HTTP/3: Performance Improvements (Part 2)

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Celebrating 10 million developers
Celebrating 10 million developers



 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.Welcome back to this series about the new HTTP/3 protocol. In part 1, we looked at why exactly we need HTTP/3 and the underlying QUIC protocol, and what their main new features are.
In this second part, we will zoom in on the performance improvements that QUIC and HTTP/3 bring to the table for web-page loading. We will, however, also be somewhat skeptical of the impact we can expect from these new features in practice.
As we will see, QUIC and HTTP/3 indeed have great web performance potential, but mainly for users on slow networks. If your average visitor is on a fast cabled or cellular network, they probably won’t benefit from the new protocols all that much. However, note that even in countries and regions with typically fast uplinks, the slowest 1% to even 10% of your audience (the so-called 99th or 90th percentiles) still stand to potentially gain a lot. This is because HTTP/3 and QUIC mainly help deal with the somewhat uncommon yet potentially high-impact problems that can arise on today’s Internet.
This part is a bit more technical than the first, though it offloads most of the really deep stuff to outside sources, focusing on explaining why these things matter to the average web developer.
- Part 1: HTTP/3 History And Core Concepts
This article is targeted at people new to HTTP/3 and protocols in general, and it mainly discusses the basics. - Part 2: HTTP/3 Performance Features
This one is more in depth and technical. People who already know the basics can start here. - Part 3: Practical HTTP/3 Deployment Options
This third article in the series explains the challenges involved in deploying and testing HTTP/3 yourself. It details how and if you should change your web pages and resources as well.
A Primer On Speed
Discussing performance and “speed” can quickly get complex, because many underlying aspects contribute to a web-page loading “slowly”. Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth.
Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). It is physically limited by the speed of light or, practically, how fast signals can travel in wires or in the open air. This means that latency often depends on the physical, real-world distance between A and B.
On earth, this means that typical latencies are conceptually small, between roughly 10 and 200 milliseconds. However, this is only one way: Responses to the packets also need to come back. Two-way latency is often called round-trip time (RTT).
Due to features such as congestion control (see below), we will often need quite a few round trips to load even a single file. As such, even low latencies of less than 50 milliseconds can add up to considerable delays. This is one of the main reasons why content delivery networks (CDNs) exist: They place servers physically closer to the end user in order to reduce latency, and thus delay, as much as possible.
Bandwidth, then, can roughly be said to be the number of packets that can be sent at the same time. This is a bit more difficult to explain, because it depends on the physical properties of the medium (for example, the used frequency of radio waves), the number of users on the network, and also the devices that interconnect different subnetworks (because they typically can only process a certain number of packets per second).
An often used metaphor is that of a pipe used to transport water. The length of the pipe is the latency, while the width of the pipe is the bandwidth. On the Internet, however, we typically have a long series of connected pipes, some of which can be wider than others (leading to so-called bottlenecks at the narrowest links). As such, the end-to-end bandwidth between points A and B is often limited by the slowest subsections.
While a perfect understanding of these concepts is not needed for the rest of this post, having a common high-level definition would be good. For more info, I recommend checking out Ilya Grigorik’s excellent chapter on latency and bandwidth in his book High Performance Browser Networking.
Congestion Control
One aspect of performance is about how efficiently a transport protocol can use a network’s full (physical) bandwidth (i.e. roughly, how many packets per second can be sent or received). This in turn affects how fast a page’s resources can be downloaded. Some claim that QUIC somehow does this much better than TCP, but that’s not true.
Did You Know?
A TCP connection, for example, doesn’t just start sending data at full bandwidth, because this could end up overloading (or congesting) the network. This is because, as we said, each network link has only a certain amount of data it can (physically) process every second. Give it any more and there is no option other than to drop the excessive packets, leading to packet loss.
As discussed in part 1, for a reliable protocol like TCP, the only way to recover from packet loss is by retransmitting a new copy of the data, which takes one round trip. Especially on high-latency networks (say, with an over 50-millisecond RTT), packet loss can seriously affect performance.
Another problem is that we don’t know up front how much the maximum bandwidth will be. It often depends on a bottleneck somewhere in the end-to-end connection, but we cannot predict or know where this will be. The Internet also doesn’t have mechanisms (yet) to signal link capacities back to the endpoints.
Additionally, even if we knew the available physical bandwidth, that wouldn’t mean we could use all of it ourselves. Several users are typically active on a network concurrently, each of whom need a fair share of the available bandwidth.
As such, a connection doesn’t know how much bandwidth it can safely or fairly use up front, and this bandwidth can change as users join, leave, and use the network. To solve this problem, TCP will constantly try to discover the available bandwidth over time by using a mechanism called congestion control.
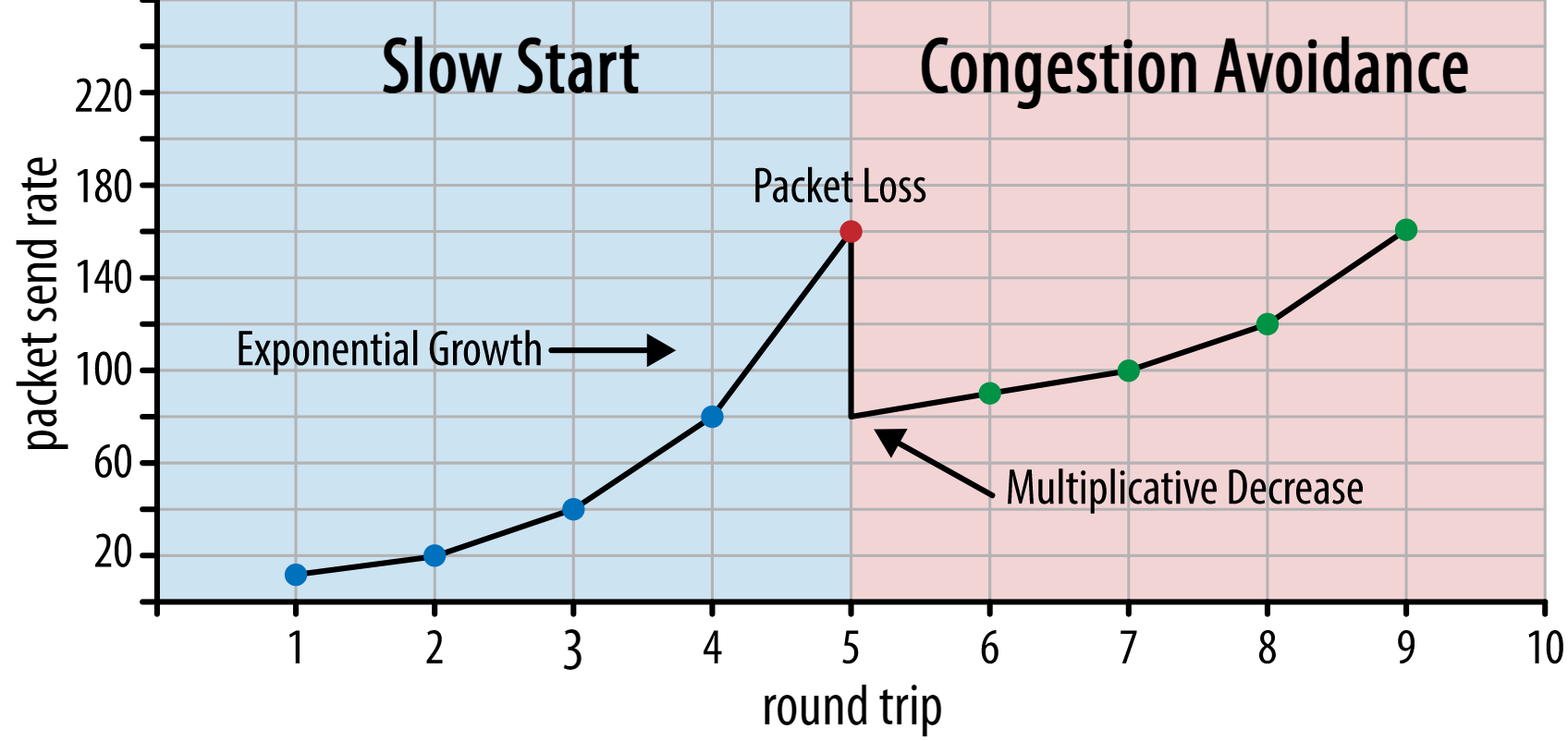
At the start of the connection, it sends just a few packets (in practice, ranging between 10 and 100 packets, or about 14 and 140 KB of data) and waits one round trip until the receiver sends back acknowledgements of these packets. If they are all acknowledged, this means the network can handle that send rate, and we can try to repeat the process but with more data (in practice, the send rate usually doubles with every iteration).
This way, the send rate continues to grow until some packets are not acknowledged (which indicates packet loss and network congestion). This first phase is typically called a “slow start”. Upon detection of packet loss, TCP reduces the send rate, and (after a while) starts to increase the send rate again, albeit in (much) smaller increments. This reduce-then-grow logic is repeated for every packet loss afterwards. Eventually, this means that TCP will constantly try to reach its ideal, fair bandwidth share. This mechanism is illustrated in figure 1.

This is an extremely oversimplified explanation of congestion control. In practice, many other factors are at play, such as bufferbloat, the fluctuation of RTTs due to congestion, and the fact that multiple concurrent senders need to get their fair share of the bandwidth. As such, many different congestion-control algorithms exist, and plenty are still being invented today, with none performing optimally in all situations.
While TCP’s congestion control makes it robust, it also means it takes a while to reach optimal send rates, depending on the RTT and actual available bandwidth. For web-page loading, this slow-start approach can also affect metrics such as the first contentful paint, because only a small amount of data (tens of to a few hundred KB) can be transferred in the first few round trips. (You might have heard the recommendation to keep your critical data to smaller than 14 KB.)
Choosing a more aggressive approach could thus lead to better results on high-bandwidth and high-latency networks, especially if you don’t care about the occasional packet loss. This is where I’ve again seen many misinterpretations about how QUIC works.
As discussed in part 1, QUIC, in theory, suffers less from packet loss (and the related head-of-line (HOL) blocking) because it treats packet loss on each resource’s byte stream independently. Additionally, QUIC runs over the User Datagram Protocol (UDP), which, unlike TCP, doesn’t have a congestion-control feature built in; it allows you to try sending at whatever rate you want and doesn’t retransmit lost data.
This has led to many articles claiming that QUIC also doesn’t use congestion control, that QUIC can instead start sending data at a much higher rate over UDP (relying on the removal of HOL blocking to deal with packet loss), that this is why QUIC is much faster than TCP.
In reality, nothing could be further from the truth: QUIC actually uses very similar bandwidth-management techniques as TCP. It too starts with a lower send rate and grows it over time, using acknowledgements as a key mechanism to measure network capacity. This is (among other reasons) because QUIC needs to be reliable in order to be useful for something such as HTTP, because it needs to be fair to other QUIC (and TCP!) connections, and because its HOL-blocking removal doesn’t actually help against packet loss all that well (as we’ll see below).
However, that doesn’t mean that QUIC can’t be (a bit) smarter about how it manages bandwidth than TCP. This is mainly because QUIC is more flexible and easier to evolve than TCP. As we’ve said, congestion-control algorithms are still heavily evolving today, and we will likely need to, for example, tweak things to get the most out of 5G.
However, TCP is typically implemented in the operating system’s (OS’) kernel, a secure and more restricted environment, which for most OSes isn’t even open source. As such, tuning congestion logic is usually only done by a select few developers, and evolution is slow.
In contrast, most QUIC implementations are currently being done in “user space” (where we typically run native apps) and are made open source, explicitly to encourage experimentation by a much wider pool of developers (as already shown, for example, by Facebook).
Another concrete example is the delayed acknowledgement frequency extension proposal for QUIC. While, by default, QUIC sends an acknowledgement for every 2 received packets, this extension allows endpoints to acknowledge, for example, every 10 packets instead. This has been shown to give large speed benefits on satellite and very high-bandwidth networks, because the overhead of transmitting the acknowledgement packets is lowered. Adding such an extension for TCP would take a long time to become adopted, while for QUIC it’s much easier to deploy.
As such, we can expect that QUIC’s flexibility will lead to more experimentation and better congestion-control algorithms over time, which could in turn also be backported to TCP to improve it as well.
Did You Know?
The official QUIC Recovery RFC 9002 specifies the use of the NewReno congestion-control algorithm. While this approach is robust, it’s also somewhat outdated and not used extensively in practice anymore. So, why is it in the QUIC RFC? The first reason is that when QUIC was started, NewReno was the most recent congestion-control algorithm that was itself standardized. More advanced algorithms, such as BBR and CUBIC, either are still not standardized or only recently became RFCs.
The second reason is that NewReno is a relatively simple set-up. Because the algorithms need a few tweaks to deal with QUIC’s differences from TCP, it’s easier to explain those changes on a simpler algorithm. As such, RFC 9002 should be read more as “how to adapt a congestion-control algorithm to QUIC”, rather than “this is the thing you should use for QUIC”. Indeed, most production-level QUIC implementations have made custom implementations of both Cubic and BBR.
It bears repeating that congestion-control algorithms are not TCP- or QUIC-specific; they can be used by either protocol, and the hope is that advances in QUIC will eventually find their way to TCP stacks as well.
Did You Know?
Note that, next to congestion control is a related concept called flow control. These two features are often confused in TCP, because they are both said to use the “TCP window”, although there are actually two windows: the congestion window and the TCP receive window. Flow control, however, comes into play a lot less for the use case of web-page loading that we’re interested in, so we’ll skip it here. More in-depth information is available.
What Does It All Mean?
QUIC is still bound by the laws of physics and the need to be nice to other senders on the Internet. This means that it will not magically download your website resources much more quickly than TCP. However, QUIC’s flexibility means that experimenting with new congestion-control algorithms will become easier, which should improve things in the future for both TCP and QUIC.
0-RTT Connection Set-Up
A second performance aspect is about how many round trips it takes before you can send useful HTTP data (say, page resources) on a new connection. Some claim that QUIC is two to even three round trips faster than TCP + TLS, but we’ll see that it’s really only one.
Did You Know?
As we’ve said in part 1, a connection typically performs one (TCP) or two (TCP + TLS) handshakes before HTTP requests and responses can be exchanged. These handshakes exchange initial parameters that both client and server need to know in order to, for example, encrypt the data.
As you can see in figure 2 below, each individual handshake takes at least one round trip to complete (TCP + TLS 1.3, (b)) and sometimes two (TLS 1.2 and prior (a)). This is inefficient, because we need at least two round trips of handshake waiting time (overhead) before we can send our first HTTP request, which means waiting at least three round trips for the first HTTP response data (the returning red arrow) to come in. On slow networks, this can mean an overhead of 100 to 200 milliseconds.
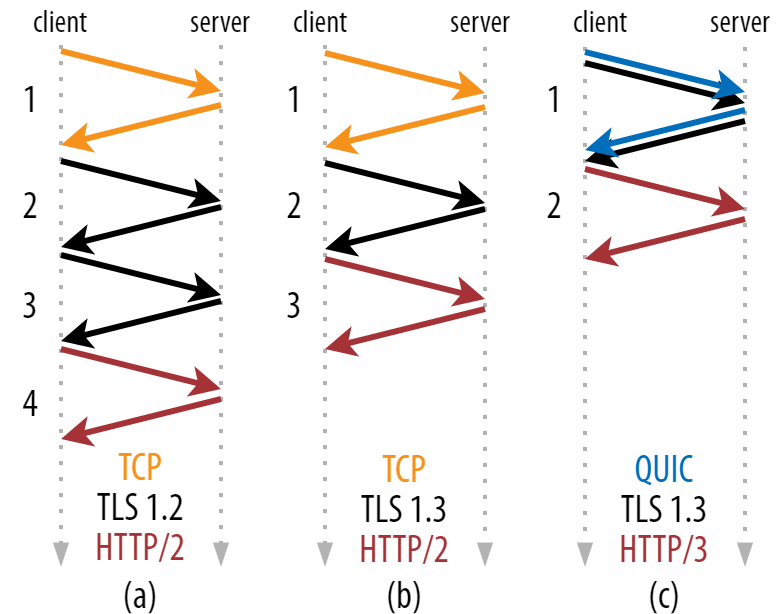
You might be wondering why the TCP + TLS handshake cannot simply be combined, done in the same round trip. While this is conceptually possible (QUIC does exactly that), things were initially not designed like this, because we need to be able to use TCP with and without TLS on top. Put differently, TCP simply does not support sending non-TCP stuff during the handshake. There have been efforts to add this with the TCP Fast Open extension; however, as discussed in part 1, this has turned out to be difficult to deploy at scale.
Luckily, QUIC was designed with TLS in mind from the start, and as such does combine both the transport and cryptographic handshakes in a single mechanism. This means that the QUIC handshake will take only one round trip in total to complete, which is one round trip less than TCP + TLS 1.3 (see figure 2c above).
You might be confused, because you’ve probably read that QUIC is two or even three round trips faster than TCP, not just one. This is because most articles only consider the worst case (TCP + TLS 1.2, (a)), not mentioning that the modern TCP + TLS 1.3 also “only” take two round trips ((b) is rarely shown). While a speed boost of one round trip is nice, it’s hardly amazing. Especially on fast networks (say, less than a 50-millisecond RTT), this will be barely noticeable, although slow networks and connections to distant servers would profit a bit more.
Next, you might be wondering why we need to wait for the handshake(s) at all. Why can’t we send an HTTP request in the first round trip? This is mainly because, if we did, then that first request would be sent unencrypted, readable by any eavesdropper on the wire, which is obviously not great for privacy and security. As such, we need to wait for the cryptographic handshake to complete before sending the first HTTP request. Or do we?
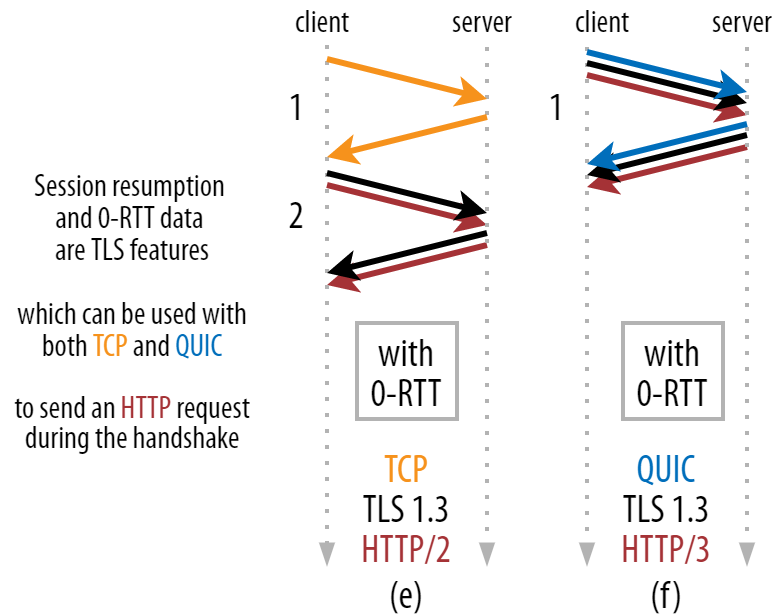
This is where a clever trick is used in practice. We know that users often revisit web pages within a short time of their first visit. As such, we can use the initial encrypted connection to bootstrap a second connection in the future. Simply put, sometime during its lifetime, the first connection is used to safely communicate new cryptographic parameters between the client and server. These parameters can then be used to encrypt the second connection from the very start, without having to wait for the full TLS handshake to complete. This approach is called “session resumption”.
It allows for a powerful optimization: We can now safely send our first HTTP request along with the QUIC/TLS handshake, saving another round trip! As for TLS 1.3, this effectively removes the TLS handshake’s waiting time. This method is often called 0-RTT (although, of course, it still takes one round trip for the HTTP response data to start arriving).
Both session resumption and 0-RTT are, again, things that I’ve often seen wrongly explained as being QUIC-specific features. In reality, these are actually TLS features that were already present in some form in TLS 1.2 and are now fully fledged in TLS 1.3.
Put differently, as you can see in figure 3 below, we can get the performance benefits of these features over TCP (and thus also HTTP/2 and even HTTP/1.1) as well! We see that even with 0-RTT, QUIC is still only one round trip faster than an optimally functioning TCP + TLS 1.3 stack. The claim that QUIC is three round trips faster comes from comparing figure 2’s (a) with figure 3’s (f), which, as we’ve seen, is not really fair.
The worst part is that when using 0-RTT, QUIC can’t even really use that gained round trip all that well due to security. To understand this, we need to understand one of the reasons why the TCP handshake exists. First, it allows the client to be sure that the server is actually available at the given IP address before sending it any higher-layer data.
Secondly, and crucially here, it allows the server to make sure that the client opening the connection is actually who and where they say they are before sending it data. If you recall how we defined a connection with the 4-tuple in part 1, you’ll know that the client is mainly identified by its IP address. And this is the problem: IP addresses can be spoofed!
Suppose that an attacker requests a very large file via HTTP over QUIC 0-RTT. However, they spoof their IP address, making it look like the 0-RTT request came from their victim’s computer. This is shown in figure 4 below. The QUIC server has no way of detecting whether the IP was spoofed, because this is the very first packet(s) it is seeing from that client.

If the server then simply starts sending the large file back to the spoofed IP, it could end up overloading the victim’s network bandwidth (especially if the attacker were to do many of these fake requests in parallel). Note that the QUIC response would be dropped by the victim, because it doesn’t expect incoming data, but that doesn’t matter: Their network still needs to process the packets!
This is called a reflection, or amplification, attack, and it’s a significant way that hackers execute distributed denial-of-service (DDoS) attacks. Note that this doesn’t happen when 0-RTT over TCP + TLS is being used, precisely because the TCP handshake needs to complete first before the 0-RTT request is even sent along with the TLS handshake.
As such, QUIC has to be conservative in replying to 0-RTT requests, limiting how much data it sends in response until the client has been verified to be a real client and not a victim. For QUIC, this data amount has been set to three times the amount received from the client.
Put differently, QUIC has a maximum “amplification factor” of three, which was determined to be an acceptable trade-off between performance usefulness and security risk (especially compared to some incidents that had an amplification factor of over 51,000 times). Because the client typically first sends just one to two packets, the QUIC server’s 0-RTT reply will be capped at just 4 to 6 KB (including other QUIC and TLS overhead!), which is somewhat less than impressive.
In addition, other security problems can lead to, for example, “replay attacks”, which limit the type of HTTP request you can do. For example, Cloudflare only allows HTTP GET requests without query parameters in 0-RTT. These limit the usefulness of 0-RTT even more.
Luckily, QUIC has options to make this a bit better. For example, the server can check whether the 0-RTT comes from an IP that it has had a valid connection with before. However, that only works if the client stays on the same network (somewhat limiting QUIC’s connection migration feature). And even if it works, QUIC’s response is still limited by the congestion controller’s slow-start logic that we discussed above; so, there is no extra massive speed boost besides the one round trip saved.
Did You Know?
It’s interesting to note that QUIC’s three-times amplification limit also counts for its normal non-0-RTT handshake process in figure 2c. This can be a problem if, for example, the server’s TLS certificate is too large to fit inside 4 to 6 KB. In that case, it would have to be split, with the second chunk having to wait for the second round trip to be sent (after acknowledgements of the first few packets come in, indicating that the client’s IP was not spoofed). In this case, QUIC’s handshake might still end up taking two round trips, equal to TCP + TLS! This is why for QUIC, techniques such as certificate compression will be extra important.
Did You Know?
It could be that certain advanced set-ups are able to mitigate these problems enough to make 0-RTT more useful. For example, the server could remember how much bandwidth a client had available the last time it was seen, making it less limited by the congestion control’s slow start for reconnecting (non-spoofed) clients. This has been investigated in academia, and there’s even a proposed extension in QUIC to do this. Several companies already do this type of thing to speed up TCP as well.
Another option would be to have clients send more than one or two packets (for example, sending 7 more packets with padding), so the three-times limit translates to a more interesting 12- to 14-KB response, even after connection migration. I’ve written about this in one of my papers.
Finally, (misbehaving) QUIC servers could also intentionally increase the three-times limit if they feel it’s somehow safe to do so or if they don’t care about the potential security issues (after all, there’s no protocol police preventing this).
What Does It All Mean?
QUIC’s faster connection set-up with 0-RTT is really more of a micro-optimization than a revolutionary new feature. Compared to a state-of-the art TCP + TLS 1.3 set-up, it would save a maximum of one round trip. The amount of data that can actually be sent in the first round trip is additionally limited by a number of security considerations.
As such, this feature will mostly shine either if your users are on networks with very high latency (say, satellite networks with more than 200-millisecond RTTs) or if you typically don’t send much data. Some examples of the latter are heavily cached websites, as well as single-page apps that periodically fetch small updates via APIs and other protocols such as DNS-over-QUIC. One of the reasons Google saw very good 0-RTT results for QUIC was that it tested it on its already heavily optimized search page, where query responses are quite small.
In other cases, you’ll gain only a few dozens of milliseconds at best, even less if you’re already using a CDN (which you should be doing if you care about performance!).
Connection Migration
A third performance feature makes QUIC faster when transferring between networks, by keeping existing connections intact. While this indeed works, this type of network change doesn’t happen all that often and connections still need to reset their send rates.
As discussed in part 1, QUIC’s connection IDs (CIDs) allow it to perform connection migration when switching networks. We illustrated this with a client moving from a Wi-Fi network to 4G while doing a large file download. On TCP, that download might have to be aborted, while for QUIC it might continue.
First, however, consider how often that type of scenario actually happens. You might think this also occurs when moving between Wi-Fi access points within a building or between cellular towers while on the road. In those set-ups, however (if they’re done correctly), your device will typically keep its IP intact, because the transition between wireless base stations is done at a lower protocol layer. As such, it occurs only when you move between completely different networks, which I’d say doesn’t happen all that often.
Secondly, we can ask whether this also works for other use cases besides large file downloads and live video conferencing and streaming. If you’re loading a web page at the exact moment of switching networks, you might have to re-request some of the (later) resources indeed.
However, loading a page typically takes in the order of seconds, so that coinciding with a network switch is also not going to be very common. Additionally, for use cases where this is a pressing concern, other mitigations are typically already in place. For example, servers offering large file downloads can support HTTP range requests to allow resumable downloads.
Because there is typically some overlap time between network 1 dropping off and network 2 becoming available, video apps can open multiple connections (1 per network), syncing them before the old network goes away completely. The user will still notice the switch, but it won’t drop the video feed entirely.
Thirdly, there is no guarantee that the new network will have as much bandwidth available as the old one. As such, even though the conceptual connection is kept intact, the QUIC server cannot just keep sending data at high speeds. Instead, to avoid overloading the new network, it needs to reset (or at least lower) the send rate and start again in the congestion controller’s slow-start phase.
Because this initial send rate is typically too low to really support things such as video streaming, you will see some quality loss or hiccups, even on QUIC. In a way, connection migration is more about preventing connection context churn and overhead on the server than about improving performance.
Did You Know?
Note that, as discussed for 0-RTT above, we can devise some advanced techniques to improve connection migration. For example, we can, again, try to remember how much bandwidth was available on a given network last time and attempt to ramp up faster to that level for a new migration. Additionally, we could envision not simply switching between networks, but using both at the same time. This concept is called multipath, and we discuss it in more detail below.
So far, we have mainly talked about active connection migration, where users move between different networks. There are, however, also cases of passive connection migration, where a certain network itself changes parameters. A good example of this is network address translation (NAT) rebinding. While a full discussion of NAT is out of the scope of this article, it mainly means that the connection’s port numbers can change at any given time, without warning. This also happens much more often for UDP than TCP in most routers.
If this occurs, the QUIC CID will not change, and most implementations will assume that the user is still on the same physical network and will thus not reset the congestion window or other parameters. QUIC also includes some features such as PINGs and timeout indicators to prevent this from happening, because this typically occurs for long-idle connections.
We discussed in part 1 that QUIC doesn’t just use a single CID for security reasons. Instead, it changes CIDs when performing active migration. In practice, it’s even more complicated, because both client and server have separate lists of CIDs, (called source and destination CIDs in the QUIC RFC). This is illustrated in figure 5 below.
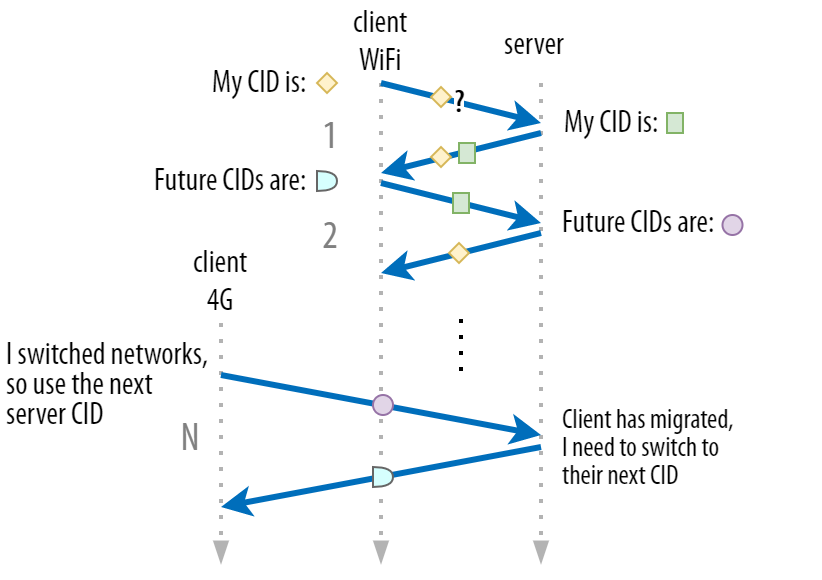
This is done to allow each endpoint to choose its own CID format and contents, which in turn is crucial to allowing advanced routing and load-balancing logic. With connection migration, load balancers can no longer just look at the 4-tuple to identify a connection and send it to the correct back-end server. However, if all QUIC connections were to use random CIDs, this would heavily increase memory requirements at the load balancer, because it would need to store mappings of CIDs to back-end servers. Additionally, this would still not work with connection migration, as the CIDs change to new random values.
As such, it’s important that QUIC back-end servers deployed behind a load balancer have a predictable format of their CIDs, so that the load balancer can derive the correct back-end server from the CID, even after migration. Some options for doing this are described in the IETF’s proposed document. To make this all possible, the servers need to be able to choose their own CID, which wouldn’t be possible if the connection initiator (which, for QUIC, is always the client) chose the CID. This is why there is a split between client and server CIDs in QUIC.
What Does It All Mean?
Thus, connection migration is a situational feature. Initial tests by Google, for example, show low percentage improvements for its use cases. Many QUIC implementations don’t yet implement this feature. Even those that do will typically limit it to mobile clients and apps and not their desktop equivalents. Some people are even of the opinion that the feature isn’t needed, because opening a new connection with 0-RTT should have similar performance properties in most cases.
Still, depending on your use case or user profile, it could have a large impact. If your website or app is most often used while on the move (say, something like Uber or Google Maps), then you’d probably benefit more than if your users were typically sitting behind a desk. Similarly, if you’re focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-Of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP’s bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we’ve also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC, where we change the active stream in each packet (let’s call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC, where each stream is completed in full before starting the next one (let’s call this sequential). Of course, many other options are possible in between these extremes (AAAABBCAAAAABBC…, AABBCCAABBCC…, ABABABCCCC…, etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I’ve written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
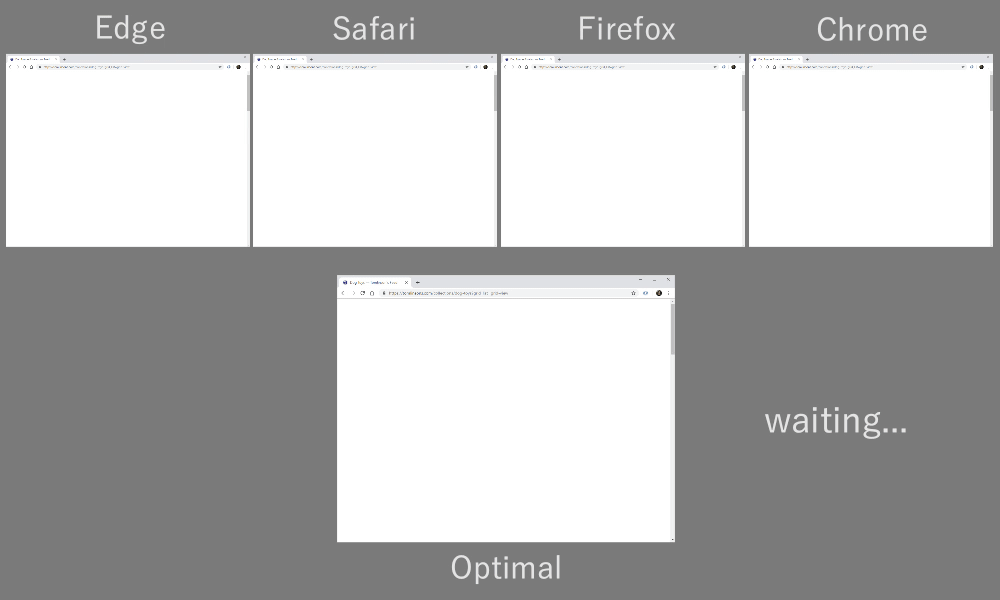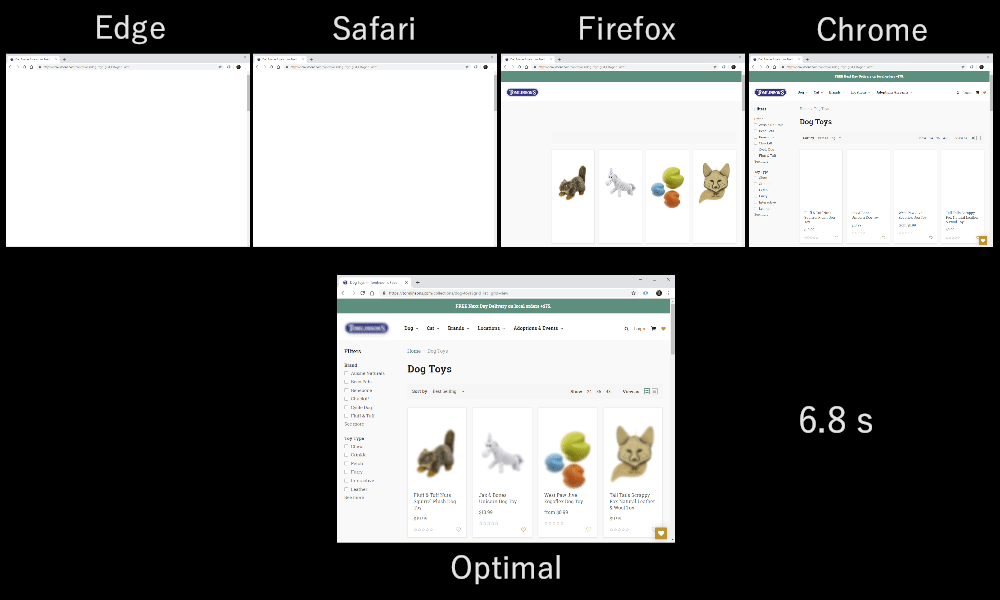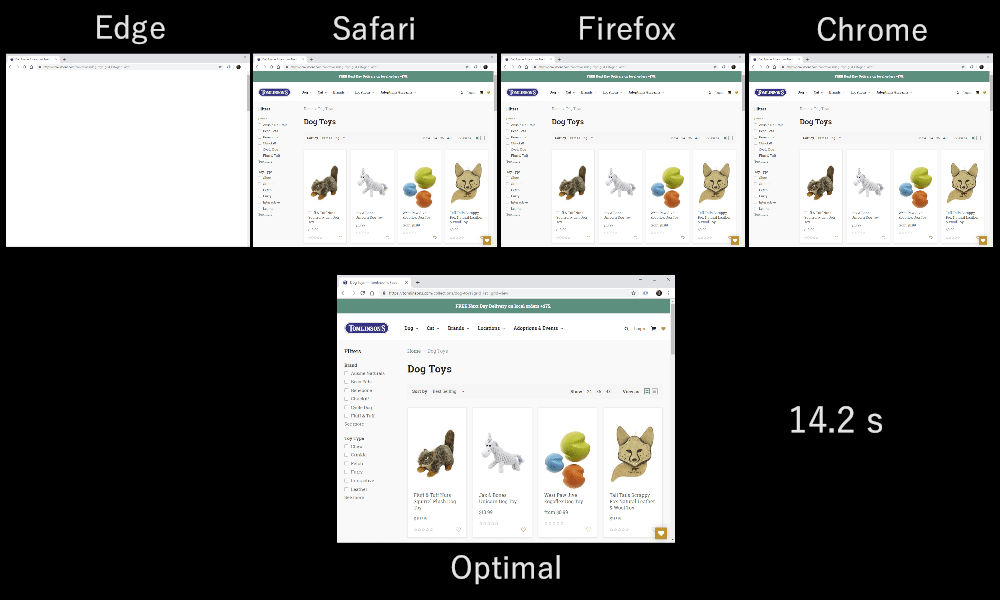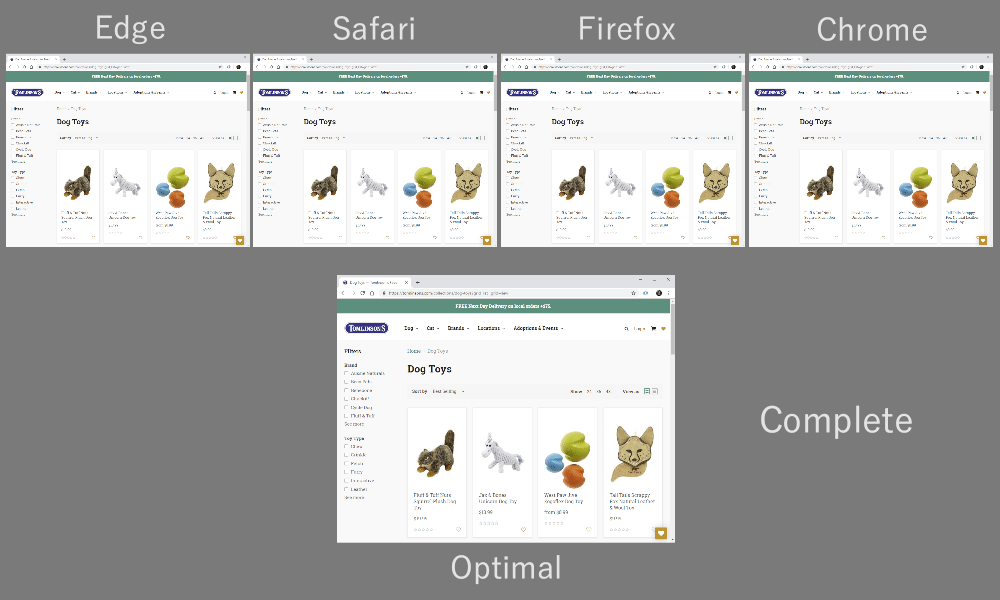
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What’s more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let’s contemplate what would happen if A, B, and C were all render-blocking resources.
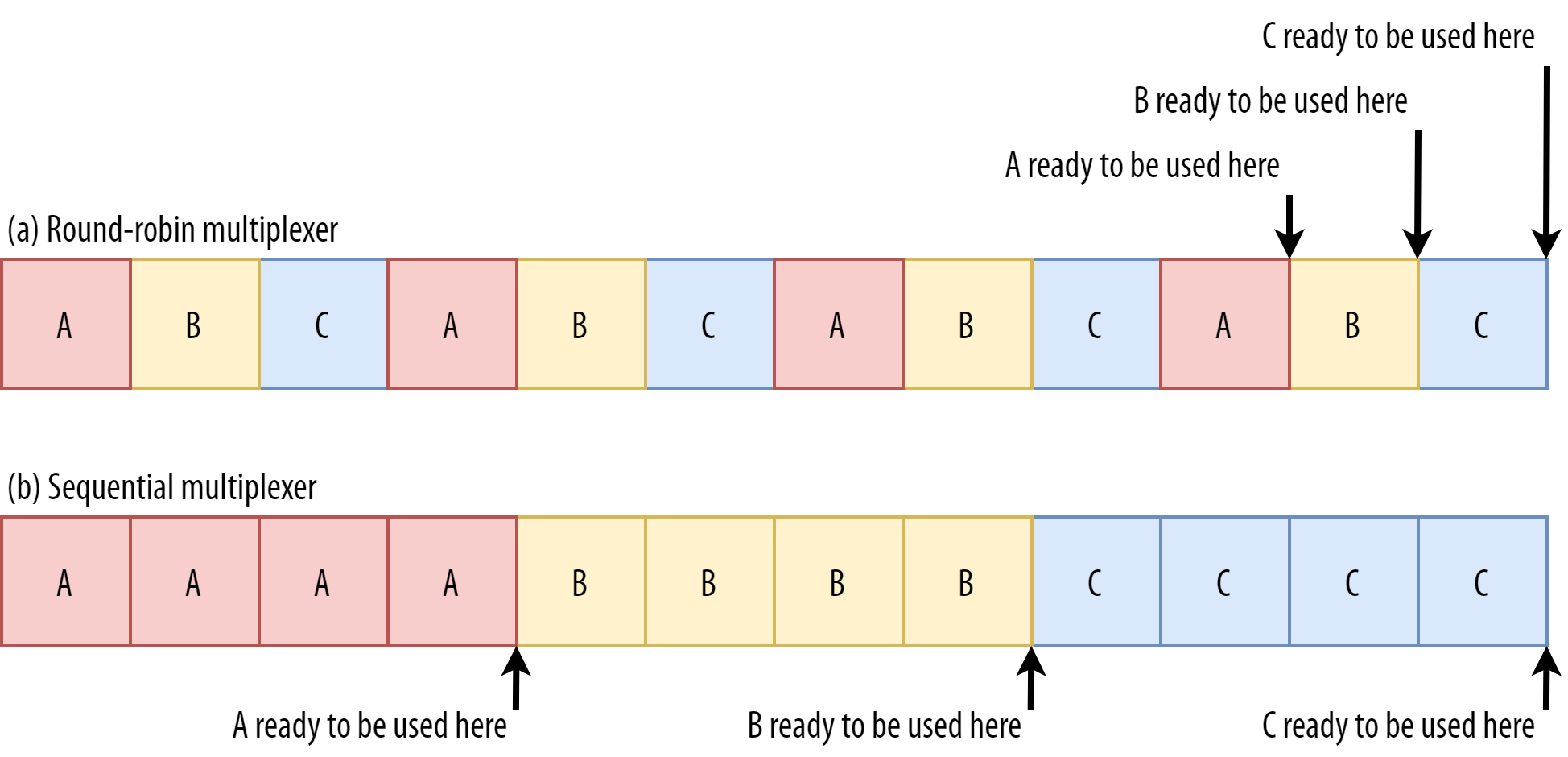
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource’s total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C’s completion time.
However, that doesn’t mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally. In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best. This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren’t always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we’ve just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We’d rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC’s HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it’s high priority and render-blocking — think main.js), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A: All of the data is for A, and so everything would still have to wait (we don’t have B or C data to process), similar to TCP.
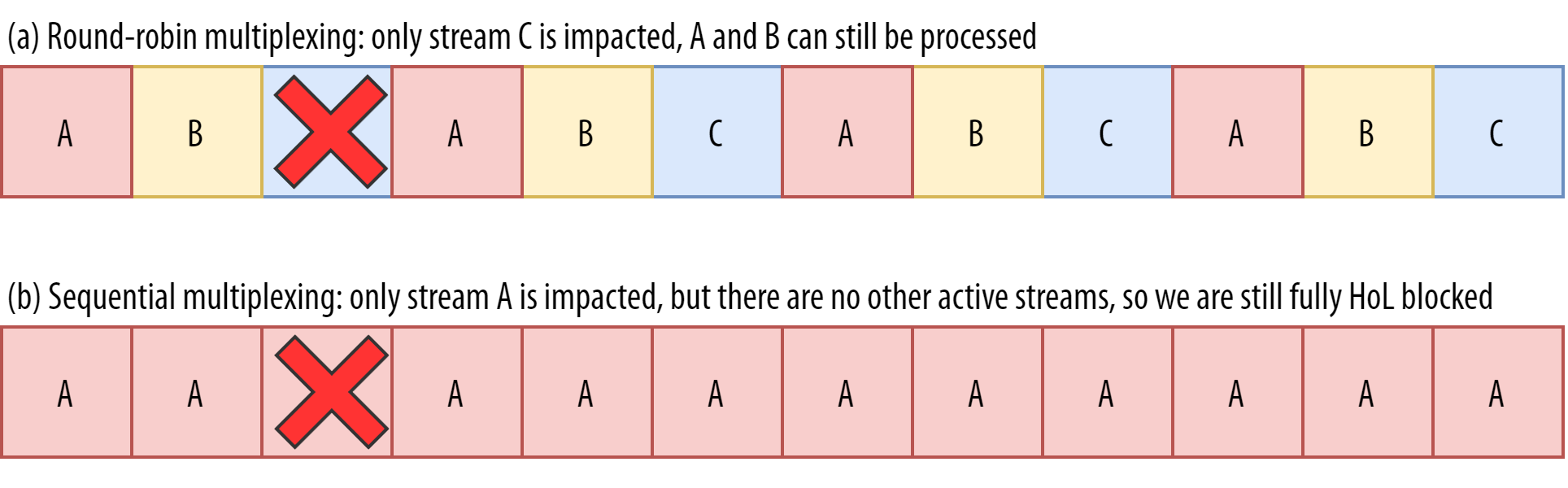
We see that we have a kind of contradiction: Sequential multiplexing (AAAABBBBCCCC) is typically better for web performance, but it doesn’t allow us to take much advantage of QUIC’s HoL blocking removal. Round-robin multiplexing (ABCABCABCABC) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another.
And it gets worse. Up until now, we’ve sort of assumed that individual packets get lost one at a time. However, this isn’t always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time.
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that’s intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don’t lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let’s say we are using a per-packet round-robin multiplexer (ABCABCABCABCABCABCABCABC…) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC’s HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions.
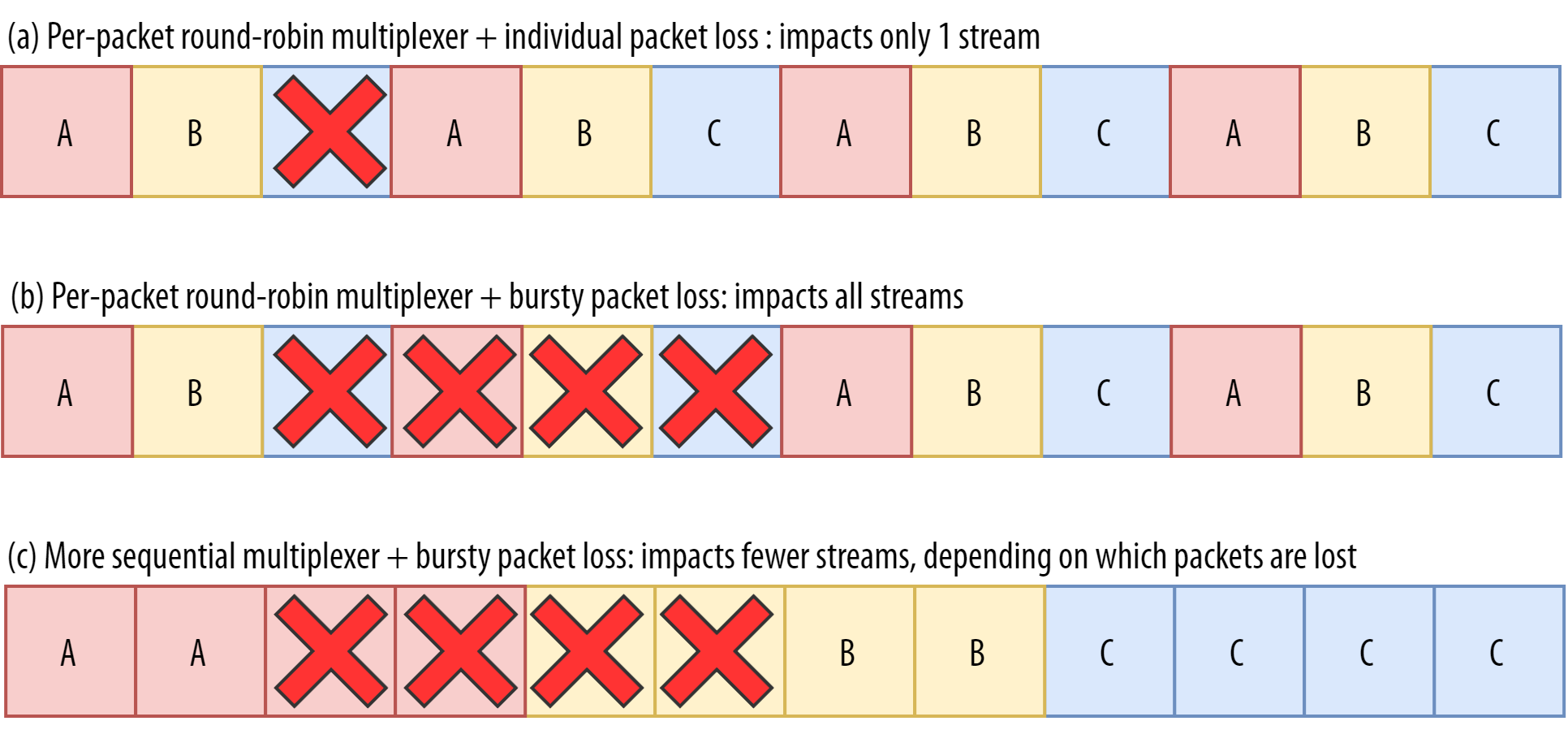
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC’s HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don’t send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don’t keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don’t necessarily lower its burstiness.
What Does It All Mean?
While QUIC’s HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users. However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
UDP And TLS Performance
A fifth performance aspect of QUIC and HTTP/3 is about how efficiently and performantly they can actually create and send packets on the network. We will see that QUIC’s usage of UDP and heavy encryption can make it a fair bit slower than TCP (but things are improving).
First, we’ve already discussed that QUIC’s usage of UDP was more about flexibility and deployability than about performance. This is evidenced even more by the fact that, up until recently, sending QUIC packets over UDP was typically much slower than sending TCP packets. This is partly because of where and how these protocols are typically implemented (see figure 9 below).
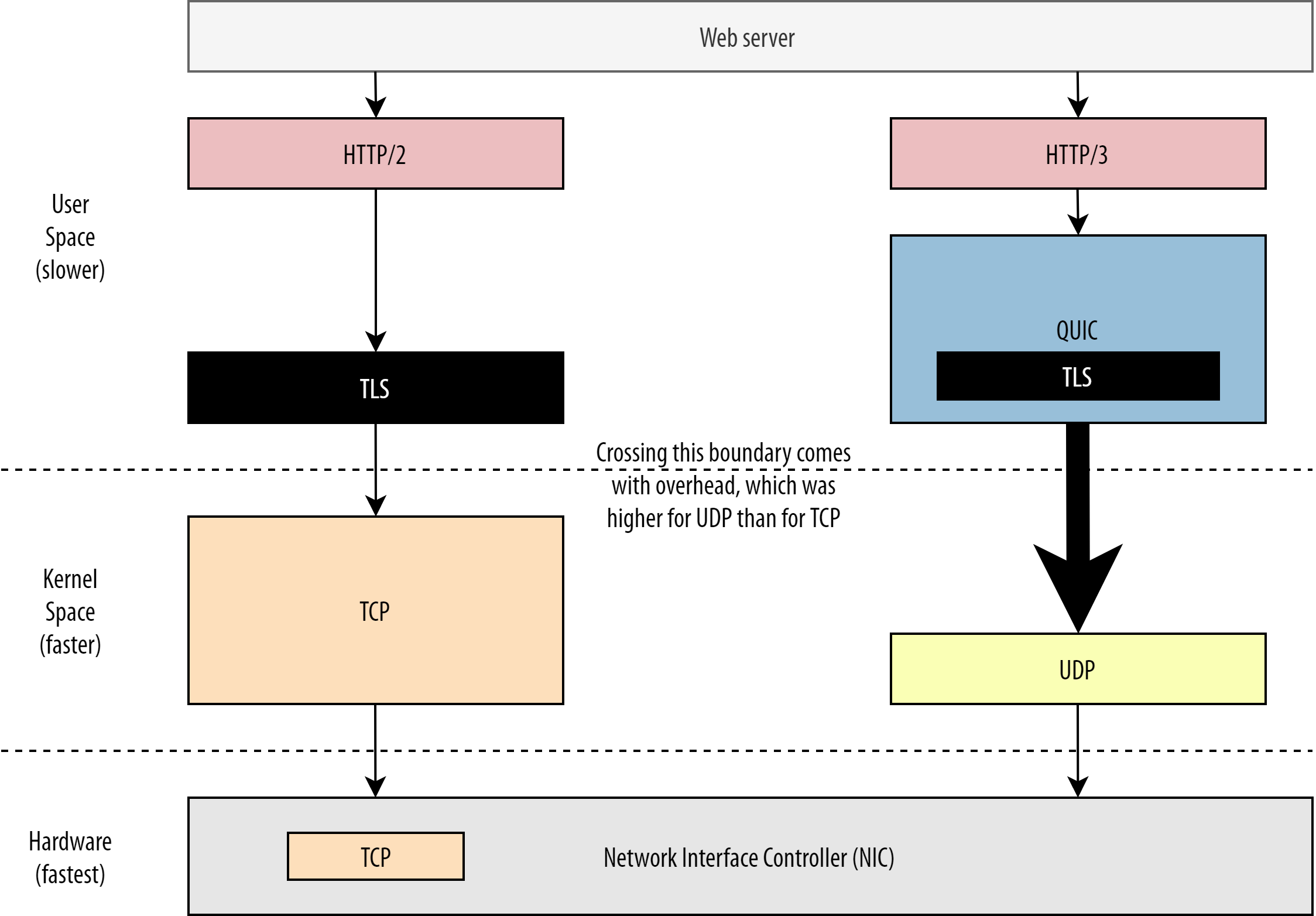
As discussed above, TCP and UDP are typically implemented directly in the OS’ fast kernel. In contrast, TLS and QUIC implementations are mostly in slower user space (note that this is not really needed for QUIC — it is mostly done because it’s much more flexible). This makes QUIC already a bit slower than TCP.
Additionally, when sending data from our user-space software (say, browsers and web servers), we need to pass this data to the OS kernel, which then uses TCP or UDP to actually put it on the network. Passing this data is done using kernel APIs (system calls), which involves a certain amount of overhead per API call. For TCP, these overheads were much lower than for UDP.
This is mostly because, historically, TCP has been used a lot more than UDP. As such, over time, many optimizations were added to TCP implementations and kernel APIs to reduce packet send and receive overheads to a minimum. Many network interface controllers (NICs) even have built-in hardware-offload features for TCP. UDP, however, was not as lucky, because its more limited use didn’t justify the investment in added optimizations. In the past five years, this has luckily changed, and most OSes have since added optimized options for UDP as well.
Secondly, QUIC has a lot of overhead because it encrypts each packet individually. This is slower than using TLS over TCP, because there you can encrypt packets in chunks (up to about 16 KB or 11 packets at a time), which is more efficient. This was a conscious trade-off made in QUIC, because bulk encryption can lead to its own forms of HoL blocking.
Unlike the first point, where we could add extra APIs to make UDP (and thus QUIC) faster, here, QUIC will always have an inherent disadvantage to TCP + TLS. However, this is also quite manageable in practice with, for example, optimized encryption libraries and clever methods that allow QUIC packets headers to be encrypted in bulk.
As a result, while Google’s earliest QUIC versions were still twice as slow as TCP + TLS, things have certainly improved since. For example, in recent tests, Microsoft’s heavily optimized QUIC stack was able to get 7.85 Gbps, compared to 11.85 Gbps for TCP + TLS on the same system (so here, QUIC is about 66% as fast as TCP + TLS).
This is with the recent Windows updates, which made UDP faster (for a full comparison, UDP throughput on that system was 19.5 Gbps). The most optimized version of Google’s QUIC stack is currently about 20% slower than TCP + TLS. Earlier tests by Fastly on a less advanced system and with a few tricks even claim equal performance (about 450 Mbps), showing that depending on the use case, QUIC can definitely compete with TCP.
However, even if QUIC were twice as slow as TCP + TLS, it’s not all that bad. First, QUIC and TCP + TLS processing is typically not the heaviest thing happening on a server, because other logic (say, HTTP, caching, proxying, etc.) also needs to execute. As such, you won’t actually need twice as many servers to run QUIC (it’s a bit unclear how much impact it will have in a real data center, though, because none of the big companies have released data on this).
Secondly, there are still plenty of opportunities to optimize QUIC implementations in the future. For example, over time, some QUIC implementations will (partially) move to the OS kernel (much like TCP) or bypass it (some already do, like MsQuic). We can also expect QUIC-specific hardware to become available.
Still, there will likely be some use cases for which TCP + TLS will remain the preferred option. For example, Netflix has indicated that it probably won’t move to QUIC anytime soon, having heavily invested in custom FreeBSD set-ups to stream its videos over TCP + TLS.
Similarly, Facebook has said that QUIC will probably mainly be used between end users and the CDN’s edge, but not between data centers or between edge nodes and origin servers, due to its larger overhead. In general, very high-bandwidth scenarios will probably continue to favour TCP + TLS, especially in the next few years.
Did You Know?
Optimizing network stacks is a deep and technical rabbit hole of which the above merely scratches the surface (and misses a lot of nuance). If you’re brave enough or if you want to know what terms likeGRO/GSO,SO_TXTIME, kernel bypass, andsendmmsg()andrecvmmsg()mean, I can recommend some excellent articles on optimizing QUIC by Cloudflare and Fastly, as well as an extensive code walkthrough by Microsoft, and an in-depth talk from Cisco. Finally, a Google engineer gave a very interesting keynote about optimizing their QUIC implementation over time.
What Does It All Mean?
QUIC’s particular usage of the UDP and TLS protocols has historically made it much slower than TCP + TLS. However, over time, several improvements have been made (and will continue to be implemented) that have closed the gap somewhat. You probably won’t notice these discrepancies in typical use cases of web-page loading, though, but they might give you headaches if you maintain large server farms.
HTTP/3 Features
Up until now, we’ve mainly talked about new performance features in QUIC versus TCP. However, what about HTTP/3 versus HTTP/2? As discussed in part 1, HTTP/3 is really HTTP/2-over-QUIC, and as such, no real, big new features were introduced in the new version. This is unlike the move from HTTP/1.1 to HTTP/2, which was much larger and introduced new features such as header compression, stream prioritization, and server push. These features are all still in HTTP/3, but there are some important differences in how they are implemented under the hood.
This is mostly because of how QUIC’s removal of HoL blocking works. As we’ve discussed, a loss on stream B no longer implies that streams A and C will have to wait for B’s retransmissions, like they did over TCP. As such, if A, B, and C each sent a QUIC packet in that order, their data might well be delivered to (and processed by) the browser as A, C, B! Put differently, unlike TCP, QUIC is no longer fully ordered across different streams!
This is a problem for HTTP/2, which really relied on TCP’s strict ordering in the design of many of its features, which use special control messages interspersed with data chunks. In QUIC, these control messages might arrive (and be applied) in any order, potentially even making the features do the opposite of what was intended! The technical details are, again, unnecessary for this article, but the first half of this paper should give you an idea of how stupidly complex this can get.
As such, the internal mechanics and implementations of the features have had to change for HTTP/3. A concrete example is HTTP header compression, which lowers the overhead of repeated large HTTP headers (for example, cookies and user-agent strings). In HTTP/2, this was done using the HPACK set-up, while for HTTP/3 this has been reworked to the more complex QPACK. Both systems deliver the same feature (i.e. header compression) but in quite different ways. Some excellent deep technical discussion and diagrams on this topic can be found on the Litespeed blog.
Something similar is true for the prioritization feature that drives stream multiplexing logic and which we’ve briefly discussed above. In HTTP/2, this was implemented using a complex “dependency tree” set-up, which explicitly tried to model all page resources and their interrelations (more information is in the talk “The Ultimate Guide to HTTP Resource Prioritization”). Using this system directly over QUIC would lead to some potentially very wrong tree layouts, because adding each resource to the tree would be a separate control message.
Additionally, this approach turned out to be needlessly complex, leading to many implementation bugs and inefficiencies and subpar performance on many servers. Both problems have led the prioritization system to be redesigned for HTTP/3 in a much simpler way. This more straightforward set-up makes some advanced scenarios difficult or impossible to enforce (for example, proxying traffic from multiple clients on a single connection), but still enables a wide range of options for web-page loading optimization.
While, again, the two approaches deliver the same basic feature (guiding stream multiplexing), the hope is that HTTP/3’s easier set-up will make for fewer implementation bugs.
Finally, there is server push. This feature allows the server to send HTTP responses without waiting for an explicit request for them first. In theory, this could deliver excellent performance gains. In practice, however, it turned out to be hard to use correctly and inconsistently implemented. As a result, it is probably even going to be removed from Google Chrome.
Despite all this, it is still defined as a feature in HTTP/3 (although few implementations support it). While its internal workings haven’t changed as much as the previous two features, it too has been adapted to work around QUIC’s non-deterministic ordering. Sadly, though, this will do little to solve some of its longstanding issues.
What Does It All Mean?
As we’ve said before, most of HTTP/3’s potential comes from the underlying QUIC, not HTTP/3 itself. While the protocol’s internal implementation is very different from HTTP/2’s, its high-level performance features and how they can and should be used have stayed the same.
Future Developments To Look Out For
In this series, I have regularly highlighted that faster evolution and higher flexibility are core aspects of QUIC (and, by extension, HTTP/3). As such, it should be no surprise that people are already working on new extensions to and applications of the protocols. Listed below are the main ones that you’ll probably encounter somewhere down the line:
- Forward error correction
This purpose of this technique is, again, to improve QUIC’s resilience to packet loss. It does this by sending redundant copies of the data (though cleverly encoded and compressed so that they’re not as large). Then, if a packet is lost but the redundant data arrives, a retransmission is no longer needed.
This was originally a part of Google QUIC (and one of the reasons why people say QUIC is good against packet loss), but it is not included in the standardized QUIC version 1 because its performance impact wasn’t proven yet. Researchers are now performing active experiments with it, though, and you can help them out by using the PQUIC-FEC Download Experiments app. - Multipath QUIC
We’ve previously discussed connection migration and how it can help when moving from, say, Wi-Fi to cellular. However, doesn’t that also imply we might use both Wi-Fi and cellular at the same time? Concurrently using both networks would give us more available bandwidth and increased robustness! That is the main concept behind multipath.
This is, again, something that Google experimented with but that didn’t make it into QUIC version 1 due to its inherent complexity. However, researchers have since shown its high potential, and it might make it into QUIC version 2. Note that TCP multipath also exists, but that has taken almost a decade to become practically usable. - Unreliable data over QUIC and HTTP/3
As we’ve seen, QUIC is a fully reliable protocol. However, because it runs over UDP, which is unreliable, we can add a feature to QUIC to also send unreliable data. This is outlined in the proposed datagram extension. You would, of course, not want to use this to send web page resources, but it might be handy for things such as gaming and live video streaming. This way, users would get all of the benefits of UDP but with QUIC-level encryption and (optional) congestion control. - WebTransport
Browsers don’t expose TCP or UDP to JavaScript directly, mainly due to security concerns. Instead, we have to rely on HTTP-level APIs such as Fetch and the somewhat more flexible WebSocket and WebRTC protocols. The newest in this series of options is called WebTransport, which mainly allows you to use HTTP/3 (and, by extension, QUIC) in a more low-level way (although it can also fall back to TCP and HTTP/2 if needed).
Crucially, it will include the ability to use unreliable data over HTTP/3 (see the previous point), which should make things such as gaming quite a bit easier to implement in the browser. For normal (JSON) API calls, you’ll, of course, still use Fetch, which will also automatically employ HTTP/3 when possible. WebTransport is still under heavy discussion at the moment, so it’s not yet clear what it will eventually look like. Of the browsers, only Chromium is currently working on a public proof-of-concept implementation. - DASH and HLS video streaming
For non-live video (think YouTube and Netflix), browsers typically make use of the Dynamic Adaptive Streaming over HTTP (DASH) or HTTP Live Streaming (HLS) protocols. Both basically mean that you encode your videos into smaller chunks (of 2 to 10 seconds) and different quality levels (720p, 1080p, 4K, etc.).
At runtime, the browser estimates the highest quality your network can handle (or the most optimal for a given use case), and it requests the relevant files from the server via HTTP. Because the browser doesn’t have direct access to the TCP stack (as that’s typically implemented in the kernel), it occasionally makes a few mistakes in these estimates, or it takes a while to react to changing network conditions (leading to video stalls).
Because QUIC is implemented as part of the browser, this could be improved quite a bit, by giving the streaming estimators access to low-level protocol information (such as loss rates, bandwidth estimates, etc.). Other researchers have been experimenting with mixing reliable and unreliable data for video streaming as well, with some promising results. - Protocols other than HTTP/3
With QUIC being a general purpose transport protocol, we can expect many application-layer protocols that now run over TCP to be run on top of QUIC as well. Some works in progress include DNS-over-QUIC, SMB-over-QUIC, and even SSH-over-QUIC. Because these protocols typically have very different requirements than HTTP and web-page loading, QUIC’s performance improvements that we’ve discussed might work much better for these protocols.
What Does It All Mean?
QUIC version 1 is just the start. Many advanced performance-oriented features that Google had earlier experimented with did not make it into this first iteration. However, the goal is to quickly evolve the protocol, introducing new extensions and features at a high frequency. As such, over time, QUIC (and HTTP/3) should become clearly faster and more flexible than TCP (and HTTP/2).
Conclusion
In this second part of the series, we have discussed the many different performance features and aspects of HTTP/3 and especially QUIC. We have seen that while most of these features seem very impactful, in practice they might not do all that much for the average user in the use case of web-page loading that we’ve been considering.
For example, we’ve seen that QUIC’s use of UDP doesn’t mean that it can suddenly use more bandwidth than TCP, nor does it mean that it can download your resources more quickly. The often-lauded 0-RTT feature is really a micro-optimization that saves you one round trip, in which you can send about 5 KB (in the worst case).
HoL blocking removal doesn’t work well if there is bursty packet loss or when you’re loading render-blocking resources. Connection migration is highly situational, and HTTP/3 doesn’t have any major new features that could make it faster than HTTP/2.
As such, you might expect me to recommend that you just skip HTTP/3 and QUIC. Why bother, right? However, I will most definitely do no such thing! Even though these new protocols might not aid users on fast (urban) networks much, the new features do certainly have the potential to be highly impactful to highly mobile users and people on slow networks.
Even in Western markets such as my own Belgium, where we generally have fast devices and access to high-speed cellular networks, these situations can affect 1% to even 10% of your user base, depending on your product. An example is someone on a train trying desperately to look up a critical piece of information on your website, but having to wait 45 seconds for it to load. I certainly know I’ve been in that situation, wishing someone had deployed QUIC to get me out of it.
However, there are other countries and regions where things are much worse still. There, the average user might look a lot more like the slowest 10% in Belgium, and the slowest 1% might never get to see a loaded page at all. In many parts of the world, web performance is an accessibility and inclusivity problem.
This is why we should never just test our pages on our own hardware (but also use a service like Webpagetest) and also why you should definitely deploy QUIC and HTTP/3. Especially if your users are often on the move or unlikely to have access to fast cellular networks, these new protocols might make a world of difference, even if you don’t notice much on your cabled MacBook Pro. For more details, I highly recommend Fastly’s post on the issue.
If that doesn’t fully convince you, then consider that QUIC and HTTP/3 will continue to evolve and get faster in the years to come. Getting some early experience with the protocols will pay off down the road, allowing you to reap the benefits of new features as soon as possible. Additionally, QUIC enforces security and privacy best practices in the background, which benefit all users everywhere.
Finally convinced? Then continue to part 3 of the series to read about how you can go about using the new protocols in practice.
- Part 1: HTTP/3 History And Core Concepts
This article is targeted at people new to HTTP/3 and protocols in general, and it mainly discusses the basics. - Part 2: HTTP/3 Performance Features
This one is more in depth and technical. People who already know the basics can start here. - Part 3: Practical HTTP/3 Deployment Options
This third article in the series explains the challenges involved in deploying and testing HTTP/3 yourself. It details how and if you should change your web pages and resources as well.
Further Reading
- How To Hack Your Google Lighthouse Scores In 2024
- Passkeys: A No-Frills Explainer On The Future Of Password-Less Authentication
- Level Up Your CSS Skills With The :has() Selector
- The Modern Guide For Making CSS Shapes



{kind=link}