Databases For Front-End Developers: The Concepts Under The Hood (Part 2)

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Celebrating 10 million developers
Celebrating 10 million developers


 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.
In Part 1, The Rise Of Serverless Databases, of the “Databases For Front-End Developers” series, we talked about the hurdles and traps of scaling and maintaining your databases. We went from simpler and specialized alternatives like Content Management Systems and spreadsheets to self-hosted databases and, finally, to Serverless Databases.
Today, we go deeper into the rabbit hole. We will explore concepts to equip you to have your own opinions about which kinds of databases suit your specific needs. And this is important to stress up front: there is no right answer. Each database carries its own set of tradeoffs and advantages. If something looks like a “one-size-fits-all” solution, be careful: you might be missing something!
Anatomy Of A Database
Before we begin, it’s important to highlight that what we loosely refer to as “databases” are actually “Database Management Systems (DBMS).” A DBMS is a piece of software that enables the user to more ergonomically write, read, delete, or update information in a given set of data. For this series, we will focus mainly on Relational and Non-Relational DBMSs. There are many other types, all categorized by their data structures, but relational and non-relational are the most common for web development by any measure.
Both Relational (R) and Non-Relational (NR) DBMS have different terms for the parts that compose them. Such components are almost interchangeable in definition, and that’s why you can commonly hear a developer referring to a Document (NR term) as “Table,” which is its Relational equivalent structure. Don’t be afraid of confusing them; they appear often enough for this cognitive overload to disappear quickly with usage. Additionally, once you get more familiar with the differences of each data structure, you will realize they probably shouldn’t be used interchangeably because there are differences among them. But for now, and for the sake of simplicity, let’s focus on the similarities:
- Schema
It’s the description of the database (like a blueprint), describing the landscape of the database in a supported language. This is required by relational databases, and though not required by non-relational DBMS, many interfaces offer a possibility to define it too. - Tables (R/NR), Collections (NR)
It’s the logical data structure, unsorted. A relatable example of this would be a spreadsheet table or a group (collection) of JSON objects. - Databases (R/NR)
It’s the logical grouping of data. You group your tables in databases (user database, invoices databases) and your documents in indexes based on how you intend to query them.
Keys And Columns
To use a more familiar example, let’s take a JSON object as an example:
{
"name": "Atila"
"role": "DX Engineer at Xata"
}
Given that JSON, a column would be represented by the key-value pair (column name has value “Atila”), and the key follows the same meaning as the JSON spec, key name will access the value “Atila.”
A table has columns, and each column’s name determines the key with which you can access a value in a record.
In addition to the above definition, there are special kinds of keys. Such keys play a special role in the schema of your database and how you will interact with your data. Define these wisely: any minimal change to them can be considered a breaking change to your data layer.
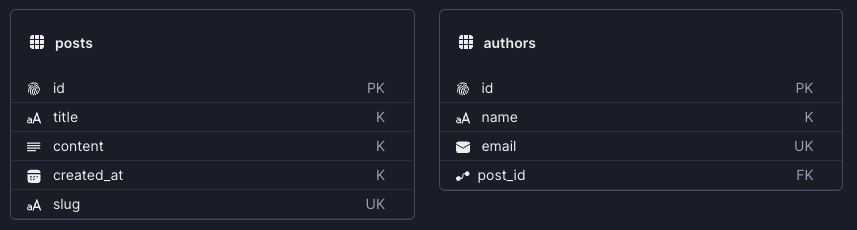
- Unique Keys (UK)
The keys that are unique between records on a table. They also acceptnull. - Primary Keys (PK)
It’s a special kind of Unique Key. There can only be one Primary Key per table, and it can never benull(Primary Keys are always consideredrequired). Primary Keys are also indexed by default, helping with queries that want to filter on the value. - Foreign Keys (FK)
When there is a relation between tables, the keys are represented as foreign keys at the extraneous table.
Example of Foreign Key: if each author in an authors table has posts (and posts is another table), post.title will be a FK at authors. And the junction between authors and posts is called a relation.
Mapping Your DBMS
Once you look at the different data structures and choose your DBMS, you are ready to draw the first connection from your data layer to your application layer. And suddenly, you noticed it isn’t quite straightforward to bring data from the database to your client-side (or even to your server-side API in some cases).
Here comes ORM (Object Relational Mapping) and ODM (Object Document Mapping) to assist your developer experience. Prisma is probably the most widely used ORM at the moment, while Mongoose has the largest ODM user base. It’s important to note they are not a requirement for connecting to databases. Still, if you keep an eye on how they build your queries (some specific cases can present performance issues on the account of the abstraction), they tend to make your life easier and fetching or writing data much more ergonomic.
When it comes to serverless databases, the need for them becomes a bit more questionable. And this is because many of these databases provide the users with an officially supported Software Development Kit (SDK). Your mileage will vary depending on the SDK, but they tend to have a big feature overlap with ORMs and ODMs, especially on databases that will keep the data layer behind an API (Xata, for example). This way, you won’t need to worry about translating your queries, and you can demand equivalent ergonomics between the SDK and an ORM.
Common Concepts
In this part of our series, we are learning what to look for when choosing the stack for our data layers. It is essential to understand common concepts around maintaining and choosing a DBMS (from here on out, we’re back into referring to them as “databases” to remain consistent with the rest of the world).
The next sections will not go so deep that you jump out and find a job as Database Administrator (DBA), but hopefully, it will offer you enough ammo to engage in conversation with experts and identify the best solution for your use cases. These concepts are common for every kind of data layer, from a spreadsheet to a self-hosted database and even to a serverless database. What will vary is how each solution will balance the variables intertwined in these paradigms.

The most important concepts, to begin with, are Consistency, Availability, and Partition Tolerance. They’re better understood if presented together because the balance between them will guide how predictable your data is in different contexts.
CAP Theorem
This theorem describes the relationship between 3 components in a distributed system: Consistency, Availability, and Partition tolerance (C.A.P). The overall conclusion is easy to summarize: any system is only able to contemplate 2 of these components at the same time. Though just a simple sentence, this idea requires a bit of unpacking.
Consistency (C)
Within the CAP Theorem constraints, “consistency” refers directly to the data. When different clients make the same request, they will get the same response. When a written request is accepted and confirmed, all users will have access to this updated information at the same time.
Availability (A)
Every request will receive a response with data. No errors. However, this comes with no promises on whether the data is up to date or not. Depending on whether this is paired with consistency © or partition tolerance (P), you will get different behavior.
Partition Tolerance (P)
A “partition” is when the connection between two nodes in a system is broken. The CAP Theorem essentially describes how a system will tolerate the partition: enforcing availability (AP system) or enforcing consistency (CP system). Regardless of how small a system is, partitions can always happen. Therefore there is no such thing as a CA system.
To provide a more graphical example of each system, we can consider:
- AP System
Another node has a copy of the data. The user will get information back but without promises of it being 100% correct (up-to-date). It’s commonly implemented with DynamoDB, Cassandra, and so on. - CP System
To return an error and accept the transaction is impossible. It’s commonly implemented with traditional sharded DBs, Citus, for example.
Though popular and very often referred to, the CAP Theorem can be considered incomplete because it doesn’t consider situations beyond the network partition. Especially today, with high-availability content delivery networks (CDN), and extreme connectivity, it’s crucial to take into consideration latency and deeper aspects of consistency (linearizability and serializability).
Consistency Confusion
It’s funny how “consistency” is a term that switches meanings based on the context. So, in the CAP Theorem, as we just saw, it’s all about data and how reliably a user will get the same response to the same request regardless of which partition they reach. Once we take a step away from our own system, a new perspective makes us ask: “how consistently will we handle concurrent operations?”. And just like that, the CAP Theorem does not sufficiently describe the intricacies of operating at scale.
There is a third meaning of “consistency,” which we will save for later; it’s part of yet another acronym (ACID). If the last paragraph left you scratching your head, I can’t recommend enough “Inconsistent Thoughts on Database Consistency” by Alex DeBrie.
PACELC Theorem
The first three letters are the same as CAP, just reordered. The “consistency” in the PACELC Theorem goes deeper than in the CAP Theorem. It follows the Consistency Model, which determines the contract between a data store and a system. To make things less complicated, consider the PACELC an extension of the CAP Theorem.
Beyond asking the developer to strategize for the event of a network partition, the PACELC also considers what happens when the system has no partitions (healthy network).
ELC stands for Else: Latency or Consistency?
- Latency: Can you accept an occasional stale response for the sake of performance?
- Consistency:
- Linearizability: Will you accept a higher latency to sync data in all nodes of a network before considering the transaction done?
- Serializability: In the event of concurrent transactions on the same data, will you handle them in parallel or in a queue?
Because of this, I consider the PACELC carries a better mental model for this new era of Serverless Databases. When healthy, it’s not a scalar classification “AP” or “CP”; it accepts a spectrum because latency can be high or not, and consistency can have different levels as well.
Once we start talking about the types of databases and their data structures and which guarantees each can give, we will also talk about a bit of system architecture and how your architecture can reduce the tradeoffs when even by enforcing consistency, you can strive for a low latency scenario.
See You Next Time
With that, I believe we are ready to start narrowing down our discussions on the differences between each database type. Moreover, it’s possible to discuss and level expectations on each solution taken and analyze architectures individually. From now on, we will focus on Relational and Non-Relational databases.
In a few days, on our season finale, we will cover the differences between NoSQL and SQL: what guarantees to expect, what that means to your data, and how that affects development workflow. Then we will be ready to jump right into Serverless Databases and what to expect going forward. I can’t wait!
As usual, feel free to reach out to me with feedback, questions, and/or requests for the next part.


