Build A Seamless Spreadsheet Import Experience With The Help Of Flatfile

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
This article has been kindly supported by our dear friends at Flatfile who create beautiful, human-centric experiences to remove the barriers between people and data. Thank you!
If you’ve ever attempted to build a CSV importer before, you know how frustrating it is to dedicate valuable engineering time to this feature, only to watch your customers struggle with it.
In some cases, developers try to improve this experience by providing users with FAQs and tutorials that show them how to correctly use their importer. However, this merely shifts the burden from the product onto the user. The last thing users want is to sift through lengthy documentation or video tutorials to upload a simple spreadsheet.
Should it be your users’ job to figure out why your importer isn’t working correctly?
If you want to improve the experience users have with your product or service, you have to start with optimizing the experience of importing the data itself. Users rely on your product to extract value from it. Asking them to use a spreadsheet template, or to match their fields before they’ve even uploaded a file to your app is detrimental to their product experience and your team’s resources.
Investing developer time to fix an existing data importer, or worse, building a CSV importer from scratch is a huge strain on resources. Let’s look at Flatfile, which enables developers to integrate a robust CSV importer experience in as little as one day.
Common Problems With Typical CSV Import Experiences
Data import is often one of the first interactions users have with an app. Unfortunately, there are too many ways that this import feature can cause frustration.
For your users, an inefficient importer experience will cause them to wonder whether the product itself is worth using.
"If the app can’t import my data easily, what the heck is going to happen once my data is finally uploaded?"
{kind=link}
An inefficient data importer strains internal resources. Not only have you invested significant time trying to build what is essentially a second product for your app, now you’re spending time dealing with:
- Emails and support tickets from frustrated users who can’t upload their data into your system.
- Broken data, which your team has to manually clean before it’s usable in your database.
- A never-ending string of inconsistent file uploads, due to lack of data normalization.
This is generally not a good position to be in, as users expect a seamless product experience from start to finish.
Worse, all that effort you spent building your importer could have been dedicated to building core product features your users need.
One of Flatfile’s clients spoke to them about the pain of building and maintaining a proprietary data importer for their real estate product. The client’s engineers spent about eight to ten hours per user, cleaning up and formatting incoming data. Sometimes these users would churn, wasting valuable development time.
There is no point in building a custom feature that’s supposed to automate and streamline the import experience. Ultimately, this sets you up for maintenance headaches down the road with features that won’t scale with your product.
Wouldn’t it be better if there was an out-the-box CSV importer that could do this on its own?
Flatfile is what you need.

{kind=link}
Let’s look at some ways that importing data has gone awry and how it can be fixed when you let Flatfile do the heavy lifting.
Issue 1: Unclear Guidance
In some cases, users struggle with your data importer because they have no idea what to do with it. Here are some questions they may ask during a CSV import:
- Does it accept XLS, XLSX, or XML file formats?
- What do I do if my file is 97MB in size?
- What if my file has special characters?
- What happens if my columns don’t match?
- How do I fix my data? Do I need to save a duplicate CSV and upload that file instead?
- Can I update any incorrect data during import?
- Do I need to download a template?
Unfortunately, unless your users are tech-savvy and spend a lot of time exporting and importing spreadsheets, they’re not going to think about these things until they’re ready to provide their data.
It shouldn’t be up to your users to read through or watch a 15-minute tutorial on how to import spreadsheets into your product. Developers aren’t spared either. Although engineers understand the complexities of importing data into an advanced system (like Microsoft Azure), there is still an exhaustive amount of content they need to understand before the first import even happens.

Your data import experience should make it simple to upload CSV data without requiring users to take a mini course on it. The same goes for your understanding of how to build it.
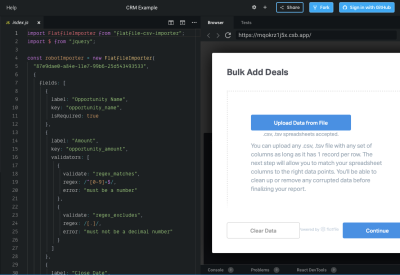
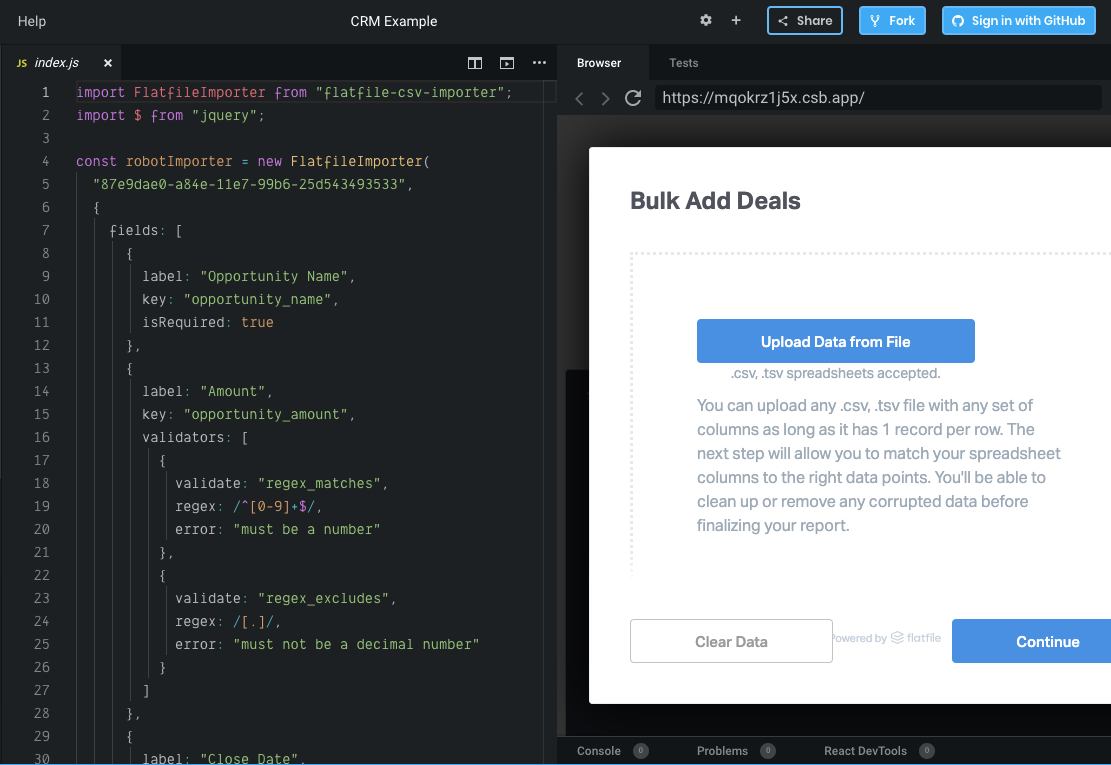
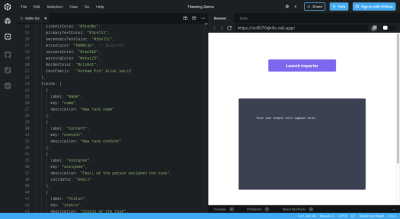
Here is an example of a simplified CSV import solution for a CRM from Flatfile (you can ignore the code on the left-hand side for now):
{kind=link}
Notice how the preview of the importer shows a welcoming, yet basic setup. Your users would instantly know to:
- Upload their data as a CSV or XLS.
- Match their spreadsheet columns in the next step, if needed.
- Click “Continue” to begin the CSV upload.
Part of this is because the standardized UI presents no obstacles while the synchronous guidance prepares users for what’s to come. This way, users won’t worry right off the bat if their data will be imported incorrectly.
Issue 2: Maxed-Out Browser Memory Limits
Let’s assume that your users have successfully exported their data from another system or compiled it into a CSV file on their own. Then, they initiate an upload using your product’s data importer.
However, after watching the upload progress for what feels like an eternity, they receive the dreaded “Upload Failed” message. This isn’t all that uncommon with traditional or self-made data importers.
It’s often why online forums and website support centers contain question-and-answer like this one on the Go1 website:
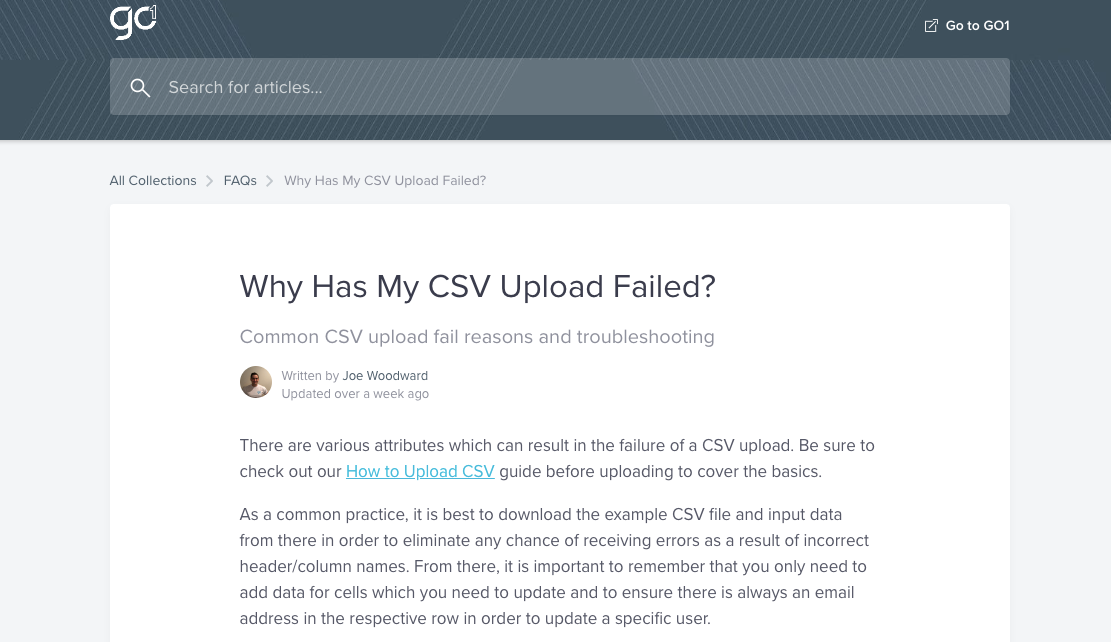
Or this one on the Nimble website:
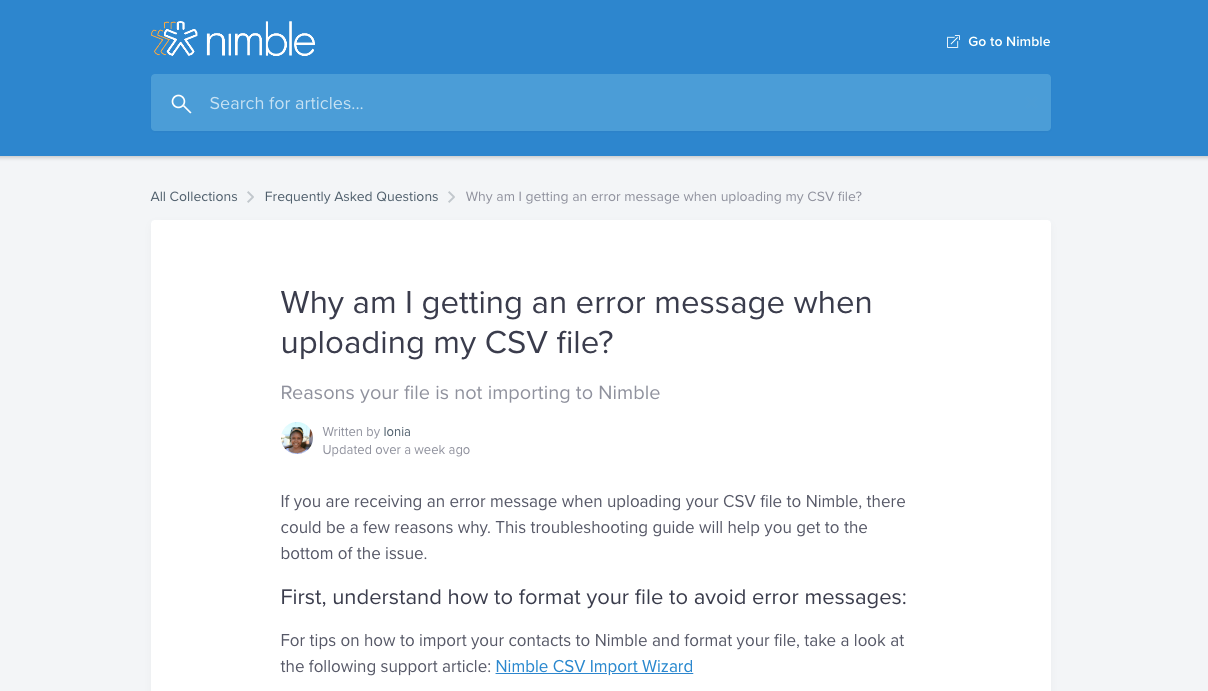
Or this one from Nurture’s knowledgebase:
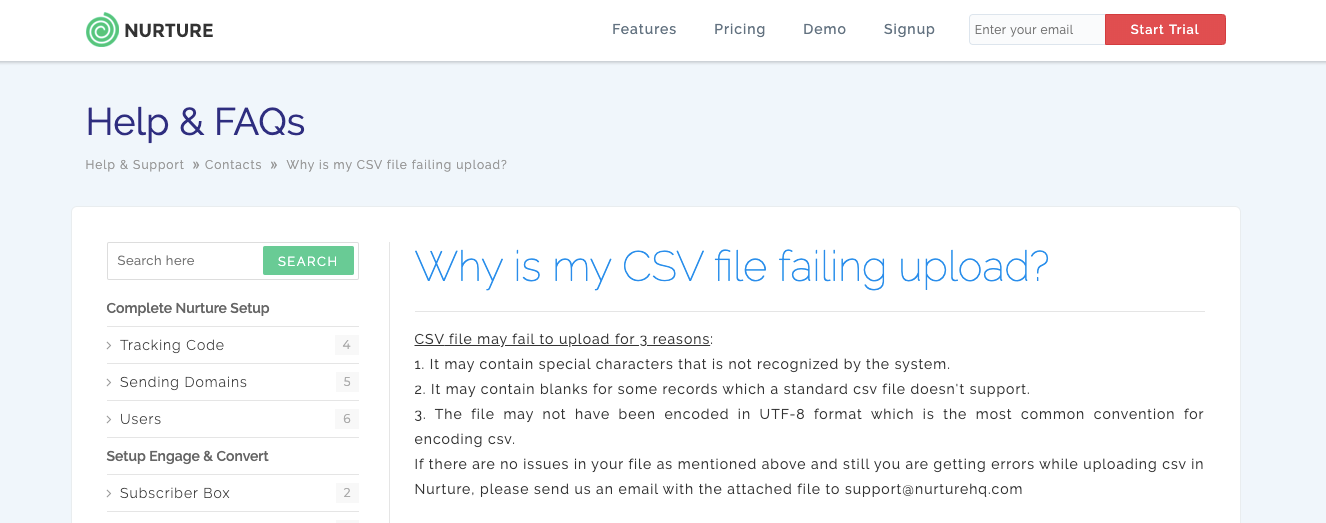
Ultimately, it falls to your users to:
- Accept that CSVs have a tendency to fail.
- Debug what causes a failed CSV upload.
- Figure out how to trim back their file size, rearrange their file, or download and use the product’s template in order to complete an upload.
Why should it be up to your users to figure out why your data importer failed? Shouldn’t you be the one to sort out the disconnect? Or, better yet, to build an importer that works without issue?
With Flatfile, you and your users won’t have to worry about things like file sizes or formats causing problems during import. For example, Flatfile helps you manage imported data via the browser or through a server-side process, enabling you to upload large CSV files without bothering your users. Another solution provided by Flatfile comes in the form of file-splitting.
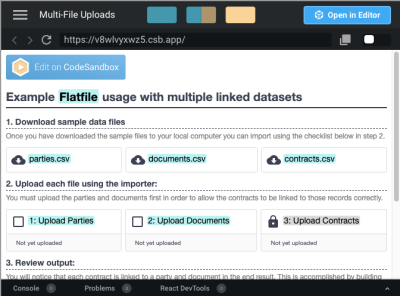
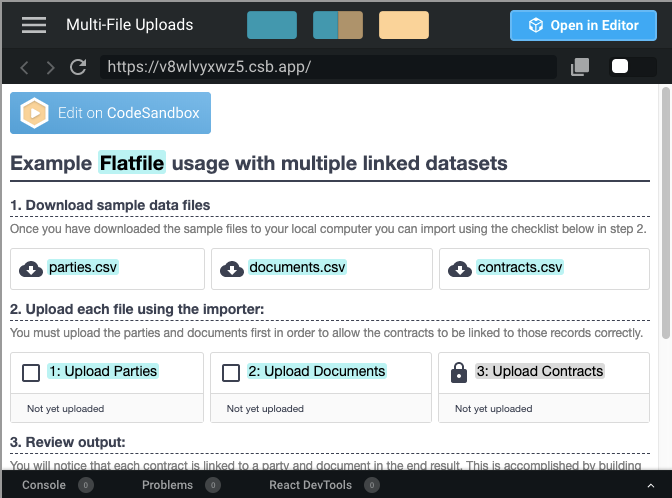{kind=link}
Flatfile allows users to import CSV data from multiple files intuitively, without dropping data or doing manual splitting.
In this demo, users are allowed to upload CSV files containing three different sets of data. Not only will this help make their files more manageable, but it’ll make it much easier for your product to ingest and organize the data on your backend.
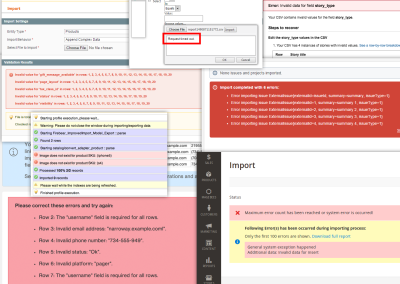
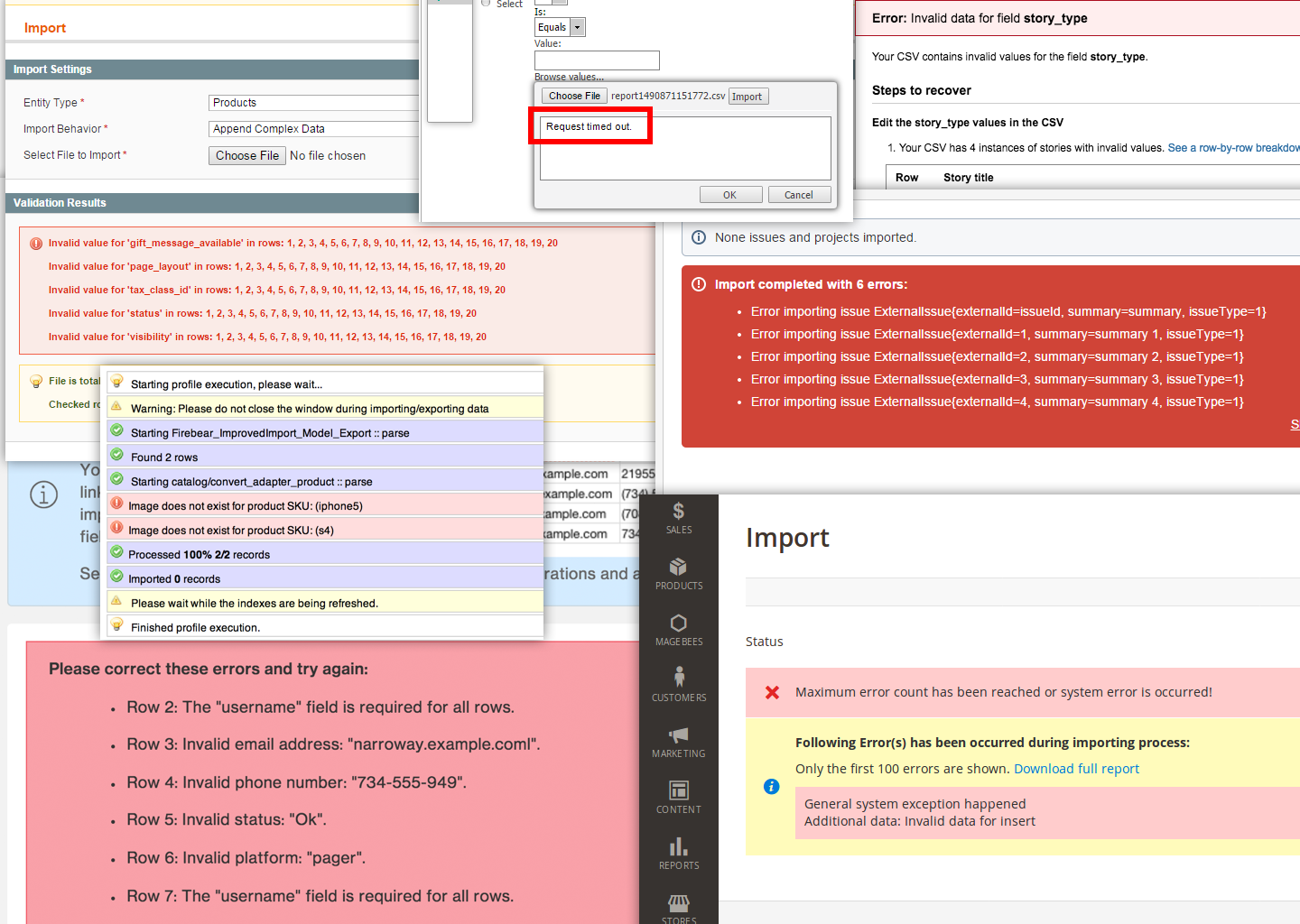
Issue 3: Vague Errors
It’s not just vague upload instructions or stalled imports that are going to give your users a headache.
When the error message is vague, what is the user supposed to do with that? Without a specific explanation of the problem, your users are going to be stuck having to work through every possible fix until they find one that works (if any).
Take this reported issue with Jira:
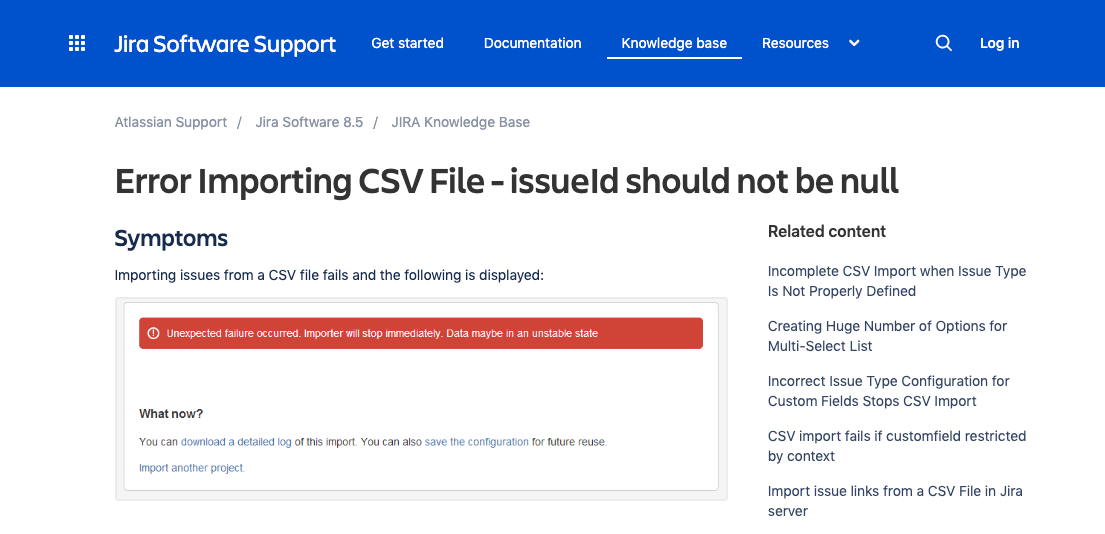
The full error message reads:
"Unexpected failure occurred. Importer will stop immediately. Data may be in an unstable state."
That’s not helpful. So, not only does the developer see a message calling their data “unstable”, but now they have to work through the issue from the scant details provided on this help page. The answer actually includes this as an explanation, which we can assume is only going to add to the frustration:
"This happens because the JIRA Importers Plugin tries to validate if the issues are valid for importing, and when the validation fails the error above is thrown."
Essentially, the plugin is incapable of recognizing “Required” fields outside of the ones it deems as required. But rather than transmit that message in the importer, users have to figure that out from this resource.
Not only is there no explanation for why the CSV upload failed, but it then suggests that the data importer might’ve just goofed up (which won’t reflect well on your product experience). Chances are the importer isn’t going to accept the same file twice, so why bother suggesting a retry?
It’s not your users’ job to think here. CSV importers should be designed — error messages and all — to make this a quick and painless experience for your users.
Issue 4: Mapping Is Inefficient
The next source of frustration often appears when poor column-matching functionality is in place.
As an example, let’s say that a MailChimp user wants to load as many contact details into the email marketing software as they want. After all, it might be useful to have their business title or phone number on hand for future list segmentation.
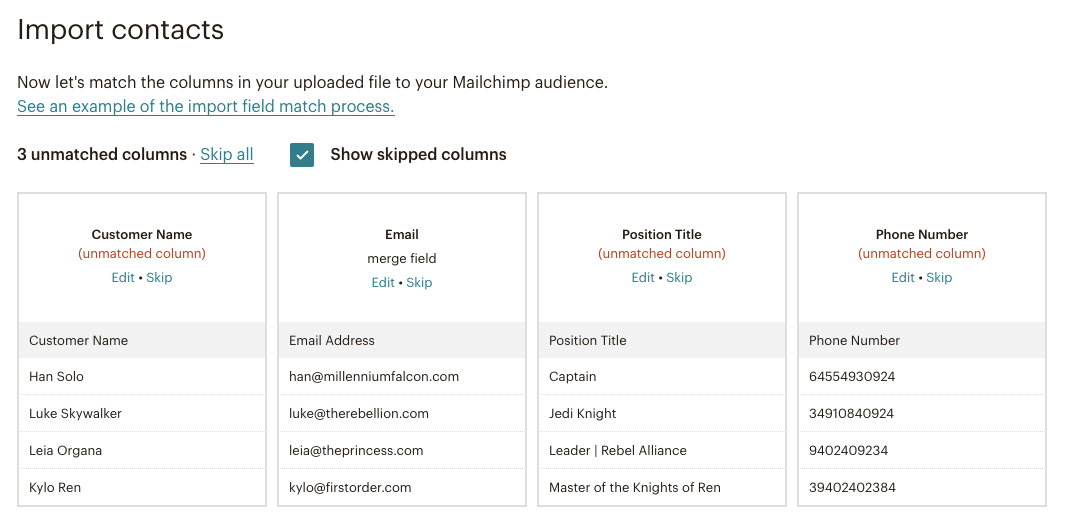
The app doesn’t recognize three of the four columns in our file. In order to keep the unmatched column data, the user has to go through each field and manually assign a matching label that MailChimp accepts.
In this case, the only column that can be edited and matched is “Customer Name”. In this example, the user is going to lose the rest of their data.
We know what you’re thinking: “Why not just provide a pre-built spreadsheet template?” However, this is hardly a solution to the problem and will only create more work and frustration for your users.
The problem here lies within the product experience, not the user.
Historically, this has been a difficult and expensive project to take on, but that’s where Flatfile’s machine-learning, column-matching solution comes in handy.
ClickUp, powered by Flatfile, has leveraged this for its productivity web app.
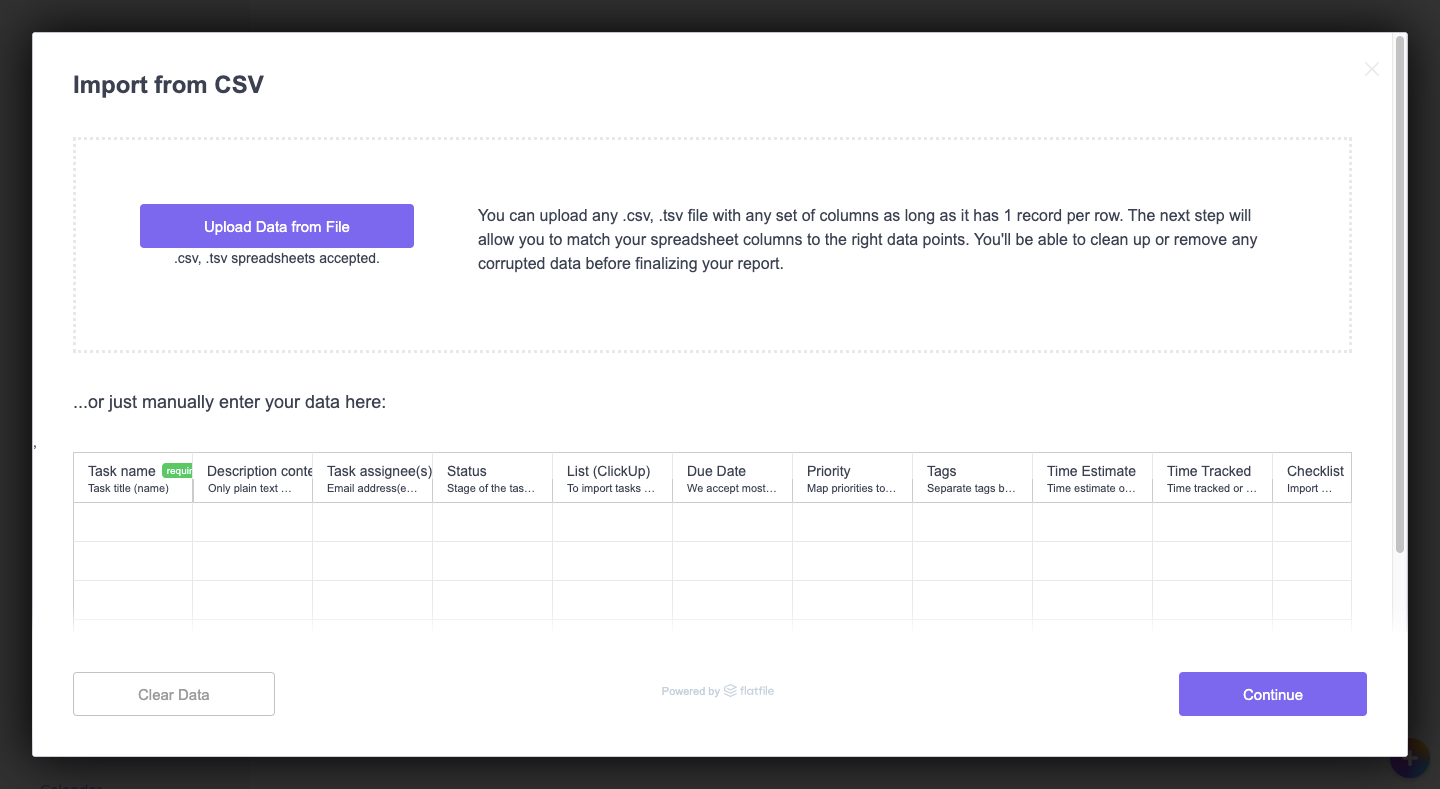
For starters, this import modal is really well designed. Instructions are clearly provided as to what the user can upload. In addition, the manual option lets users preview what sort of data can be imported into the productivity software. This helps users preserve as much data as possible, rather than realize too late that the data importer didn’t recognize their columns and dropped the data out without any notice.
Flatfile streamlines column-matching as well:
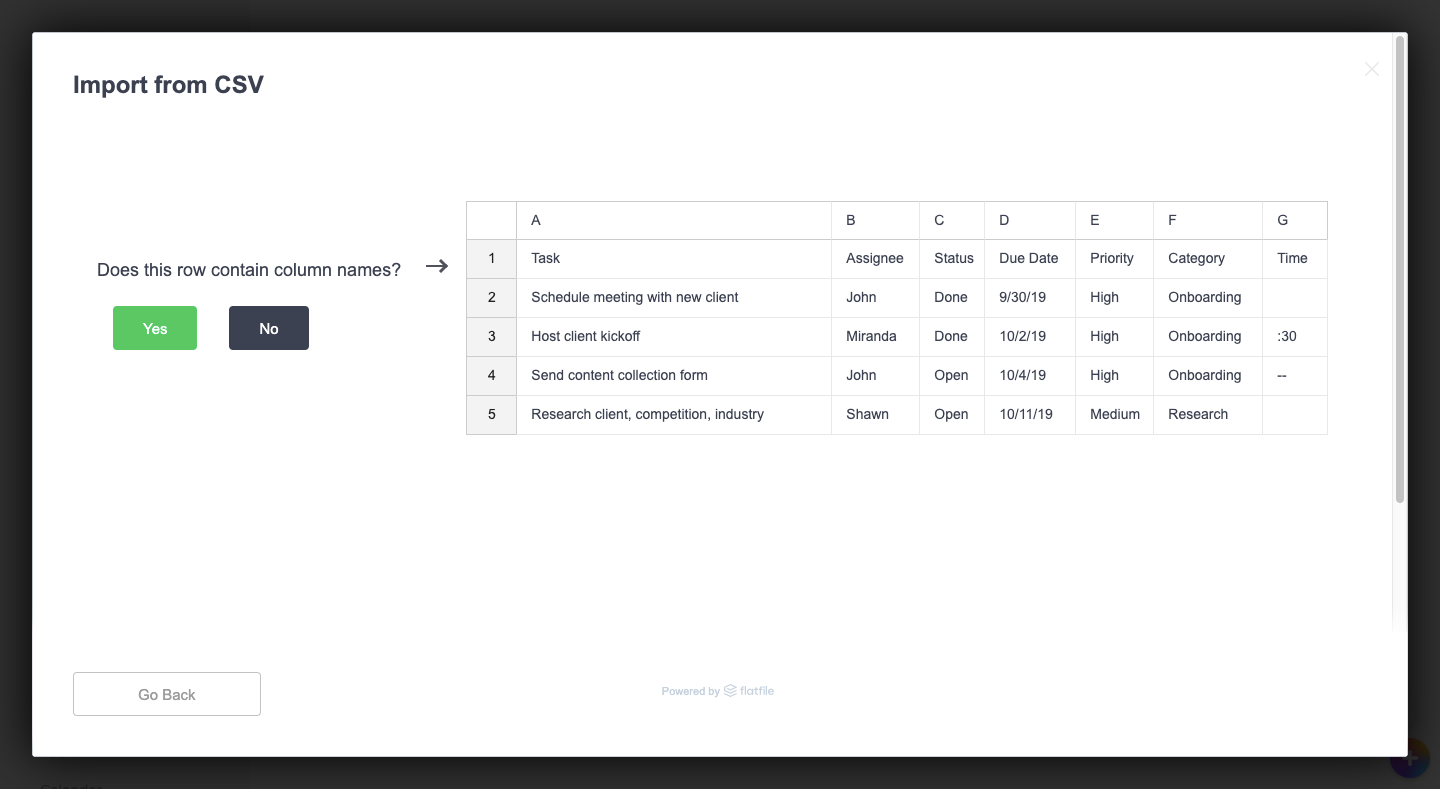
This step asks users to indicate where their column names live. This way, the importer can more effectively match them with its own or add labels if they’re missing.
Next, users get a chance to confirm or reject Flatfile’s column matching suggestions:
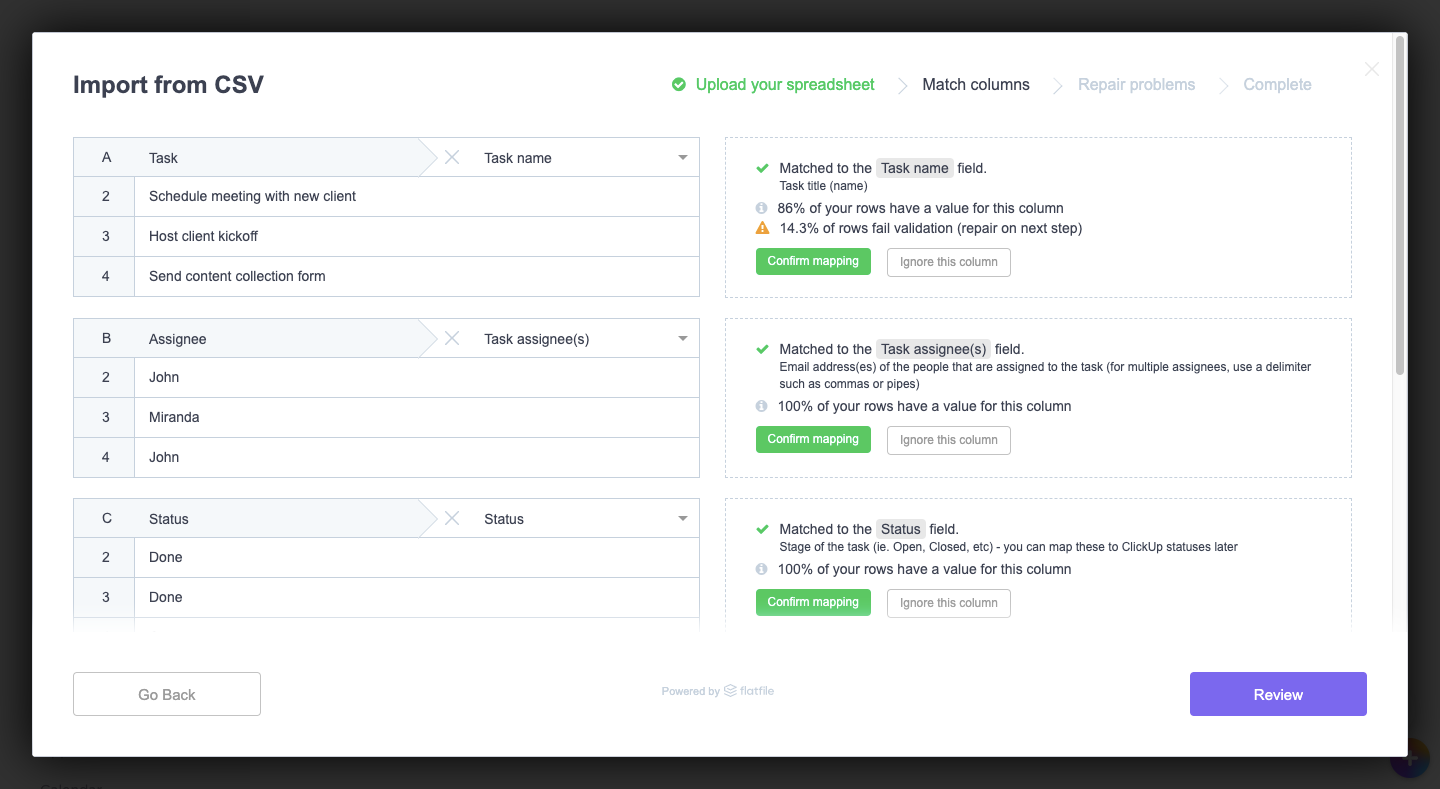
On the left, they’ll find the columns and labels they imported. The white tab to the right provides them with automated column matching for ClickUp. So, “Task” will become “Task name”, “Assignee” will become “Task assignee(s)”, “Status” remains as is and so on.
If one of the labels in the CSV doesn’t have any match at all, the importer calls attention to it like this:
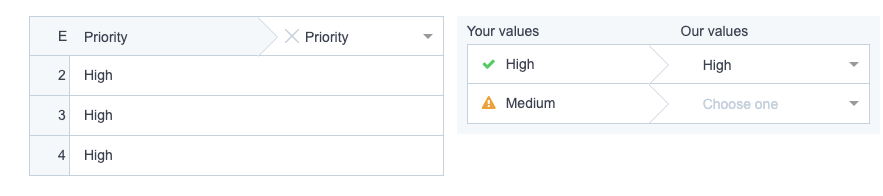
In this example, the Priority response of “High” was detected. But “Medium” was not. However, there’s no need for the user to guess what the correct replacement should be. The importer provides relevant options like “Urgent”, “Normal” and “Low” to replace it with.
Once all spreadsheet labels have been resolved, the user can easily “Confirm Mapping” or discard the column altogether if it’s proven unnecessary.

Finally, users get a chance to review any errors detected with their data:
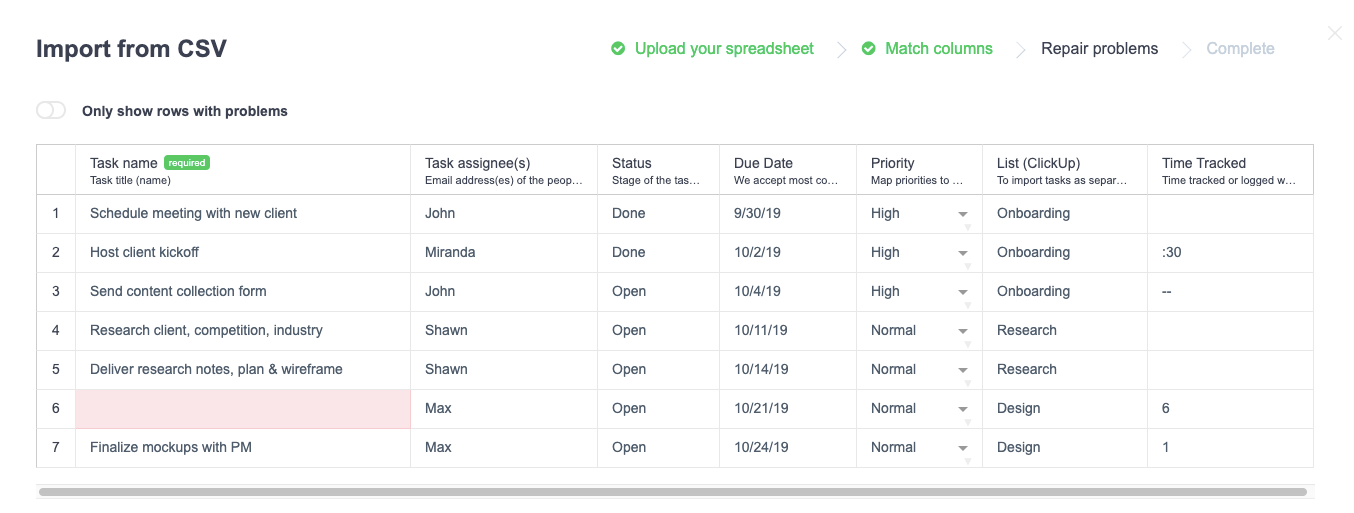
Flatfile highlights required fields that are empty, contain an obvious error or divert from the data model ClickUp specified in their back-end.
The user can rely on Flatfile’s detection system to find those import errors. The “Only show rows with problems” toggle in the left-hand corner makes it even easier to spot.
This keeps users from having to:
- Review the original CSV file and fix errors before re-importing again.
- Import the data and do the cleanup afterwards in the app.
How do you set up this system of column-mapping and error detection? Flatfile does most of the work for you.

{kind=link}
Flatfile is configured via a JSON code snippet. Any fields or labels you specify in this code will be reflected in the importer. This allows for column-matching and even complex validation for things like normalizing phone numbers or date formats:
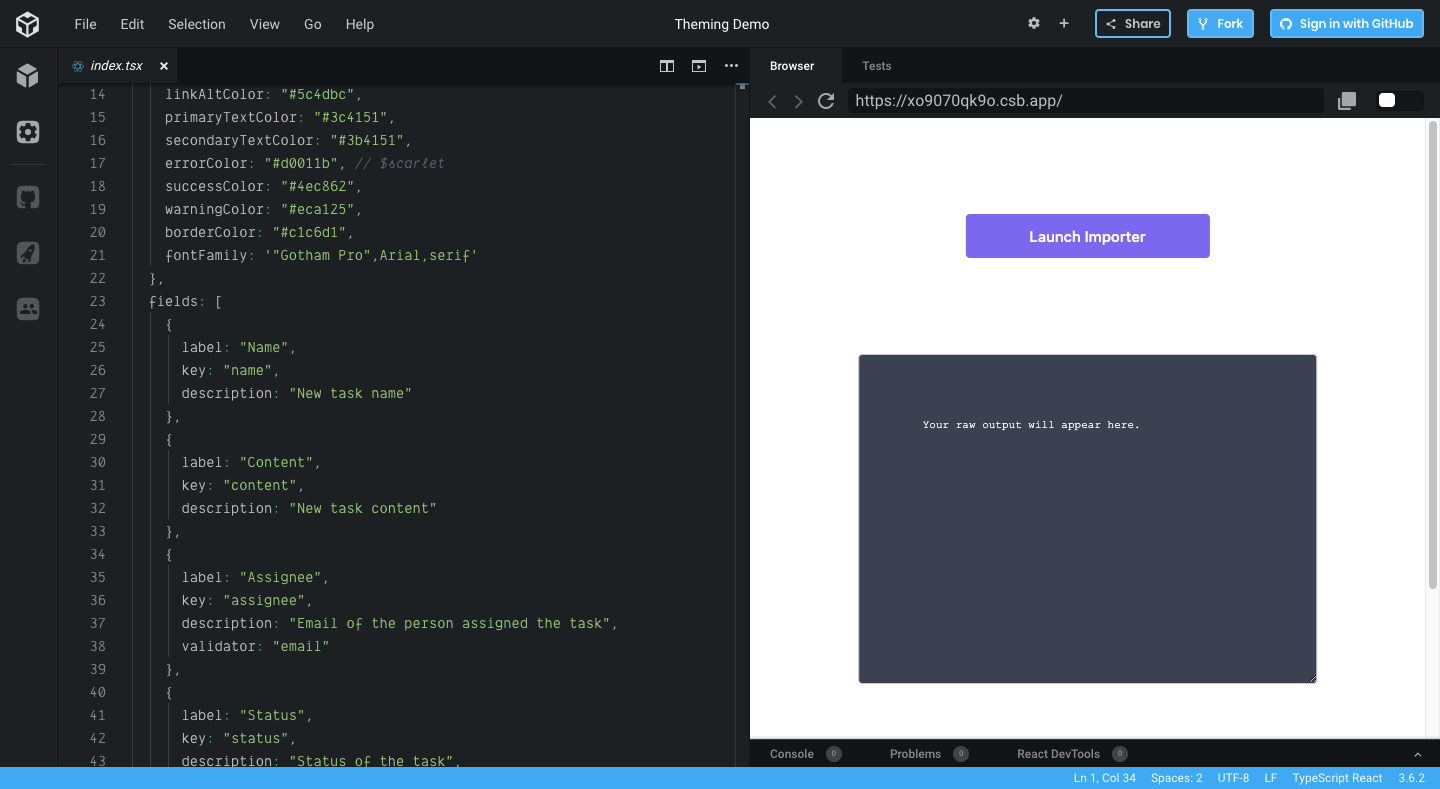{kind=link}
Flatfile has already been coded for you. You just need to align your data model with what you expect your users to import into your product.
Here’s a JSON snippet you might use to customize the Flatfile importer for a basic contact list:
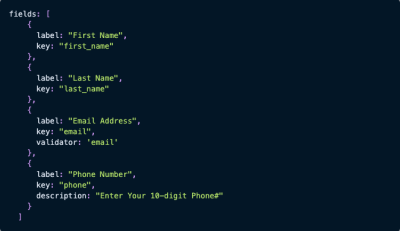
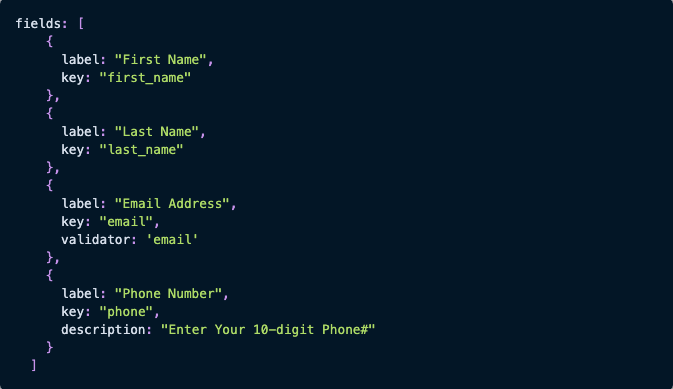{kind=link}
You can then use validators to set strict rules for what can appear in the corresponding fields:
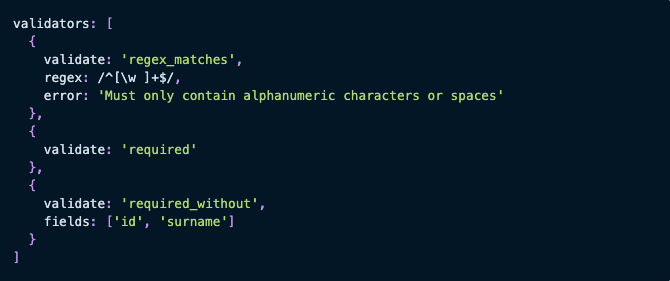
Bottom line:
It’s not easy building a data importer yourself. Integrating Flatfile allows you to focus on other core features of your product’s experience, knowing that the CSV import experience is taken care of.
Wrapping Up
One of the reasons we build SaaS products is so users can effectively manage their businesses without the costly overhead of outsourcing to a third party or the costly practice of trying to implement everything themselves.
However, just because you know how to build a feature that addresses those needs, doesn’t mean you should, or want to, build an importer.
Of all the things that can stand in the way of you getting and retaining users in your app, don’t let something like importing data be the reason for customer frustration or churn. You can see how easy it is for users to become soured on the slightest inconvenience with common CSV import errors. Take advantage of a tool like Flatfile whose sole focus is designing faster and more seamless CSV import experiences for your users, teams and products.
Further Reading
- Event Calendars For Web Made Easy With These Commercial Options
- How To Improve Your Microcopy: UX Writing Tips For Non-UX Writers
- Transforming The Relationship Between Designers And Developers
- Frequently Heard In My Beginning Front-End Web Development Class