are already familiar with (or may be in the process of learning) for creating modern web applications.
In addition, relying on the Service Workers API allows developers to boost their productivity since it allows isomorphism of code, i.e. the same code that powers the Service Worker can be used for a Cloudflare Worker. Even though this is not always feasible because of the different contexts (while a Service Worker runs in the browser, the Cloudflare Worker runs in the network), certain use cases could apply to both contexts.
For instance, among the Service Workers recipes described in serviceworke.rs, recipes for API Analytics, Load Balancer, and Dependency Injection can be implemented on both the client side and the network using the same code (or most of it). And even when the functionality makes sense only on either the client-side or the network, it can be partly implemented using chunks of code that are context-agnostic and can be conveniently reused.
Furthermore, using the same API for Service Workers and Cloudflare Workers makes it easy to provide progressive enhancement. An application can execute a Service Worker whenever possible, and fall back on a Cloudflare Worker when the user visits the site for the first time (when the Service Worker is still not installed on the client), or when Service Workers are not supported (for instance, when the browser is old, or it is just Opera mini).
Finally, relying on a unique API simplifies the overall language stack, once again making it easier for the developer to get more work done. For instance, defining a caching policy for the CDN in Varnish is done through the Varnish Configuration Language, which has its own syntax. Cloudflare Workers, though, enables develpers to code the same tasks through, you guessed it, the Service Workers API.
It Leverages The Modern Toolbox
In addition to Workers not requiring developers to learn any new language or API, it follows modern conventions and provides integration with popular technologies, allowing us to use our current toolbox:
- Manage JavaScript dependencies through npm;
- Bundle Worker scripts through Webpack;
- Commit to Github to trigger automatic deployments;
- Automate deployments through the Serverless Framework or through Terraform.
Let’s See Some Practical Examples
It’s time to have fun! Let’s play with some Workers based on common use cases to see how we can augment our sites or even create new ones.
Cloudflare makes available a browser-based testing tool, the Cloudflare Workers Playground. This tool is very comprehensive and easy to use: simply copy the Worker script on the left-side panel, execute it against the URL defined on the top-right bar, see the results on the ‘Preview‘ tab and the source code on the ‘Testing‘ tab (from where we can also add custom headers), and execute console.log inside the script to bring the results on the DevTools on the bottom-right. To share (or also store) your script, you can simply copy your browser’s URL at that point in time.
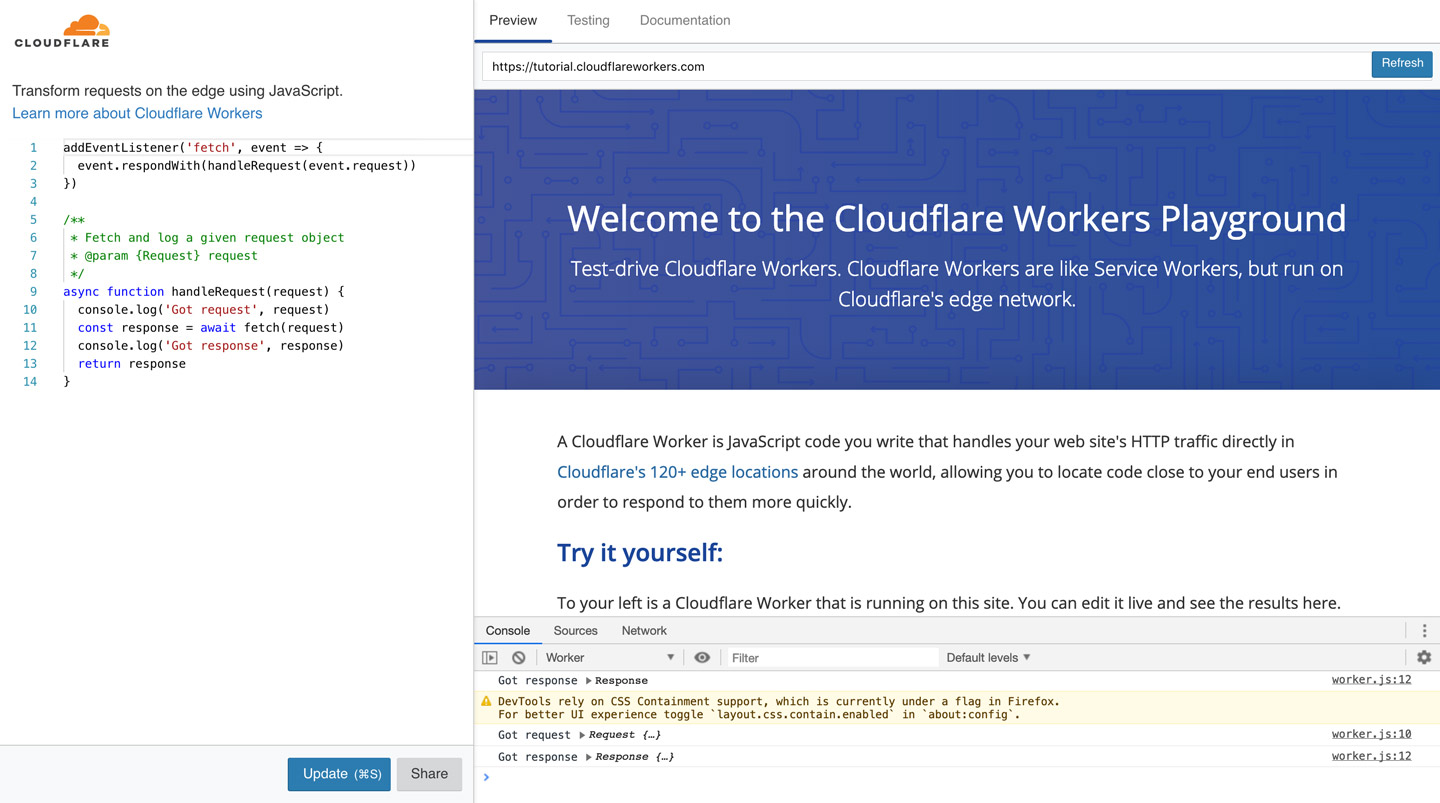
Starting with the Playground will take you far, but, at some point, you will want to test on the actual Cloudflare network and, even better, deploy your scripts for production. For this, your site must be set up with Cloudflare. If you already are a Cloudflare user, simply sign in, navigate to the ‘Workers’ tab on the dashboard, and you are ready to go.
If you are not a Cloudflare user, you can either sign up, or you can request a workers.dev subdomain, under which you will soon be able to deploy your Workers. The workers.dev site is currently accepting reservations of subdomains, so hurry up and reserve yours before it is taken by someone else!

The recipes below have been taken from the Cloudflare Workers Recipe cookbook, from the examples repository in Github, and from the Cloudflare blog. Each example has a link to the script code in the Playground.
Static Site Hosting
The most straightforward use case for Workers is to create a new site, dynamically responding to requests without needing to connect to an origin server at all. So, hello world!
addEventListener('fetch', event => {
event.respondWith(new Response('<html><body><p>Hello world!</p></body></html>'))
})
Instead of printing the HTML output in the script, we can also host static HTML files with some hosting service, and fetch these with a simple Worker script. Indeed, the Worker script can retrieve the content of any file available on the Internet: While the domain under which the Worker is executed must be handled by Cloudflare, the origin website from which the script fetches content does not have to. And this works not just for HTML pages, but also for CSS and JS assets, images, and everything else.
The script below, for instance, renders a page that is hosted under DigitalOcean Spaces:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
const parsedUrl = new URL(request.url)
let path = parsedUrl.pathname
let lastSegment = path.substring(path.lastIndexOf('/'))
if (lastSegment.indexOf('.') === -1) {
path += '/index.html'
}
return fetch("https://cloudflare-example-space.nyc3.digitaloceanspaces.com" + path)
}
Building APIs
A prominent use case for Workers is creating APIs. For instance, the script below powers an API service that states if a domain redirects to HTTPS or not:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
/**
* Fetch a request and follow redirects
* @param {Request} request
*/
async function handleRequest(request) {
let headers = new Headers({
'Content-Type': 'text/html',
'Access-Control-Allow-Origin': '*'
})
const SECURE_RESPONSE = new Response('secure', {status: 200, headers: headers})
const INSECURE_RESPONSE = new Response('not secure', {status: 200, headers: headers})
const NO_SUCH_SITE = new Response('website not found', {status: 200, headers: headers})
let domain = new URL(request.url).searchParams.get('domain')
if(domain === null) {
return new Response('Please pass in domain via query string', {status: 404})
}
try {
let resp = await fetch(`https://${domain}`, {headers: {'User-Agent': request.headers.get('User-Agent')}})
if(resp.redirected == true && resp.url.startsWith('https')) {
return SECURE_RESPONSE
}
else if(resp.redirected == false && resp.status == 502) {
return NO_SUCH_SITE
}
else {
return INSECURE_RESPONSE
}
}
catch (e) {
return new Response(`Something went wrong ${e}`, {status: 404})
}
}
Workers can also connect to several origins in parallel and combine all the responses into a single response. For instance, the script below powers an API service that simultaneously retrieves the price for several cryptocurrency coins:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
/**
* Make multiple requests,
* aggregate the responses and
* send it back as a single response
*/
async function fetchAndApply(request) {
const init = {
method: 'GET',
headers: {'Authorization': 'XXXXXX'}
}
const [btcResp, ethResp, ltcResp] = await Promise.all([
fetch('https://api.coinbase.com/v2/prices/BTC-USD/spot', init),
fetch('https://api.coinbase.com/v2/prices/ETH-USD/spot', init),
fetch('https://api.coinbase.com/v2/prices/LTC-USD/spot', init)
])
const btc = await btcResp.json()
const eth = await ethResp.json()
const ltc = await ltcResp.json()
let combined = {}
combined['btc'] = btc['data'].amount
combined['ltc'] = ltc['data'].amount
combined['eth'] = eth['data'].amount
const responseInit = {
headers: {'Content-Type': 'application/json'}
}
return new Response(JSON.stringify(combined), responseInit)
}
Making the API highly dynamic by retrieving data from a database is covered too! Workers KV is a global, low-latency, key-value data store. It is optimized for quick and frequent reads, and data should be saved sparingly. Then, it is a sensible approach to input data through the Cloudflare API:
curl "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/storage/kv/namespaces/$NAMESPACE_ID/values/first-key" \
-X PUT \
-H "X-Auth-Email: $CLOUDFLARE_EMAIL" \
-H "X-Auth-Key: $CLOUDFLARE_AUTH_KEY" \
--data 'My first value!'
And then the values can be read from within the Worker script:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
const value = await FIRST_KV_NAMESPACE.get("first-key")
if (value === null)
return new Response("Value not found", {status: 404})
return new Response(value)
}
At the time of writing, KV is still in beta and released only to beta testers. If you are interested in testing it out, you can reach out to the Cloudflare team and request access.
Geo-Targeting
Cloudflare detects the origin IP of the incoming request and appends a two-letter country code to header ‘Cf-Ipcountry’. The script below reads this header, obtains the country code, and then redirects to the corresponding site version if it exists:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
const country = request.headers.get('Cf-Ipcountry').toLowerCase()
let url = new URL(request.url)
const target_url = 'https://' + url.hostname + '/' + country
const target_url_response = await fetch(target_url)
if(target_url_response.status === 200) {
return new Response('', {
status: 302,
headers: {
'Location': target_url
}
})
} else {
return fetch(request)
}
}
A similar approach can apply to implement load balancing, choosing from among multiple origins to improve speed or reliability.
Enhanced Security
The scripts below add security rules and filters to block unwanted visitors and bots.
Ignore the POST and PUT HTTP requests:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
if (request.method === 'POST' || request.method === 'PUT') {
return new Response('Sorry, this page is not available.',
{ status: 403, statusText: 'Forbidden' })
}
return fetch(request)
}
Deny a spider or crawler:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
if (request.headers.get('user-agent').includes('annoying_robot')) {
return new Response('Sorry, this page is not available.',
{ status: 403, statusText: 'Forbidden' })
}
return fetch(request)
}
Prevent a specific IP from connecting:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
if (request.headers.get('cf-connecting-ip') === '225.0.0.1') {
return new Response('Sorry, this page is not available.',
{ status: 403, statusText: 'Forbidden' })
}
return fetch(request)
}
A/B Testing
We can easily create a Worker to control A/B tests:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
const name = 'experiment-0'
let group // 'control' or 'test', set below
let isNew = false // is the group newly-assigned?
// Determine which group this request is in.
const cookie = request.headers.get('Cookie')
if (cookie && cookie.includes(`${name}=control`)) {
group = 'control'
} else if (cookie && cookie.includes(`${name}=test`)) {
group = 'test'
} else {
// 50/50 Split
group = Math.random() < 0.5 ? 'control' : 'test'
isNew = true
}
// We'll prefix the request path with the experiment name. This way,
// the origin server merely has to have two copies of the site under
// top-level directories named "control" and "test".
let url = new URL(request.url)
// Note that `url.pathname` always begins with a `/`, so we don't
// need to explicitly add one after `${group}`.
url.pathname = `/${group}${url.pathname}`
request = new Request(url, request)
let response = await fetch(request)
if (isNew) {
// The experiment was newly-assigned, so add a Set-Cookie header
// to the response. We need to re-construct the response to make
// the headers mutable.
response = new Response(response.body, response)
response.headers.append('Set-Cookie', `${name}=${group}; path=/`)
}
return response
}
Serving Device-Based Content
The script below delivers different content based on the device being used:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
let uaSuffix = ''
const ua = request.headers.get('user-agent')
if (ua.match(/iphone/i) || ua.match(/ipod/i)) {
uaSuffix = '/mobile'
} else if (ua.match(/ipad/i)) {
uaSuffix = '/tablet'
}
return fetch(request.url + uaSuffix, request)
}
Conditional Routing
By passing custom values through headers, we can fetch most-specific content:
addEventListener('fetch', event => {
event.respondWith(fetchAndApply(event.request))
})
async function fetchAndApply(request) {
let suffix = ''
//Assuming that the client is sending a custom header
const cryptoCurrency = request.headers.get('X-Crypto-Currency')
if (cryptoCurrency === 'BTC') {
suffix = '/btc'
} else if (cryptoCurrency === 'XRP') {
suffix = '/xrp'
} else if (cryptoCurrency === 'ETH') {
suffix = '/eth'
}
return fetch(request.url + suffix, request)
}
Enhanced Performance
Workers makes available a Cache API through which we can save computationally intensive data and have it ready for immediate use from then on:
async function handleRequest(event) {
let cache = caches.default
let response = await cache.match(event.request)
if (!response) {
response = doSuperComputationallyHeavyThing()
event.waitUntil(cache.put(event.request, response.clone()))
}
return response
}
For instance, through the Cache API we can store GraphQL requests whose results have not changed:
async function handleRequest(event) {
let cache = caches.default
let response = await cache.match(event.request)
if (!response){
response = await fetch(event.request)
if (response.ok) {
event.waitUntil(cache.put(event.request, response.clone()))
}
}
return response
}
Many Others
The list of useful applications goes on and on. Below are links to several additional examples:
- Caching WordPress (or other CMS) pages in Cloudflare’s CDN
- Improving the Performance of Google Fonts
- Improving HTML Time to First Byte
- JWT Authentication
- Implementation of a Slackbot
Wrapping Up: “The Network Is The Computer”
Because speed matters, websites are going serverless. Cloudflare Workers is a new offering that enables this transition. It blurs the boundaries between the computer and the network, enabling developers to deploy apps globally that run on the fabric of the Internet itself, leveraging Cloudflare’s worldwide network of servers to run our code near where our users are located. It is fast, cheap, and secure, and it scales as much as we need it.
If you want to find out more, check it out or ask the community.
Further Reading
- The Case For Prisma In The Jamstack
- Advanced GraphQL Usage In Gatsby Websites
- Building An API With Gatsby Functions
- Switching From Adobe Fireworks To Sketch: Ten Tips And Tricks