HTTP/3 From A To Z: Core Concepts

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 200,000+ folks.




 Flexible CMS. Headless & API 1st
Flexible CMS. Headless & API 1st Register!
Register!You may have read some blog posts or heard conference talks on this topic and think you know the answers. You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”.
These statements and articles typically skip over some crucial technical details, are lacking in nuance, and usually are only partially correct. Often they make it seem as if HTTP/3 is a revolution in performance, while it is really a more modest (yet still useful!) evolution. This is dangerous, because the new protocol will probably not be able to live up to these high expectations in practice. I fear this will lead to many people ending up disappointed and to newcomers being confused by heaps of blindly perpetuated misinformation.
I’m afraid of this because we’ve seen exactly the same happen with HTTP/2. It was heralded as an amazing performance revolution, with exciting new features such as server push, parallel streams, and prioritization. We would have been able to stop bundling resources, stop sharding our resources across multiple servers, and heavily streamline the page-loading process. Websites would magically become 50% faster with the flip of a switch!
Five years later, we know that server push doesn’t really work in practice, streams and prioritization are often badly implemented, and, consequently, (reduced) resource bundling and even sharding are still good practices in some situations.
Similarly, other mechanisms that tweak protocol behavior, such as preload hints, often contain hidden depths and bugs, making them difficult to use correctly.
As such, I feel it is important to prevent this type of misinformation and these unrealistic expectations from spreading for HTTP/3 as well.
In this article series, I will discuss the new protocol, especially its performance features, with more nuance. I will show that, while HTTP/3 indeed has some promising new concepts, sadly, their impact will likely be relatively limited for most web pages and users (yet potentially crucial for a small subset). HTTP/3 is also quite challenging to set up and use (correctly), so take care when configuring the new protocol.
- Part 1: HTTP/3 History And Core Concepts
This article is targeted at people new to HTTP/3 and protocols in general, and it mainly discusses the basics. - Part 2: HTTP/3 Performance Features
This one is more in depth and technical. People who already know the basics can start here. - Part 3: Practical HTTP/3 Deployment Options
This third article in the series explains the challenges involved in deploying and testing HTTP/3 yourself. It details how and if you should change your web pages and resources as well.
Note: This series is aimed mainly at web developers who do not necessarily have a deep knowledge of protocols and would like to learn more. However, it does contain enough technical details and many links to external sources to be of interest to more advanced readers as well.
Why Do We Need HTTP/3?
One question I’ve often encountered is, “Why do we need HTTP/3 so soon after HTTP/2, which was only standardized in 2015?” This is indeed strange, until you realize that we didn’t really need a new HTTP version in the first place, but rather an upgrade of the underlying Transmission Control Protocol (TCP).
TCP is the main protocol that provides crucial services such as reliability and in-order delivery to other protocols such as HTTP. It’s also one of the reasons we can keep using the Internet with many concurrent users, because it smartly limits each user’s bandwidth usage to their fair share.
Did You Know?
When using HTTP(S), you’re really using several protocols besides HTTP at the same time. Each of the protocols in this “stack” has its own features and responsibilities (see image below). For example, while HTTP deals with URLs and data interpretation, Transport Layer Security (TLS) ensures security by encryption, TCP enables reliable data transport by retransmitting lost packets, and Internet Protocol (IP) routes packets from one endpoint to another across different devices in between (middleboxes).
This “layering” of protocols on top of one another is done to allow easy reuse of their features. Higher-layer protocols (such as HTTP) don’t have to reimplement complex features (such as encryption) because lower-layer protocols (such as TLS) already do that for them. As another example, most applications on the Internet use TCP internally to ensure that all of their data are transmitted in full. For this reason, TCP is one of the most widely used and deployed protocols on the Internet.
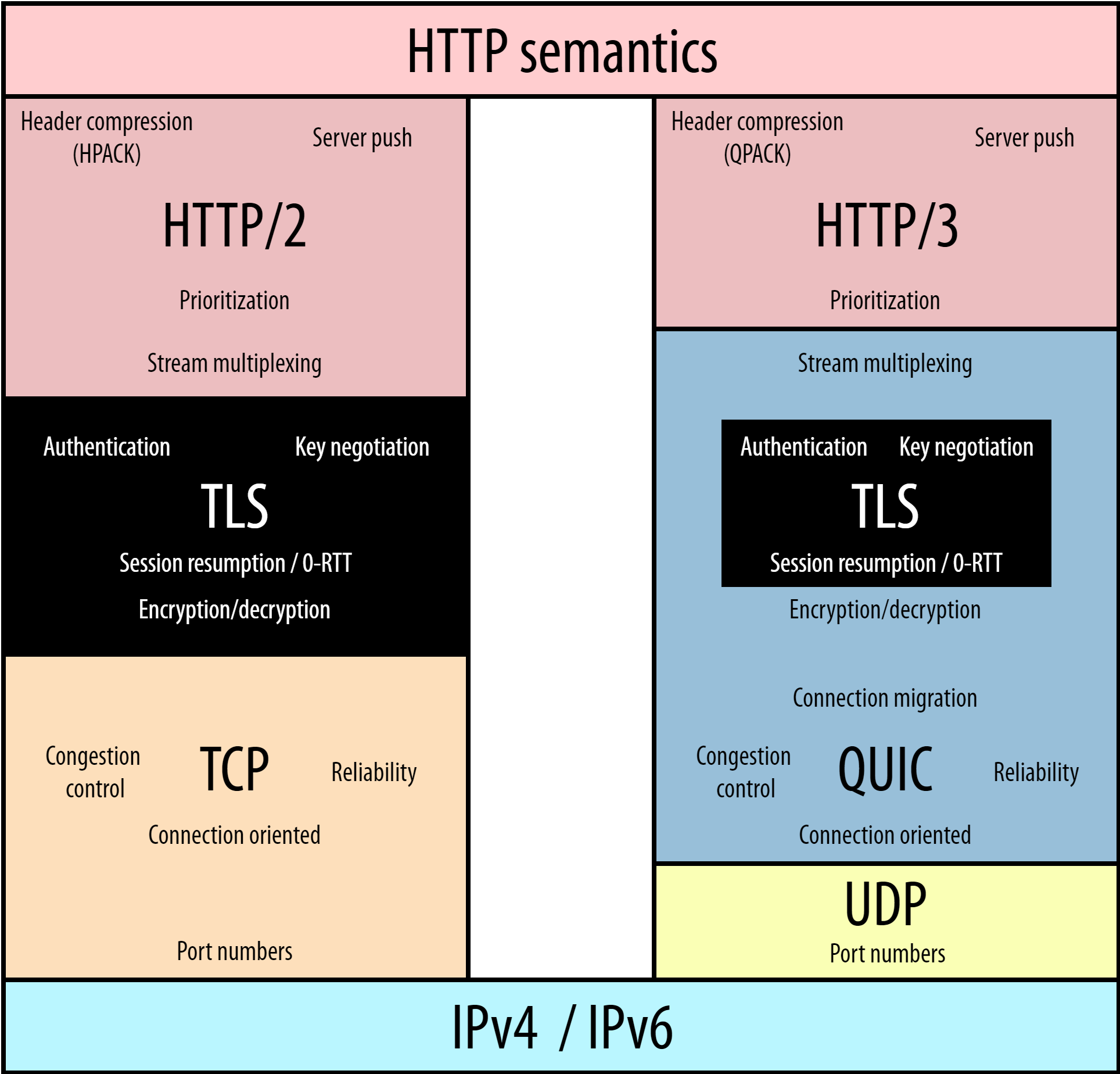
TCP has been a cornerstone of the web for decades, but it started to show its age in the late 2000s. Its intended replacement, a new transport protocol named QUIC, differs enough from TCP in a few key ways that running HTTP/2 directly on top of it would be very difficult. As such, HTTP/3 itself is a relatively small adaptation of HTTP/2 to make it compatible with the new QUIC protocol, which includes most of the new features people are excited about.
QUIC is needed because TCP, which has been around since the early days of the Internet, was not really built with maximum efficiency in mind. For example, TCP requires a “handshake” to set up a new connection. This is done to ensure that both client and server exist and that they’re willing and able to exchange data. It also, however, takes a full network round trip to complete before anything else can be done on a connection. If the client and server are geographically distant, each round-trip time (RTT) can take over 100 milliseconds, incurring noticeable delays.
As a second example, TCP sees all of the data it transports as a single “file” or byte stream, even if we’re actually using it to transfer several files at the same time (for example, when downloading a web page consisting of many resources). In practice, this means that if TCP packets containing data of a single file are lost, then all other files will also get delayed until those packets are recovered.
This is called head-of-line (HoL) blocking. While these inefficiencies are quite manageable in practice (otherwise, we wouldn’t have been using TCP for over 30 years), they do affect higher-level protocols such as HTTP in a noticeable way.
Over time, we’ve tried to evolve and upgrade TCP to improve some of these issues and even introduce new performance features. For example, TCP Fast Open gets rid of the handshake overhead by allowing higher-layer protocols to send data along from the start. Another effort is called MultiPath TCP. Here, the idea is that your mobile phone typically has both Wi-Fi and a (4G) cellular connection, so why not use them both at the same time for extra throughput and robustness?
It’s not terribly difficult to implement these TCP extensions. However, it is extremely challenging to actually deploy them at Internet scale. Because TCP is so popular, almost every connected device has its own implementation of the protocol on board. If these implementations are too old, lack updates, or are buggy, then the extensions won’t be practically usable. Put differently, all implementations need to know about the extension in order for it to be useful.
This wouldn’t be much of a problem if we were only talking about end-user devices (such as your computer or web server), because those can relatively easily be updated manually. However, many other devices are sitting between the client and the server that also have their own TCP code on board (examples include firewalls, load balancers, routers, caching servers, proxies, etc.).
These middleboxes are often more difficult to update and sometimes more strict in what they accept. For example, if the device is a firewall, it might be configured to block all traffic containing (unknown) extensions. In practice, it turns out that an enormous number of active middleboxes make certain assumptions about TCP that no longer hold for the new extensions.
Consequently, it can take years to even over a decade before enough (middlebox) TCP implementations become updated to actually use the extensions on a large scale. You could say that it has become practically impossible to evolve TCP.
As a result, it was clear that we would need a replacement protocol for TCP, rather than a direct upgrade, to resolve these issues. However, due to the sheer complexity of TCP’s features and their various implementations, creating something new but better from scratch would be a monumental undertaking. As such, in the early 2010s it was decided to postpone this work.
After all, there were issues not only with TCP, but also with HTTP/1.1. We chose to split up the work and first “fix” HTTP/1.1, leading to what is now HTTP/2. When that was done, the work could start on the replacement for TCP, which is now QUIC. Originally, we had hoped to be able to run HTTP/2 on top of QUIC directly, but in practice this would make implementations too inefficient (mainly due to feature duplication).
Instead, HTTP/2 was adjusted in a few key areas to make it compatible with QUIC. This tweaked version was eventually named HTTP/3 (instead of HTTP/2-over-QUIC), mainly for marketing reasons and clarity. As such, the differences between HTTP/1.1 and HTTP/2 are much more substantial than those between HTTP/2 and HTTP/3.
Takeaway
The key takeaway here is that what we needed was not really HTTP/3, but rather “TCP/2”, and we got HTTP/3 “for free” in the process. The main features we’re excited about for HTTP/3 (faster connection set-up, less HoL blocking, connection migration, and so on) are really all coming from QUIC.
What Is QUIC?
You might be wondering why this matters? Who cares if these features are in HTTP/3 or QUIC? I feel this is important, because QUIC is a generic transport protocol which, much like TCP, can and will be used for many use cases in addition to HTTP and web page loading. For example, DNS, SSH, SMB, RTP, and so on can all run over QUIC. As such, let’s look at QUIC a bit more in depth, because it’s here where most of the misconceptions about HTTP/3 that I’ve read come from.
One thing you might have heard is that QUIC runs on top of yet another protocol, called the User Datagram Protocol (UDP). This is true, but not for the (performance) reasons many people claim. Ideally, QUIC would have been a fully independent new transport protocol, running directly on top of IP in the protocol stack shown in the image I shared above.
However, doing that would have led to the same issue we encountered when trying to evolve TCP: All devices on the Internet would first have to be updated in order to recognize and allow QUIC. Luckily, we can build QUIC on top of the one other broadly supported transport-layer protocol on the Internet: UDP.
Did You Know?
UDP is the most bare-bones transport protocol possible. It really doesn’t provide any features, besides so-called port numbers (for example, HTTP uses port 80, HTTPS is on 443, and DNS employs port 53). It does not set up a connection with a handshake, nor is it reliable: If a UDP packet is lost, it is not automatically retransmitted. UDP’s “best effort” approach thus means that it’s about as performant as you can get: There’s no need to wait for the handshake and there’s no HoL blocking. In practice, UDP is mostly used for live traffic that updates at a high rate and thus suffers little from packet loss because missing data is quickly outdated anyway (examples include live video conferencing and gaming). It’s also useful for cases that need low up-front delay; for example, DNS domain name lookups really should only take a single round trip to complete.
Many sources claim that HTTP/3 is built on top of UDP because of performance. They say that HTTP/3 is faster because, just like UDP, it doesn’t set up a connection and doesn’t wait for packet retransmissions. These claims are wrong. As we’ve said above, UDP is used by QUIC and, thus, HTTP/3 mainly because the hope is that it will make them easier to deploy, because it is already known to and implemented by (almost) all devices on the Internet.
On top of UDP, then, QUIC essentially reimplements almost all features that make TCP such a powerful and popular (yet somewhat slower) protocol. QUIC is absolutely reliable, using acknowledgements for received packets and retransmissions to make sure lost ones still arrive. QUIC also still sets up a connection and has a highly complex handshake.
Finally, QUIC also uses so-called flow-control and congestion-control mechanisms that prevent a sender from overloading the network or the receiver, but that also make TCP slower than what you could do with raw UDP. The key thing is that QUIC implements these features in a smarter, more performant way than TCP. It combines decades of deployment experience and best practices of TCP with some core new features. We will discuss these features in more depth later in this article.
Takeaway
The key takeaway here is that there is no such thing as a free lunch. HTTP/3 isn’t magically faster than HTTP/2 just because we swapped TCP for UDP. Instead, we’ve reimagined and implemented a much more advanced version of TCP and called it QUIC. And because we want to make QUIC easier to deploy, we run it over UDP.
The Big Changes
So, how exactly does QUIC improve upon TCP, then? What is so different? There are several new concrete features and opportunities in QUIC (0-RTT data, connection migration, more resilience to packet loss and slow networks) that we will discuss in detail in the next part of the series. However, all of these new things basically boil down to four main changes:
- QUIC deeply integrates with TLS.
- QUIC supports multiple independent byte streams.
- QUIC uses connection IDs.
- QUIC uses frames.
Let’s take a closer look at each of these points.
There Is No QUIC Without TLS
As mentioned, TLS (the Transport Layer Security protocol) is in charge of securing and encrypting data sent over the Internet. When you use HTTPS, your plaintext HTTP data is first encrypted by TLS, before being transported by TCP.
Did You Know?
TLS’s technical details, luckily, aren’t really necessary here; you just need to know that encryption is done using some pretty advanced math and very large (prime) numbers. These mathematical parameters are negotiated between the client and the server during a separate TLS-specific cryptographic handshake. Just like the TCP handshake, this negotiation can take some time. In older versions of TLS (say, version 1.2 and lower), this typically takes two network round trips. Luckily, newer versions of TLS (1.3 is the latest) reduce this to just one round trip. This is mainly because TLS 1.3 severely limits the different mathematical algorithms that can be negotiated to just a handful (the most secure ones). This means that the client can just immediately guess which ones the server will support, instead of having to wait for an explicit list, saving a round trip.
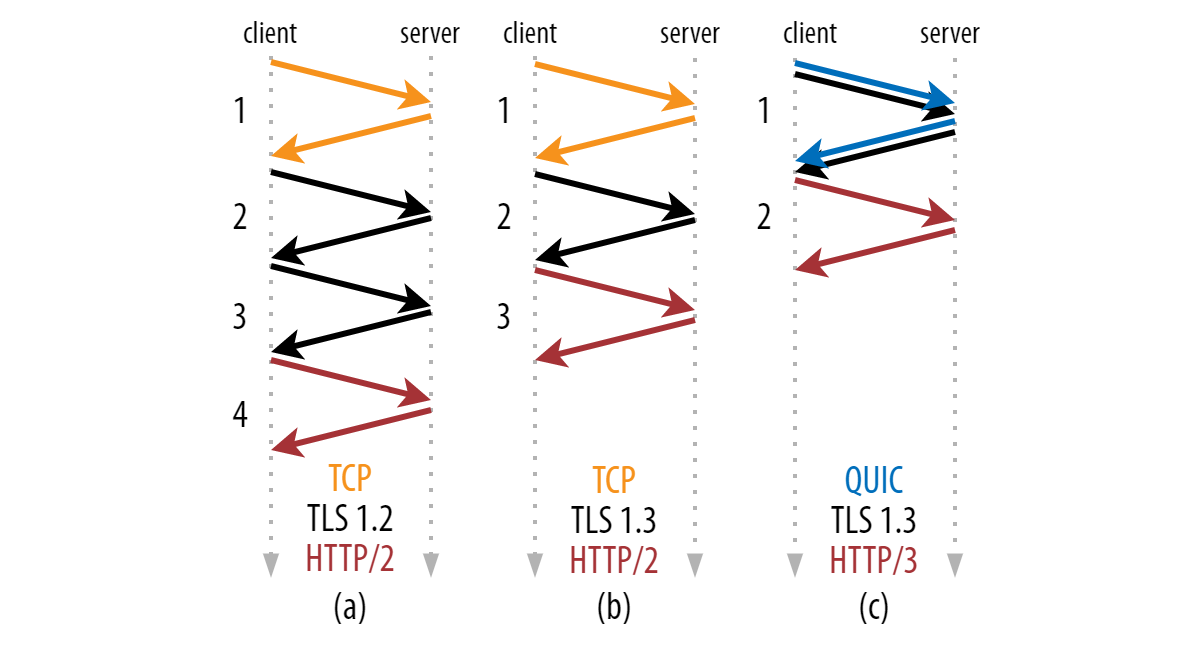
In the early days of the Internet, encrypting traffic was quite costly in terms of processing. Additionally, it was also not deemed necessary for all use cases. Historically, TLS has thus been a fully separate protocol that can optionally be used on top of TCP. This is why we have a distinction between HTTP (without TLS) and HTTPS (with TLS).
Over time, our attitude towards security on the Internet has, of course, changed to “secure by default”. As such, while HTTP/2 can, in theory, run directly over TCP without TLS (and this is even defined in the RFC specification as cleartext HTTP/2), no (popular) web browser actually supports this mode. In a way, the browser vendors made a conscious trade-off for more security at the cost of performance.
Given this clear evolution towards always-on TLS (especially for web traffic), it is no surprise that the designers of QUIC decided to take this trend to the next level. Instead of simply not defining a cleartext mode for HTTP/3, they elected to ingrain encryption deeply into QUIC itself. While the first Google-specific versions of QUIC used a custom set-up for this, standardized QUIC uses the existing TLS 1.3 itself directly.
For this, it sort of breaks the typical clean separation between protocols in the protocol stack, as we can see in the previous image. While TLS 1.3 can still run independently on top of TCP, QUIC instead sort of encapsulates TLS 1.3. Put differently, there is no way to use QUIC without TLS; QUIC (and, by extension, HTTP/3) is always fully encrypted. Furthermore, QUIC encrypts almost all of its packet header fields as well; transport-layer information (such as packet numbers, which are never encrypted for TCP) is no longer readable by intermediaries in QUIC (even some of the packet header flags are encrypted).
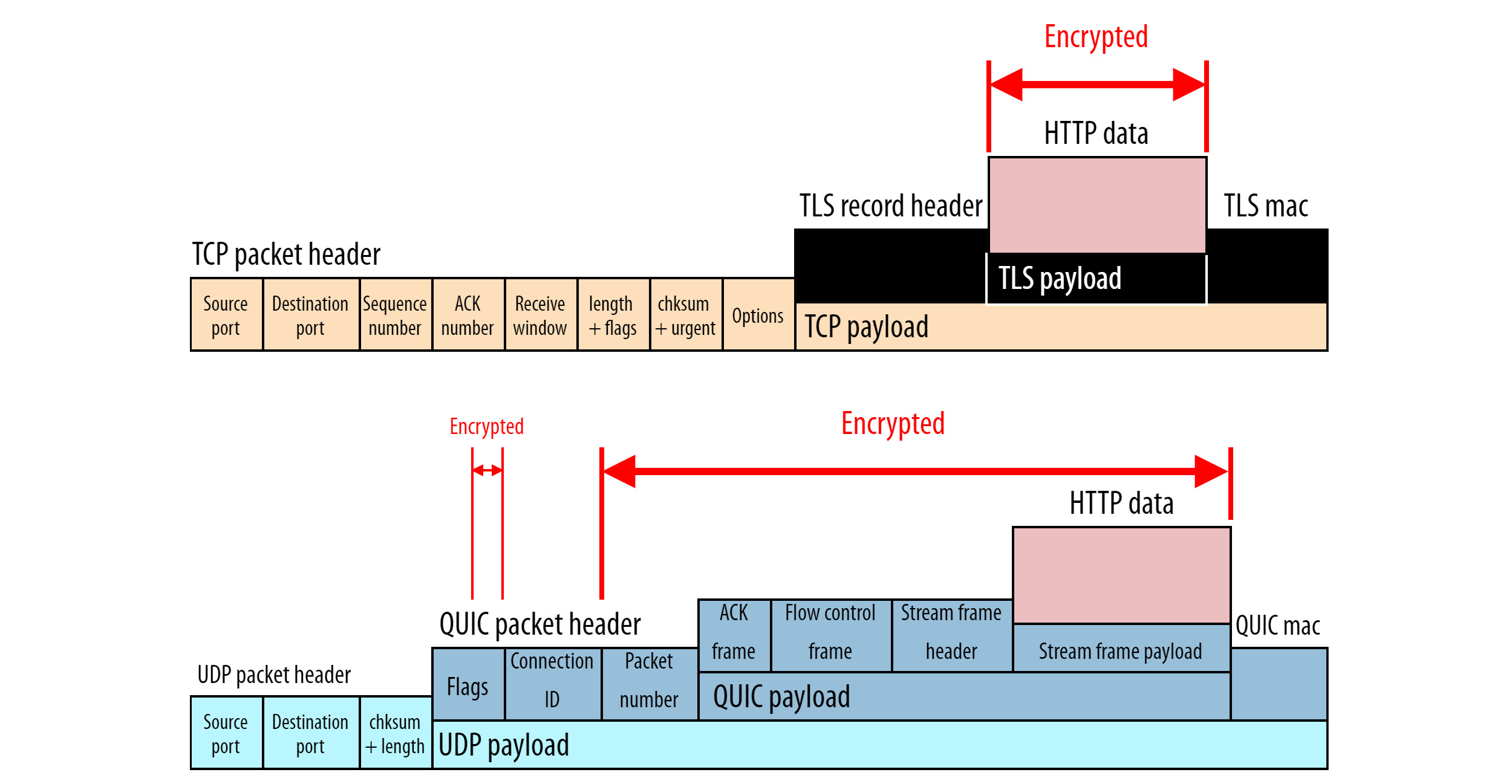
For all this, QUIC first uses the TLS 1.3 handshake more or less as you would with TCP to establish the mathematical encryption parameters. After this, however, QUIC takes over and encrypts the packets itself, whereas with TLS-over-TCP, TLS does its own encryption. This seemingly small difference represents a fundamental conceptual change towards always-on encryption that is enforced at ever lower protocol layers.
This approach provides QUIC with several benefits:
- QUIC is more secure for its users.
There is no way to run cleartext QUIC, so there are also fewer options for attackers and eavesdroppers to listen in on. (Recent research has shown how dangerous HTTP/2’s cleartext option can be.) - QUIC’s connection set-up is faster.
While for TLS-over-TCP, both protocols need their own separate handshakes, QUIC instead combines the transport and cryptographic handshake into one, saving a round trip (see image above). We’ll discuss this in more detail in part 2. - QUIC can evolve more easily.
Because it is fully encrypted, middleboxes in the network can no longer observe and interpret its inner workings like they can with TCP. Consequently, they also can no longer break (accidentally) in newer versions of QUIC because they failed to update. If we want to add new features to QUIC in the future, we “only” have to update the end devices, instead of all of the middleboxes as well.
Next to these benefits, however, there are also some potential downsides to extensive encryption:
- Many networks will hesitate to allow QUIC.
Companies might want to block it on their firewalls, because detecting unwanted traffic becomes more difficult. ISPs and intermediate networks might block it because metrics such as average delays and packet loss percentages are no longer easily available, making it more difficult to detect and diagnose problems. This all means that QUIC will probably never be universally available, which we’ll discuss more in part 3. - QUIC has a higher encryption overhead.
QUIC encrypts each individual packet with TLS, whereas TLS-over-TCP can encrypt several packets at the same time. This potentially makes QUIC slower for high-throughput scenarios (as we’ll see in part 2). - QUIC makes the web more centralized.
A complaint I’ve encountered often is something like, “QUIC is being pushed by Google because it gives them full access to the data while sharing none of it with others”. I mostly disagree with this. First, QUIC doesn’t hide more (or less!) user-level information (for example, which URLs you are visiting) from outside observers than TLS-over-TCP does (QUIC keeps the status quo).
Secondly, while Google initiated the QUIC project, the final protocols we’re talking about today were designed by a much wider team in the Internet Engineering Task Force (IETF). IETF’s QUIC is technically very different from Google’s QUIC. Still, it is true that the people in the IETF are mostly from larger companies like Google and Facebook and CDNs like Cloudflare and Fastly. Due to QUIC’s complexity, it will be mainly those companies that have the necessary know-how to correctly and performantly deploy, for example, HTTP/3 in practice. This will probably lead to more centralization in those companies, which is a real concern.
On A Personal Note:
This is one of the reasons I write these types of articles and do a lot of technical talks: to make sure more people understand the protocol’s details and can use them independently of these big companies.
Takeaway
The key takeaway here is that QUIC is deeply encrypted by default. This not only improves its security and privacy characteristics, but also helps its deployability and evolvability. It makes the protocol a bit heavier to run but, in return, allows other optimizations, such as faster connection establishment.
QUIC Knows About Multiple Byte Streams
The second big difference between TCP and QUIC is a bit more technical, and we will explore its repercussions in more detail in part 2. For now, though, we can understand the main aspects in a high-level way.
Did You Know?
Consider first that even a simple web page is made up of a number of independent files and resources. There’s HTML, CSS, JavaScript, images, and so on. Each of these files can be seen as a simple “binary blob” — a collection of zeroes and ones that are interpreted in a certain way by the browser. When sending these files over the network, we don’t transfer them all at once. Instead, they are subdivided into smaller chunks (typically, of about 1400 bytes each) and sent in individual packets. As such, we can view each resource as being a separate “byte stream”, as data is downloaded or “streamed” piecemeal over time.
For HTTP/1.1, the resource-loading process is quite simple, because each file is given its own TCP connection and downloaded in full. For example, if we have files A, B, and C, we would have three TCP connections. The first would see a byte stream of AAAA, the second BBBB, the third CCCC (with each letter repetition being a TCP packet). This works but is also very inefficient because each new connection has some overhead.
In practice, browsers impose limits on how many concurrent connections may be used (and thus how many files may be downloaded in parallel) — typically, between 6 and 30 per page load. Connections are then reused to download a new file once the previous has fully transferred. These limits eventually started to hinder web performance on modern pages, which often load many more than 30 resources.
Improving this situation was one of the main goals for HTTP/2. The protocol does this by no longer opening a new TCP connection for each file, but instead downloading the different resources over a single TCP connection. This is achieved by “multiplexing” the different byte streams. That’s a fancy way of saying that we mix data of the different files when transporting it. For our three example files, we would get a single TCP connection, and the incoming data might look like AABBCCAABBCC (although many other ordering schemes are possible). This seems simple enough and indeed works quite well, making HTTP/2 typically just as fast or a bit faster than HTTP/1.1, but with much less overhead.
Let’s take a closer look at the difference:

However, there is a problem on the TCP side. You see, because TCP is a much older protocol and not made for just loading web pages, it doesn’t know about A, B, or C. Internally, TCP thinks it’s transporting just a single file, X, and it doesn’t care that what it views as XXXXXXXXXXXX is actually AABBCCAABBCC at the HTTP level. In most situations, this doesn’t matter (and it actually makes TCP quite flexible!), but that changes when there is, for example, packet loss on the network.
Suppose the third TCP packet is lost (the one containing the first data for file B), but all of the other data are delivered. TCP deals with this loss by retransmitting a new copy of the lost data in a new packet. This retransmission can, however, take a while to arrive (at least one RTT). You might think that’s not a big problem, as we see there is no loss for resources A and C. As such, we can start processing them while waiting for the missing data for B, right?
Sadly, that’s not the case, because the retransmission logic happens at the TCP layer, and TCP does not know about A, B, and C! TCP instead thinks that a part of the single X file has been lost, and thus it feels it has to keep the rest of X’s data from being processed until the hole is filled. Put differently, while at the HTTP/2 level, we know that we could already process A and C, TCP does not know this, causing things to be slower than they potentially could be. This inefficiency is an example of the “head-of-line (HoL) blocking” problem.
Solving HoL blocking at the transport layer was one of the main goals of QUIC. Unlike TCP, QUIC is intimately aware that it is multiplexing multiple, independent byte streams. It, of course, doesn’t know that it’s transporting CSS, JavaScript, and images; it just knows that the streams are separate. As such, QUIC can perform packet loss detection and recovery logic on a per-stream basis.
In the scenario above, it would only hold back the data for stream B, and unlike TCP, it would deliver any data for A and C to the HTTP/3 layer as soon as possible. (This is illustrated below.) In theory, this could lead to performance improvements. In practice, however, the story is much more nuanced, as we’ll discuss in part 2.
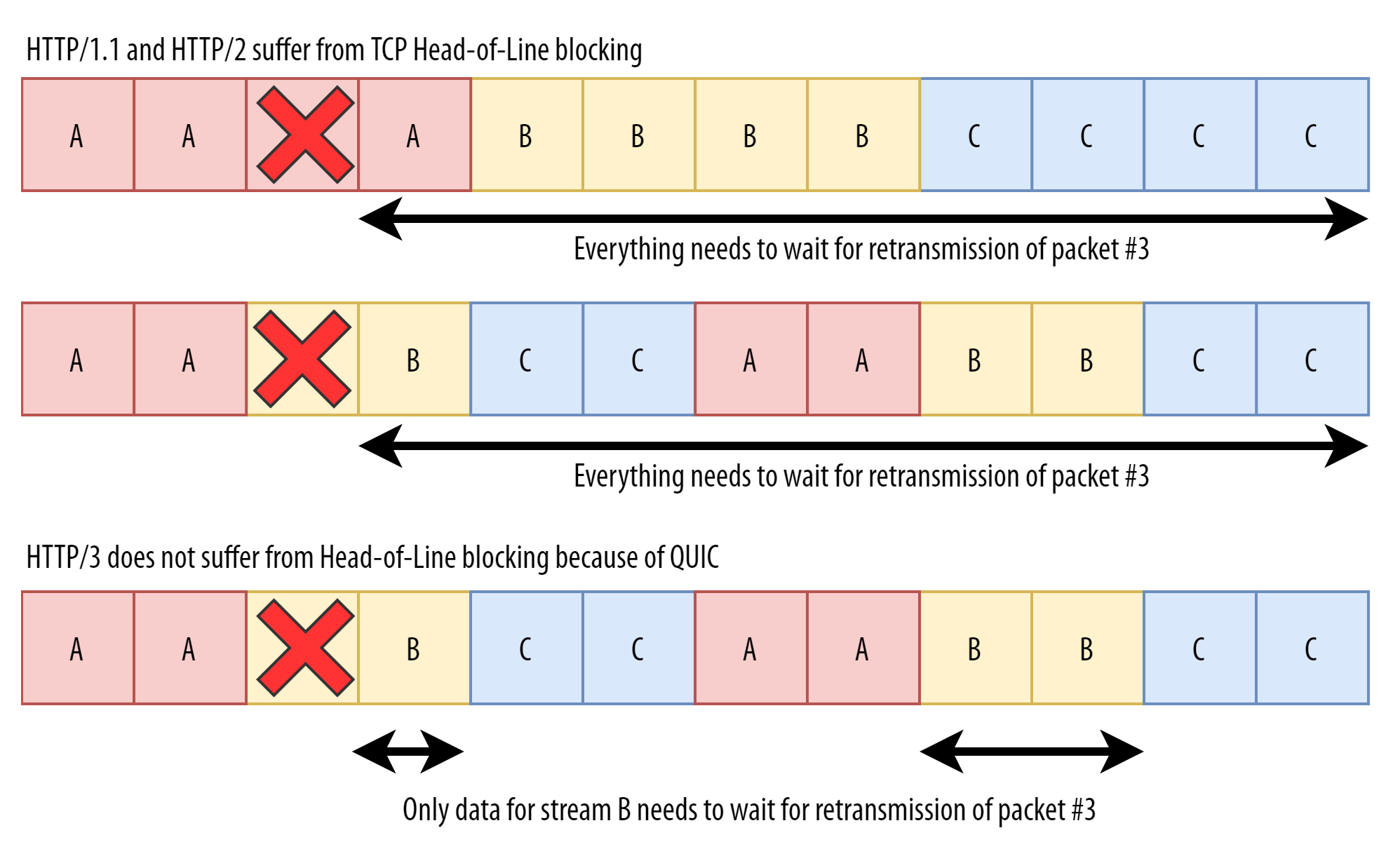
We can see that we now have a fundamental difference between TCP and QUIC. This is, incidentally, also one of the main reasons why we can’t just run HTTP/2 as is over QUIC. As we said, HTTP/2 also includes a concept of running multiple streams over a single (TCP) connection. As such, HTTP/2-over-QUIC would have two different and competing stream abstractions on top of one another.
Making them work together nicely would be very complex and error-prone; so, one of the key differences between HTTP/2 and HTTP/3 is that the latter removes the HTTP stream logic and reuses QUIC streams instead. As we’ll see in part 2, though, this has other repercussions in how features such as server push, header compression, and prioritization are implemented.
Takeaway
The key takeaway here is that TCP was never designed to transport multiple, independent files over a single connection. Because that is exactly what web browsing requires, this has led to many inefficiencies over the years. QUIC solves this by making multiple byte streams a core concept at the transport layer and handling packet loss on a per-stream basis.
QUIC Supports Connection Migration
The third major improvement in QUIC is the fact that connections can stay alive longer.
Did You Know?
We often use the concept of a “connection” when talking about web protocols. However, what exactly is a connection? Typically, people speak of a TCP connection once there has been a handshake between two endpoints (say, the browser or client and the server). This is why UDP is often (somewhat misguidedly) said to be “connectionless”, because it doesn’t do such a handshake. However, the handshake is really nothing special: It’s just a few packets with a specific form being sent and received. It has a few goals, main among them being to make sure there is something on the other side and that it’s willing and able to talk to us. It’s worth repeating here that QUIC also performs a handshake, even though it runs over UDP, which by itself doesn’t.
So, the question becomes, how do those packets arrive at the correct destination? On the Internet, IP addresses are used to route packets between two unique machines. However, just having the IPs for your phone and the server isn’t enough, because both want to be able to run multiple networked programs at each end simultaneously.
This is why each individual connection is also assigned a port number on both endpoints to differentiate connections and the applications they belong to. Server applications typically have a fixed port number depending on their function (for example ports 80 and 443 for HTTP(S), and port 53 for DNS), while clients usually choose their port numbers (semi-)randomly for each connection.
As such, to define a unique connection across machines and applications, we need these four things, the so-called 4-tuple: client IP address + client port + server IP address + server port.
In TCP, connections are identified by just the 4-tuple. So, if just one of those four parameters changes, the connection becomes invalid and needs to be re-established (including a new handshake). To understand this, imagine the parking-lot problem: You are currently using your smartphone inside of a building with Wi-Fi. As such, you have an IP address on this Wi-Fi network.
If you now move outside, your phone might switch to the cellular 4G network. Because this is a new network, it will get a completely new IP address, because those are network-specific. Now, the server will see TCP packets coming in from a client IP that it hasn’t seen before (although the two ports and the server IP could, of course, stay the same). This is illustrated below.
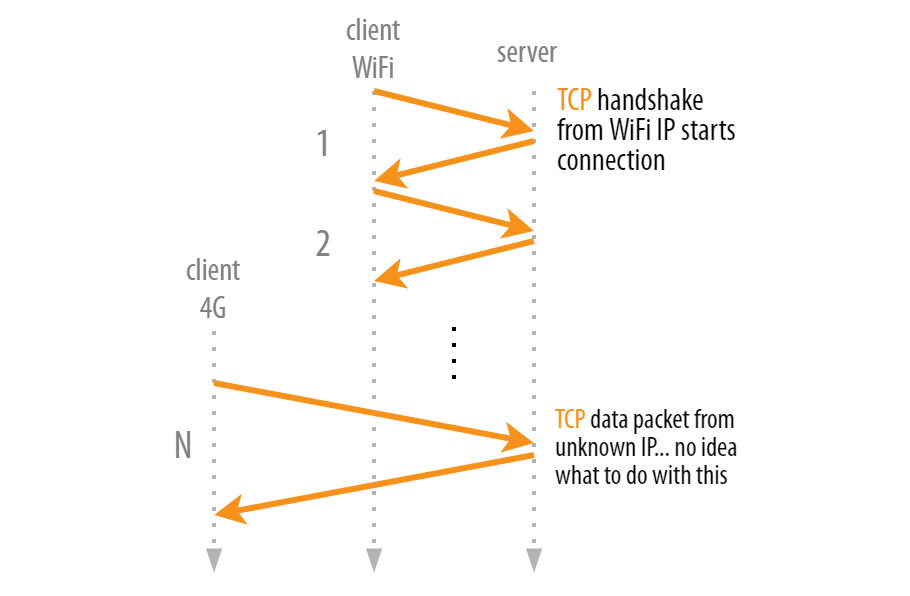
But how can the server know that these packets from a new IP belong to the “connection”? How does it know these packets don’t belong to a new connection from another client in the cellular network that chose the same (random) client port (which can easily happen)? Sadly, it cannot know this.
Because TCP was invented before we were even dreaming of cellular networks and smartphones, there is, for example, no mechanism that allows the client to let the server know it has changed IPs. There isn’t even a way to “close” the connection, because a TCP reset or fin command sent to the old 4-tuple wouldn’t even reach the client anymore. As such, in practice, every network change means that existing TCP connections can no longer be used.
A new TCP (and possibly TLS) handshake has to be executed to set up a new connection, and, depending on the application-level protocol, in-process actions would need to be restarted. For example, if you were downloading a large file over HTTP, then that file might have to be re-requested from the start (for example, if the server doesn’t support range requests). Another example is live video conferencing, where you might have a short blackout when switching networks.
Note that there are other reasons why the 4-tuple might change (for example, NAT rebinding), which we’ll discuss more in part 2.
Restarting the TCP connections can thus have a severe impact (waiting for new handshakes, restarting downloads, re-establishing context). To solve this problem, QUIC introduces a new concept named the connection identifier (CID). Each connection is assigned another number on top of the 4-tuple that uniquely identifies it between two endpoints.
Crucially, because this CID is defined at the transport layer in QUIC itself, it doesn’t change when moving between networks! This is shown in the image below. To make this possible, the CID is included at the front of each and every QUIC packet (much like how the IP addresses and ports are also present in each packet). (It’s actually one of the few things in the QUIC packet header that aren’t encrypted!)
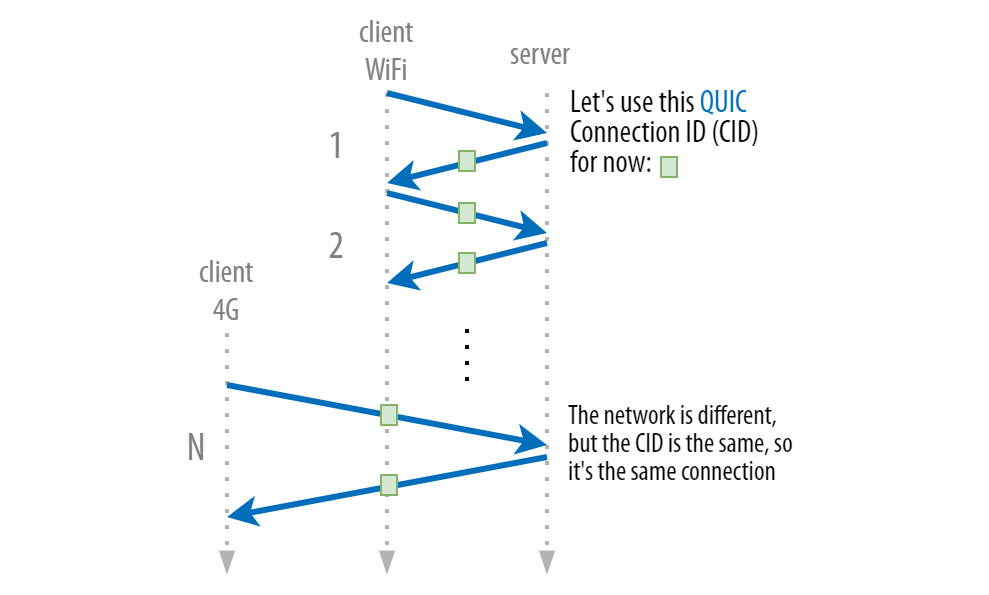
With this set-up, even when one of the things in the 4-tuple changes, the QUIC server and client only need to look at the CID to know that it’s the same old connection, and then they can keep using it. There is no need for a new handshake, and the download state can be kept intact. This feature is typically called connection migration. This is, in theory, better for performance, but as we will discuss in part 2, it’s, of course, a nuanced story again.
There are other challenges to overcome with the CID. For example, if we would indeed use just a single CID, it would make it extremely easy for hackers and eavesdroppers to follow a user across networks and, by extension, deduce their (approximate) physical locations. To prevent this privacy nightmare, QUIC changes the CID every time a new network is used.
That might confuse you, though: Didn’t I just say that the CID is supposed to be the same across networks? Well, that was an oversimplification. What really happens internally is that the client and server agree on a common list of (randomly generated) CIDs that all map to the same conceptual “connection”.
For example, they both know that CIDs K, C, and D in reality all map to connection X. As such, while the client might tag packets with K on Wi-Fi, it can switch to using C on 4G. These common lists are negotiated fully encrypted in QUIC, so potential attackers won’t know that K and C are really X, but the client and server would know this, and they can keep the connection alive.
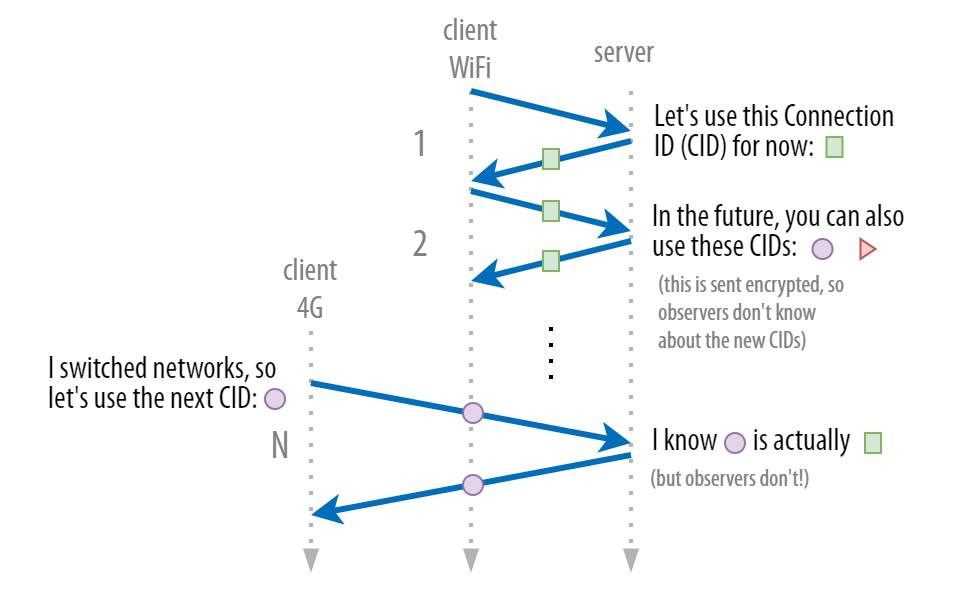
It gets even more complex, because clients and servers will have different lists of CIDs that they choose themselves (much like they have different port numbers). This is mainly to support with routing and load balancing in large-scale server set-ups, as we’ll see in more detail in part 3.
Takeaway
The key takeaway here is that in TCP, connections are defined by four parameters that can change when endpoints change networks. As such, these connections sometimes need to be restarted, leading to some downtime. QUIC adds another parameter to the mix, called the connection ID. Both the QUIC client and server know which connection IDs map to which connections and are thus more robust against network changes.
QUIC Is Flexible and Evolvable
A final aspect of QUIC is that it’s specifically made to be easy to evolve. This is accomplished in several different ways. First, as discussed, the fact that QUIC is almost fully encrypted means that we only need to update the endpoints (clients and servers), and not all middleboxes, if we want to deploy a newer version of QUIC. That still takes time, but typically in the order of months, not years.
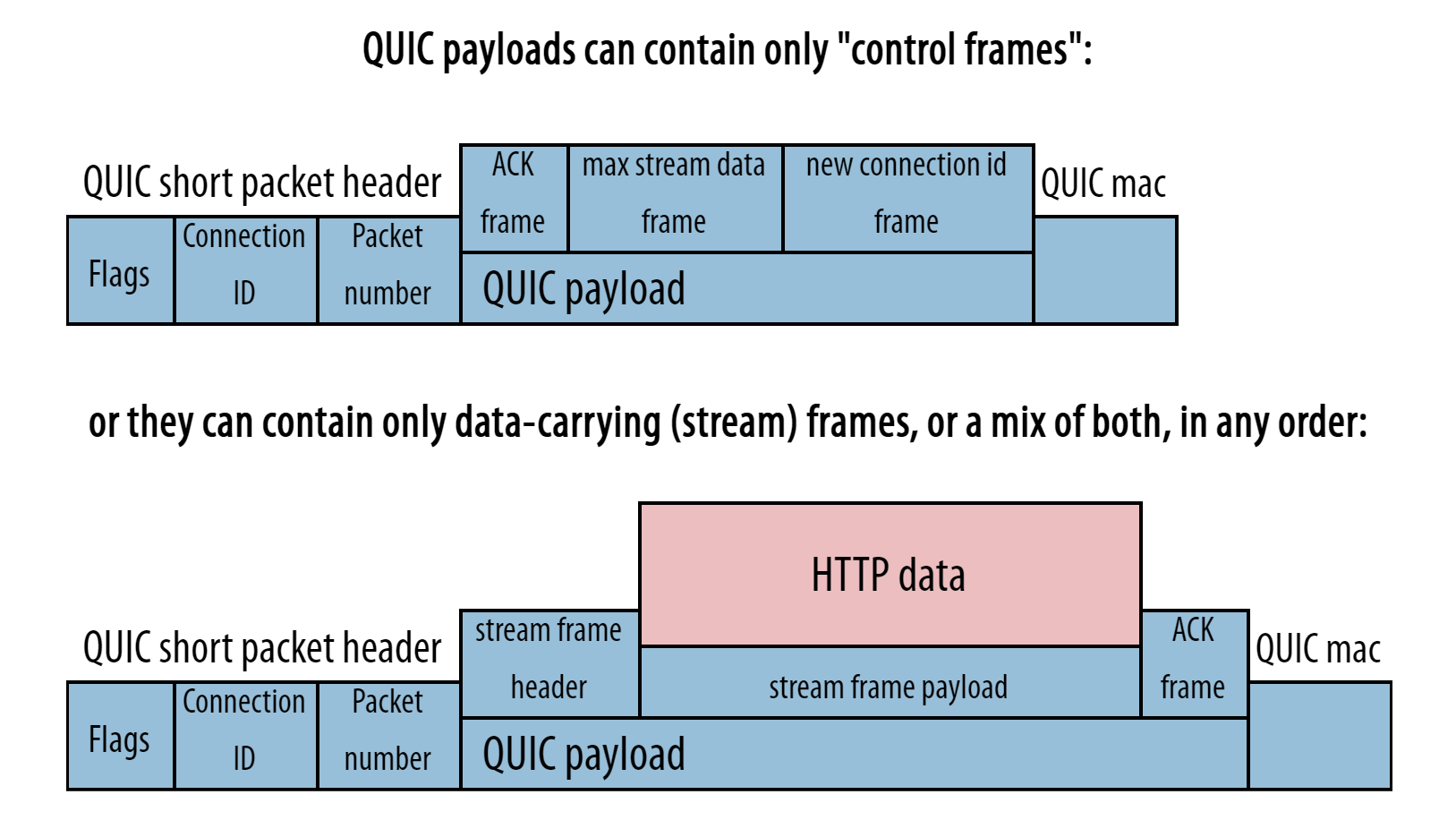
Secondly, unlike TCP, QUIC does not use a single fixed packet header to send all protocol meta data. Instead, QUIC has short packet headers and uses a variety of “frames” (kind of like miniature specialized packets) inside the packet payload to communicate extra information. There is, for example, an ACK frame (for acknowledgements), a NEW_CONNECTION_ID frame (to help set up connection migration), and a STREAM frame (to carry data), as shown in the image below.
This is mainly done as an optimization, because not every packet carries all possible meta data (and so the TCP packet header usually wastes quite some bytes — see also the image above). A very useful side effect of using frames, however, is that defining new frame types as extensions to QUIC will be very easy in the future. A very important one, for example, is the DATAGRAM frame, which allows unreliable data to be sent over an encrypted QUIC connection.
Thirdly, QUIC uses a custom TLS extension to carry what are called transport parameters. These allow the client and server to choose a configuration for a QUIC connection. This means they can negotiate which features are enabled (for example, whether to allow connection migration, which extensions are supported, etc.) and communicate sensible defaults for some mechanisms (for example, maximum supported packet size, flow control limits). While the QUIC standard defines a long list of these, it also allows extensions to define new ones, again making the protocol more flexible.
Lastly, while not a real requirement of QUIC by itself, most implementations are currently done in “user space” (as opposed to TCP, which is usually done in “kernel space”). The details are discussed in part 2, but this mainly means that it’s much easier to experiment with and deploy QUIC implementation variations and extensions than it is for TCP.
Takeaway
While QUIC has now been standardized, it should really be regarded as QUIC version 1 (which is also clearly stated in the Request For Comments (RFC)), and there is a clear intent to create version 2 and more fairly quickly. On top of that, QUIC allows for the easy definition of extensions, so even more use cases can be implemented.
Conclusion
Let’s summarize what we’ve learned in this part. We have mainly talked about the omnipresent TCP protocol and how it was designed in a time when many of today’s challenges were unknown. As we tried to evolve TCP to keep up, it became clear this would be difficult in practice, because almost every device has its own TCP implementation on board that would need to be updated.
To bypass this issue while still improving TCP, we created the new QUIC protocol (which is really TCP 2.0 under the hood). To make QUIC easier to deploy, it is run on top of the UDP protocol (which most network devices also support), and to make sure it can evolve in the future, it is almost entirely encrypted by default and makes use of a flexible framing mechanism.
Other than this, QUIC mostly mirrors known TCP features, such as the handshake, reliability, and congestion control. The two main changes besides encryption and framing are the awareness of multiple byte streams and the introduction of the connection ID. These changes were, however, enough to prevent us from running HTTP/2 on top of QUIC directly, necessitating the creation of HTTP/3 (which is really HTTP/2-over-QUIC under the hood).
QUIC’s new approach gives way to a number of performance improvements, but their potential gains are more nuanced than typically communicated in articles on QUIC and HTTP/3. Now that we know the basics, we can discuss these nuances in more depth in the next part of this series.
- Part 1: HTTP/3 History And Core Concepts
This article is targeted at people new to HTTP/3 and protocols in general, and it mainly discusses the basics. - Part 2: HTTP/3 Performance Features
This one is more in depth and technical. People who already know the basics can start here. - Part 3: Practical HTTP/3 Deployment Options
This third article in the series explains the challenges involved in deploying and testing HTTP/3 yourself. It details how and if you should change your web pages and resources as well.


