Choosing A New Serverless Database Technology At An Agency (Case Study)

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
This article has been kindly supported by our dear friends at Fauna who make working with operational data productive, scalable and secure for every software development team. Thank you!
Adopting a new technology is one of the hardest decisions for a technologist in a leadership role. This is often a large and uncomfortable area of risk, whether you are building software for another organization or within your own.
Over the last twelve years as a software engineer, I’ve found myself in the position of having to evaluate a new technology at increasing frequency. This may be the next frontend framework, a new language, or even entirely new architectures like serverless.
The experimentation phase is often fun and exciting. It is where software engineers are most at home, embracing the novelty and euphoria of “aha” moments while grokking new concepts. As engineers, we like to think and tinker, but with enough experience, every engineer learns that even the most incredible technology has its blemishes. You just haven’t found them yet.
Now, as the co-founder of a creative agency, my team and I are often in a unique position to use new technologies. We see many greenfield projects, which become the perfect opportunity to introduce something new. These projects also see a level of technical isolation from the larger organization and are often less burdened by prior decisions.
That being said, a good agency lead is entrusted to care for someone else’s big idea and deliver it to the world. We have to treat it with even more care than we would our own projects. Whenever I’m about to make the final call on a new technology I often ponder this piece of wisdom from the co-founder Stack Overflow Joel Spolski:
“You have to sweat and bleed with the thing for a year or two before you really know it’s good enough or realize that no matter how hard you try you can’t...”
This is the fear, this is the place that no tech lead wants to find themselves in. Choosing a new technology for a real-world project is hard enough, but as an agency, you have to make these decisions with someone else’s project, someone else’s dream, someone else’s money. At an agency, the last thing you want is to find one of those blemishes near the deadline for a project. Tight timelines and budgets make it nearly impossible to reverse course after a certain threshold is crossed, so finding out a technology can’t do something critical or is unreliable too late into a project can be catastrophic.
Throughout my career as a software engineer, I’ve worked at SaaS companies and creative agencies. When it comes to adopting a new technology for a project these two environments have very different criteria. There is overlap in criteria, but by and large, the agency environment has to work with rigid budgets and rigorous time constraints. While we want the products we build to age well over time, it’s often more difficult to make investments in something less proven or to adopt technology with steeper learning curves and rough edges.
That being said, agencies also have some unique constraints that a single organization may not have. We have to bias for efficiency and stability. The billable hour is often the final unit of measurement when a project is complete. I’ve been at SaaS companies where spending a day or two on setup or a build pipeline is no big deal.
At an agency, this type of time cost puts strain on relationships as finance teams see narrowing profit margins for little visible results. We also have to consider the long-term maintenance of a project, and conversely what happens if a project needs to be handed back off to the client. We therefore must bias for efficiency, learning curve, and stability in the technology we choose.
When evaluating a new piece of technology I look at three overarching areas:
- The Technology
- The Developer Experience
- The Business
Each of these areas has a set of criteria I like met before I start really diving into the code and experimenting. In this article, we’ll take a look at these criteria and use the example of considering a new database for a project and review it at a high level under each lens. Taking a tangible decision like this will help demonstrate how we can apply this framework in the real world.
The Technology
The very first thing to take a look at when evaluating a new technology is if that solution can solve the problems it claims to solve. Before diving into how a technology can help our process and business operations, it’s important to first establish that it is meeting our functional requirements. This is also where I like to take a look at what existing solutions we are using and how this new one stacks up against them.
I’ll ask myself questions like:
- Does it at a minimum solve the problem my existing solution does?
- In what ways is this solution better?
- In what ways is it worse?
- For areas that it is worse, what will it take to overcome those shortcomings?
- Will it take the place of multiple tools?
- How stable is the technology?
Our Why?
At this point, I also want to review why we are seeking another solution. A simple answer is we are encountering a problem that existing solutions don’t solve. However, this is often rarely the case. We have solved many software problems over the years with all of the technology we have today. What typically happens is that we get turned onto a new technology that makes something we are currently doing easier, more stable, faster, or cheaper.
Let’s take React as an example. Why did we decide to adopt React when jQuery or Vanilla JavaScript was doing the job? In this case, using the framework highlighted how this was a much better way to handle stateful frontends. It became faster for us to build things like filtering and sorting features by working with data structures instead of direct DOM manipulation. This was a saving in time and increased stability of our solutions.
Typescript is another example where we decided to adopt it because we found increases in the stability of our code and maintainability. With adopting new technologies, there often isn’t a clear problem we are looking to solve, but rather just looking to stay current and then discovering more efficient and stable solutions than we are currently using.
In the case of a database, we were specifically considering moving to a serverless option. We had seen a lot of success with serverless applications and deployments reducing our overhead as an organization. One area where we felt this was lacking was our data layer. We saw services like Amazon Aurora, Fauna, Cosmos and Firebase that were applying serverless principles to databases and wanted to see if it was time to take the leap ourselves. In this case, we were looking to lower our operational overhead and increase our development speed and efficiency.
It’s important at this level to understand your why before you start diving into new offerings. This may be because you are solving a novel problem, but far more often you are looking to improve your ability to solve a type of problem you are already solving. In that case, you need to take inventory of where you have been to figure out what would provide a meaningful improvement to your workflow. Building upon our example of looking at serverless databases, we’ll need to take a look at how we are currently solving problems and where those solutions fall short.
Where We Have Been…
As an agency, we have previously used a wide range of databases including but not limited to MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery, and Firebase Cloud Storage. The vast majority of our work centered around three core databases though: PostgreSQL, MongoDB, and Firebase Realtime Database. Each one of these does, in fact, have semi-serverless offerings, but some key features of newer offerings had us re-evaluating our previous assumptions. Let’s take a look at our historical experience with each of these first and why we are left considering alternatives in the first place.
We typically chose PostgreSQL for larger, long-term projects, as this is the battle-tested gold standard for almost everything. It supports classic transactions, normalized data, and is ACID compliant. There are a wealth of tools and ORMs available in almost every language and it can even be used as an ad-hoc NoSQL database with its JSON column support. It integrates well with many existing frameworks, libraries and programming languages making it a true go-anywhere workhorse. It is also open-source and therefore doesn’t get us locked into any one vendor. As they say, nobody ever got fired for choosing Postgres.
That being said, we have gradually found ourselves using PostgreSQL less and less as we became more of a Node-oriented shop. We have found the ORM’s for Node to be lackluster and requiring more custom queries (although this has become less problematic now) and NoSQL felt to be a more natural fit when working in a JavaScript or TypeScript runtime. That being said, we often had projects that could be done quite quickly with classic relational modeling like e-commerce workflows. However, dealing with the local setup of the database, unifying the testing flow across teams, and dealing with local migrations were things we didn’t love and were happy to leave behind as NoSQL, cloud-based databases became more popular.
MongoDB was increasingly our go-to database as we adopted Node.js as our preferred back end. Working with MongoDB Atlas made it easy to have quick development and testing databases that our team could use. For a while, MongoDB was not ACID compliant, didn’t support transactions, and discouraged too many inner join-like operations, thus for e-commerce applications we still were using Postgres most often. That being said, there are a wealth of libraries that go with it and Mongo’s query language and first-class JSON support gave us speed and efficiency we had not experienced with relational databases. MongoDB has added support for ACID transactions recently, but for a long time, this was the chief reason we would opt for Postgres instead.
MongoDB also introduced us to a new level of flexibility. In the middle of an agency project, requirements are bound to change. No matter how hard you defend against it, there is always a last-minute data requirement. With NoSQL databases, in general, the flexibility of the data structure made those types of changes less harsh. We didn’t end up with a folder full of migration files to manage that added and removed and added columns again before a project even saw daylight.
As a service, Mongo Atlas was also pretty close to what we desired in a database cloud service. I like to think of Atlas as a semi-serverless offering since you still have some operational overhead in managing it. You have to provision a certain size database and select an amount of memory upfront. These things will not scale for you automatically so you will need to monitor it for when it is time to provide more space or memory. In a truly serverless database, this would all happen automatically and on-demand.
We also utilized Firebase Realtime Database for a few projects. This was indeed a serverless offering where the database scales up and down on-demand, and with pay-as-you-go pricing, it made sense for applications where the scale was not known upfront and the budget was limited. We used this instead of MongoDB for short-lived projects that had simple data requirements.
One thing we did not enjoy about Firebase was it felt to be further from the typical relational model built around normalized data that we were used to. Keeping the data structures flat meant we often had more duplication, which could turn a bit ugly as a project grows. You end up having to update the same data in multiple places or trying to join together different references resulting in multiple queries that can become hard to reason about in the code. While we liked Firebase, we never really fell in love with the query language and sometimes found the documentation to be lackluster.
In general, both MongoDB and Firebase had a similar focus on denormalized data, and without access to efficient transactions, we often found many of the workflows that were easy to model in relational databases, which led to more complex code at the application layer with their NoSQL counterparts. If we could get the flexibility and ease of these NoSQL offerings with the robustness and relational modeling of a traditional SQL database we would really have found a great match. We felt MongoDB had the better API and capabilities but Firebase had the truly serverless model operationally.
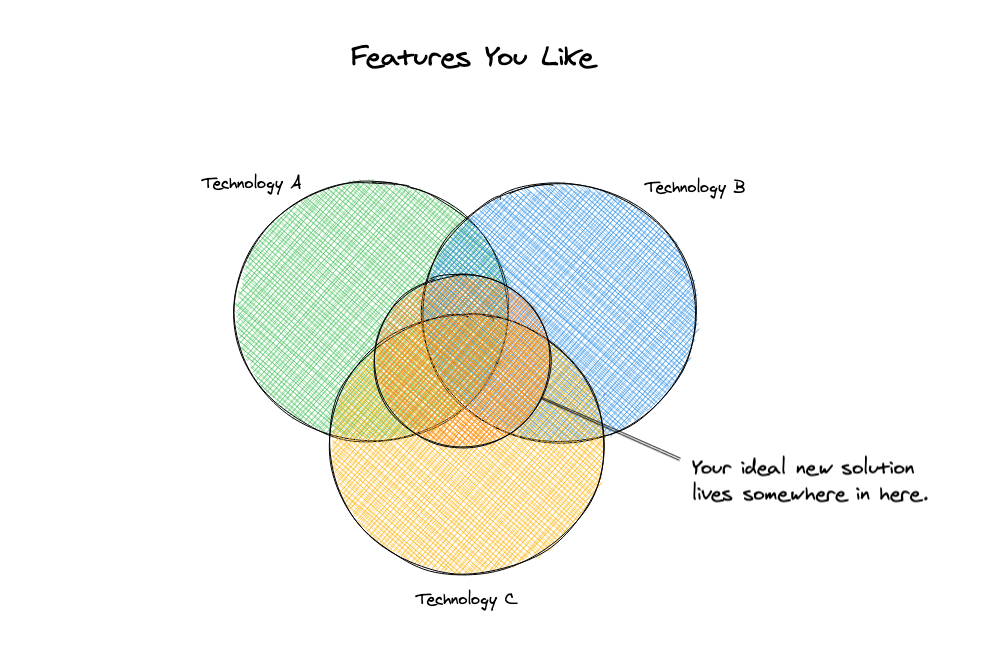
Our Ideal
At this point, we can start looking at what new options we will consider. We’ve clearly defined our previous solutions and we’ve identified the things that are important for us to have at a minimum in our new solution. We not only have a baseline or minimum set of requirements, but we also have a set of problems that we’d like the new solution to alleviate for us. Here are the technical requirements we have:
- Serverless operationally with on-demand scale
- Flexible modeling (schemaless)
- No reliance on migrations or ORMs
- ACID compliant transactions
- Supports relationships and normalized data
- Works with both serverless and traditional backends
So now that we have a list of must-haves we can actually evaluate some options. It may not be important that the new solution nails every target here. It may just be that it hits the right combination of features where existing solutions are not overlapping. For instance, if you wanted schemaless flexibility, you had to give up ACID transactions. (This was the case for a long time with databases.)
An example from another domain is if you want to have typescript validation in your template rendering you need to be using TSX and React. If you go with options like Svelte or Vue, you can have this — partially but not completely — through the template rendering. So a solution that gave you the tiny footprint and speed of Svelte with the template level type checking of React and TypeScript could be enough for adoption even if it were missing another feature. The balance of and wants and needs is going to change from project to project. It is up to you to figure out where the value is going to be and decide how to tick the most important points in your analysis.
We can now take a look at a solution and see how it evaluates against our desired solution. Fauna is a serverless database solution that boasts an on-demand scale with global distribution. It is a schemaless database, that provides ACID-compliant transactions, and supports relational queries and normalized data as a feature. Fauna can be used in both serverless applications as well as more traditional backends and provides libraries to work with the most popular languages. Fauna additionally provides workflows for authentication as well as easy and efficient multi-tenancy. These are both solid additional features to note because they could be the swaying factors when two technologies are nose to nose in our evaluation.
Now after looking at all of these strengths we have to evaluate the weaknesses. One of which is Fauna is not open source. This does mean that there are risks of vendor lock-in, or business and pricing changes that are out of your control. Open source can be nice because you can often up and take the technology to another vendor if you please or potentially contribute back to the project.
In the agency world, vendor lock-in is something we have to watch closely, not so much because of the price, but the viability of the underlying business is important. Having to change databases on a project that is in the middle of development or a few years old are both disastrous for an agency. Often a client will have to foot the bill for this, which is not a pleasant conversation to have.
One other weakness we were concerned with is the focus on JAMstack. While we love JAMstack, we find ourselves building a wide variety of traditional web applications more often. We want to be sure that Fauna continues to support those use cases. We had a bad experience in the past with a hosting provider that went all-in on JAMstack and we ended up having to migrate a rather large swath of sites from the service, so we want to feel confident that all use cases will continue to see solid support. Right now, this seems to be the case, and the serverless workflows provided by Fauna actually can complement a more traditional application quite nicely.
At this point, we’ve done our functional research and the only way to know if this solution is viable is to get down and write some code. In an agency environment, we can’t just take weeks out of the schedule for people to evaluate multiple solutions. This is the nature of working in an agency vs. a SaaS environment. In the latter, you might build a few prototypes to try to get to the right solution. In an agency, you will get a few days to experiment, or maybe the opportunity to do a side project but by and large we really have to narrow this down to one or two technologies at this stage and then put the fingers to the keyboard.
The Developer Experience
Judging the experience side of a new technology is perhaps the most difficult of the three areas since it is by nature subjective. It will also have variability from team to team. For example, if you asked a Ruby programmer, a Python programmer, and a Rust programmer about their opinions on different language features, you will get quite an array of responses. So, before you begin to judge an experience, you must first decide what characteristics are most important to your team overall.
For agencies I think there are two major bottlenecks that come up with regard to developer experience:
- Setup time and configuration
- Learnability
Both of these affect the long-term viability of a new technology in different ways. Keeping transient teams of developers in sync at an agency can be a headache. Tools that have lots of upfront setup costs and configurations are notoriously difficult for agencies to work with. The other is learnability and how easy it is for developers to grow the new technology. We’ll go into these in more detail and why they are my base when starting to evaluate developer experience.
Setup Time And Configuration
Agencies tend to have little patience and time for configuration. For me, I love sharp tools, with ergonomic designs, that allow me to get to work on the business problem at hand quickly. A number of years ago I worked for a SaaS company that had a complex local setup that involved many configurations and often failed at random points in the setup process. Once you were set up, the conventional wisdom was not to touch anything, and hope that you weren’t at the company long enough to have to set it up again on another machine. I’ve met developers that greatly enjoyed configuring each little piece of their emacs setup and thought nothing of losing a few hours to a broken local environment.
In general, I have found agency engineers have a disdain for these types of things in their day-to-day work. While at home they may tinker with these types of tools, but when on a deadline there’s nothing like tools that just work. At agencies, we typically would prefer to learn a few new things that work well, consistently, rather than to be able to configure each piece of tech to each individual’s personal taste.
One thing that is good about working with a cloud platform that is not open source is they own the setup and configuration entirely. While a downside of this is vendor lock-in, the upside is that these types of tools often do the thing they are set up to do well. There is no tinkering with environments, no local setups, and no deployment pipelines. We also have fewer decisions to make.
This is inherently the appeal of serverless. Serverless in general has a greater reliance on proprietary services and tools. We trade the flexibility of hosting and source code so that we can gain greater stability and focus on the problems of the business domain we are trying to solve. I’ll also note that when I’m evaluating a technology and I get the feeling that migrating off of a platform might be needed, this is often a bad sign at the outset.
In the case of databases, the set-it-and-forget-it setup is ideal when working with clients where the database needs can be ambiguous. We’ve had clients who were unsure how popular a program or application would be. We’ve had clients that we technically were not contracted to support in this way but nonetheless called us in a panic when they needed us to scale their database or application.
In the past, we’d always have to factor in things like redundancy, data replication, and sharding to scale when we crafted our SOW’s. Trying to cover each scenario while also being prepared to move a full book of business around in the event a database wasn’t scaling is an impossible situation to prepare for. In the end, a serverless database makes these things easier.
You never lose data, you don’t have to worry about replicating data across a network, nor provisioning a larger database and machine to run it on – it all just works. We only focus on the business problem at hand, the technical architecture and scale will always be managed. For our development team, this is a huge win; we have less fire drills, monitoring, and context switching.
Learnability
There is a classic user experience measure, which I think is applicable to developer experience, which is learnability. When designing for a certain user experience we don’t just look at if something is apparent or easy on first try. Technology just has more complexity than that most of the time. What is important is how easily a new user can learn and master the system.
When it comes to technical tools, especially powerful ones, it would be a lot to ask for there to be zero learning curve. Usually what we look for is for there to be great documentation for the most common use cases and for that knowledge to be easily and quickly built upon when in a project. Losing a little time to learning on the first project with a technology is okay. After that, we should see efficiency improve with each successive project.
What I look for specifically here is how we can leverage knowledge and patterns we already know to help shorten the learning curve. For instance, with serverless databases, there is going to be virtually zero learning curve for getting them set up in the cloud and deployed. When it comes to using the database one of the things I like is when we can still leverage all the years of mastering relational databases and apply those learnings to our new setup. In this case, we are learning how to use a new tool but it’s not forcing us to rethink our data modeling from the ground up.

As an example of this, when using Firebase, MongoDB, and DynamoDB we found that it encouraged denormalized data rather than trying to join different documents. This created a lot of cognitive friction when modeling our data as we needed to think in terms of access patterns rather than business entities. On the other side of this Fauna allowed us to leverage our years of relational knowledge as well as our preference for normalized data when it came to modeling data.
The part we had to get used to was using indexes and a new query language to bring those pieces together. In general, I’ve found that preserving concepts that are a part of larger software design paradigms makes it easier on the development team in terms of learnability and adoption.
How do we know that a team is adopting and loving a new technology? I think the best sign is when we find ourselves asking whether that tool integrates with the said new technology? When a new technology gets to a level of desirability and enjoyment that the team is searching for ways to incorporate it into more projects, that is a good sign you have a winner.
The Business
In this section, we have to look at how a new technology meets our business needs. These include questions like:
- How easily can it be priced and integrated into our support plans?
- Can we transition it to clients easily?
- Can clients be onboarded to this tool if need be?
- How much time does this tool actually save if any?
The rise of serverless as a paradigm fits agencies well. When we talk about databases and DevOps, the need for specialists in these areas at agencies is limited. Often we are handing off a project when we are done with it or supporting it in a limited capacity long term. We tend to bias toward full-stack engineers as these needs outnumber DevOps needs by a large margin. If we hired a DevOps engineer they would likely be spending a few hours deploying a project and many more hours hanging out waiting for a fire.
In this regard, we always have some DevOps contractors on the ready, but do not staff for these positions full time. This means we cannot rely on a DevOps engineer to be ready to jump for an unexpected issue. For us we know we can get better rates on hosting by going to AWS directly, but we also know that by using Heroku we can rely on our existing staff to debug most issues. Unless we have a client we need to support long term with specific backend needs, we like to default to managed platforms as a service.
Databases are no exception. We love leaning on services like Mongo Atlas or Heroku Postgres to make this process as easy as possible. As we started to see more and more of our stack head into serverless tools like Vercel, Netlify, or AWS Lambda – our database needs had to evolve with that. Serverless databases like Firebase, DynamoDB, and Fauna are great because they integrate well with serverless apps but also free our business completely from provisioning and scaling.
These solutions also work well for more traditional applications, where we don’t have a serverless application but we can still leverage serverless efficiencies at the database level. As a business, it is more productive for us to learn a single database that can apply to both worlds than to context switch. This is similar to our decision to adopt Node and isomorphic JavaScript (and TypeScript).
One of the downsides we have found with serverless has been coming up with pricing for clients we manage these services for. In a more traditional architecture, flat rate tiers make it very easy to translate those into a rate for clients with predictable circumstances for incurring increases and overages. When it comes to serverless this can be ambiguous. Finance people don’t typically like hearing things like we charge 1/10th of a penny for every read beyond 1 million, and so on and so forth.
This is hard to translate into a fixed number even for engineers as we are often building applications that we are not certain what the usage will be. We often have to create tiers ourselves but the many variables that go into the cost calculation of a lambda can be hard to wrap your head around. Ultimately, for a SaaS product these pay-as-you-go pricing models are great but for agencies the accountants like more concrete and predictable numbers.
When it came to Fauna, this was definitely more ambiguous to figure out than say a standard MySQL database that had flat-rate hosting for a set amount of space. The upside was that Fauna provides a nice calculator that we were able to use to put together our own pricing schemes.

{kind=link}
Another difficult aspect of serverless can be that many of these providers do not allow for easy breakdown of each application being hosted. For instance, the Heroku platform makes this quite easy by creating new pipelines and teams. We can even enter a client’s credit card for them in case they don’t want to use our hosting plans. This can all be done within the same dashboard as well so we didn’t need to create multiple logins.
When it came to other serverless tools this was much more difficult. In evaluating serverless databases Firebase supports splitting payments by project. In the case of Fauna or DynamoDB, this is not possible so we do have to do some work to monitor usage in their dashboard, and if the client wants to leave our service, we would have to transfer the database over to their own account.
Ultimately, serverless tools provide great business opportunities in terms of cost savings, management, and process efficiency. However, often they do prove challenging for agencies when it comes to pricing and account management. This is one area where we have had to leverage cost calculators to create our own predictable pricing tiers or set clients up with their own accounts so they can make the payments directly.
Conclusion
It can be a difficult task to adopt a new technology as an agency. While we are in a unique position to work with new, greenfield projects that have opportunities for new technologies, we also have to consider the long-term investment of these. How will they perform? Will our people be productive and enjoy using them? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it’s important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity, however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you’ll find levels of productivity you hadn’t realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don’t get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Other Resources
- Serverless Database Wishlist - What’s Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience
Further Reading
- Why Anticipatory Design Isn’t Working For Businesses
- CSS Scroll Snapping Aligned With Global Page Layout: A Full-Width Slider Case Study
- What’s New In Gatsby 2022?
- A Guide To Attracting Clients To Your Agency