Knip: An Automated Tool For Finding Unused Files, Exports, And Dependencies

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.


 Custom Web Forms for Angular, React, & Vue. Your backend.
Custom Web Forms for Angular, React, & Vue. Your backend.
 Celebrating 10 million developers
Celebrating 10 million developers
Let’s face it. Most of us favor creating new features and user interfaces over maintenance tasks such as code cleanup, project configuration, and dependency management.
Lots of the boring and repetitive things, like formatting and linting, are mostly solved problems with tools like Prettier, ESLint, and TypeScript.
Yet there’s another area that often doesn’t receive much attention: handling unused files, exports, and dependencies. This is especially true as projects grow over time, negatively impacting maintainability as well as our enthusiasm for it. These unused artifacts often go unnoticed because they’re typically hard to find.
Where do you start looking for unused things? I bet you’ve done a global search for a dependency to find out whether it’s still used. Did you know you can right-click a file and “Find File References” in VS Code? These are the things you shouldn’t have to do. They’re tedious tasks that can — and should — be automated.
There’s Got to Be a Better Way
When I was in an expanding codebase, the number of unused files and exports in it kept growing. Tracking them became more and more difficult, so I started looking for automated solutions to help.
I was happy I found some existing tools, such as ts-prune. After some initial runs, I discovered that our codebase required a lot of configuration and still produced many false positives. I researched how other codebases try to stay tidy and realized there’s a huge opportunity in this space.
Along the road, I also found depcheck, which deals with a lot of complexity and customizations in JavaScript projects. And then there’s unimported, which also does a notable job of finding dangling files and unused dependencies.
But none of these tools handled my project very well. The fact that I would have to use a combination of them wouldn’t be a showstopper, but I couldn’t get the configurations right for handling the project’s customizations without reporting too many false positives or ignoring too much of the project and leaving a large blind spot.
In the end, tools in this area are only used when they are fully automated and able to cover the whole project. It also didn’t help that none of the existing tools support monorepos, a structure for repositories that has recently gained widespread popularity. Last but not least, both ts-prune and depcheck are in maintenance mode, meaning they would likely never support monorepos.
Working Towards A Solution
I’m motivated to automate things and keep projects in solid shape.
Great developer experience (DX) keeps developers happy and productive.
“
So I started developing an internal tool for my project to see if I could do better. It started as an internal script that handled only the specifics of that particular repository, and throughout the journey, I kept realizing what a blessing and a curse this is. Automating boring stuff is a winning concept, but getting it right is such a difficult challenge — but one that I was willing to try.
Along the road, I also got more and more convinced that a single tool to find all categories of unused things was a good idea: each of them requires reading and parsing source files, and since this is a relatively expensive task, I think the efficient path is to track them in one go.
Introducing Knip
So, what is Knip? I think it’s best categorized as a project linter. It picks up where ESLint ends. Where ESLint handles individual files, Knip lints the repository as a whole. It connects all the dots — in terms of files, imports, exports, and dependencies — and reports what is unused.
Roughly speaking, there are two ways to look at Knip. In greenfield projects, it’s great to install Knip and let it grow with the project. Keep the repository tidy and run Knip manually or in an automated continuous integration (CI) environment.
Another way to look at Knip is in larger projects. Knip is a great companion for housekeeping as far as identifying unused files, exports, and dependencies. There may be false positives initially, but it’s much easier to skip them compared to finding needles in a haystack on your own.
Additionally, during or after large refactoring efforts, Knip can be a great assistant for cleaning things up. It’s only human to miss or forget things that are no longer used, even more so when the things are not close to the refactoring work.
Knip works with traditional JavaScript and modern TypeScript, has built-in support for monorepos, works with any package manager, and has many features, small and large, that help you maintain your projects.
How Knip Works
Knip starts with one or more entry files and calculates the dependency tree, helping it know all the files that are used while marking the remaining files as unused.
Meanwhile, Knip keeps track of imported external dependencies and compares them against the dependencies in package.json to report both unused dependencies and dependencies that are used but not listed. It also keeps track of internal imports and exports to report unused exports.
Let me give you a better look under the hood.
Production Mode
In its default mode, Knip analyzes the whole project, including both production and non-production files, such as tests, configurations, Storybook stories, devDependencies, and so on.
But this mode might miss opportunities for trimming. For instance, files or exports imported only by tests are normally not reported as unused. However, when the export is not used anywhere else, you can delete both the export and its tests!
This is why Knip has a production mode. This mode is more strict than the default mode, where Knip will use only production code as entry files and only consider dependencies (excluding devDependencies).
Scripts
Many projects use command line tools that come with dependencies. For instance, after installing ESLint, you can use eslint, and Angular makes ng available in "scripts" in package.json. Knip connects dependencies with binaries and tells you when they are unused or missing.
But there’s more. CI environments, like Azure and GitHub Actions, are configured with YAML files that may also use the same command line tools.
And finally, custom scripts may use command line tools by spawning child processes, either using native Node.js APIs or with libraries like zx or execa.
Knip has a growing number of such detections to keep your projects neat and tidy, refactor after refactor. Yet what is so interesting about those scripts? They may be complicated to parse, making it difficult to extract their dependencies. Let’s look at an example:
node -r @scope/package/register --experimental-loader ts-node/esm/transpile-only ./dir
Here, we can find @scope/package and ts-node and dir/index.ts are dependencies of this script. Honestly, this is just the tip of the iceberg. I promise a few regular expressions won’t be enough!
Now, if this script is updated or removed, Knip will tell you if any dependency or file is no longer used. On the other hand, Knip will also tell you if a dependency is used but not listed explicitly in package.json. (You shouldn’t be relying on transitive dependencies anyway, right?)
Plugins
There’s an abundance of tooling available in the JavaScript ecosystem. And each tool has its configurations. Some allow YAML or JSON, and some allow (or require) you to write configurations in JavaScript or even TypeScript.
Since there’s no generic way to handle the myriad of variations, Knip supports plugins. Knip has plugins for tools that may reference dependencies that should be listed in package.json.
What matters to plugins is how dependencies are referenced. They might be imported in JavaScript like any other source file, and Knip can also parse them as such. Yet, they’re often referenced as strings, much the same as what ESLint does with the extends and plugins options. Dependencies can be specified in implicit ways, such as prettier, which means the eslint-config-prettier dependency. Storybook has the builder: "webpack5" configuration that requires the @storybook/builder-webpack5 and @storybook/manager-webpack5 dependencies.
Compilers
Knip parses all sorts of JavaScript and TypeScript files, including ES modules and CommonJS modules.
But some frameworks work with non-standard files, such as Vue, Svelte, MDX, and Astro. Knip allows you to configure compilers to include these types of files so they can also be included in the analysis.
Performance
Until version 2, Knip used ts-morph to calculate the dependency graph (and much more). This worked great initially because it abstracted away the TypeScript back end.
But to support monorepos and compilers while maintaining good performance, I realized I had to work with the TypeScript back end directly. This required a lot of effort, but it does provide a lot more flexibility, as well as opportunities for more optimizations. For example, Knip can traverse the abstract syntax tree (AST) of any file only once to find everything it needs.
Configuration Hints
When Knip reports a false positive, you can configure it to ignore that dependency. Then, when Knip no longer reports the false positive, it will report that the configuration can be updated, and you can remove the ignored items.
Reporters
Knip comes with a default reporter and has a few additional reporters. There’s a compact reporter, a JSON reporter, and one that uses the CODEOWNERS file to show the code owner(s) with each reported issue.
Knip also allows you to define a custom reporter. Knip will call your function with the results of the analysis. You can then do anything with it, like writing the results to a file or sending it to a service to track progress over time.
What’s Next For Knip?
Naturally, I’m not done working on Knip. These are a few of the things I have in mind.
More Plugins = Less Configuration
My hope with Knip is that as more and more people start to use Knip, they will report false positives: something is reported as unused but is in use.
A false positive usually has one of the following three causes:
- A framework or tool is used that Knip does not yet have a plugin for,
- The configuration might need improvement; for instance, add an entry file that Knip didn’t know about or ignore something with a hard-to-find reference, or
- Knip has a bug.
As Knip becomes better with bug fixes and plugins, more projects benefit because they need less configuration. Maintenance will become more enjoyable and easier for everyone!
When you are using Knip and enjoying it, don’t let false positives scare you away, but report them instead. Please provide a reproducible test case, and I’m sure we can work it out. Additionally, I’ve written a complete guide detailing how to write a new plugin for Knip.
Auto-Fix
Much like ESLint, Knip will have a --fix option to automatically fix all sorts of issues. The idea is that this can automatically take care of things such as:
- Remove the
exportkeyword for unused exports, - Uninstall unused dependencies and install unlisted dependencies, and
- Delete unused files.
Given enough interest from the community, I’m excited to start building this feature!
Integrations
Integrations such as a VS Code plugin or a GitHub Action sound like cool opportunities. I’m happy to collaborate and see where we can take it.
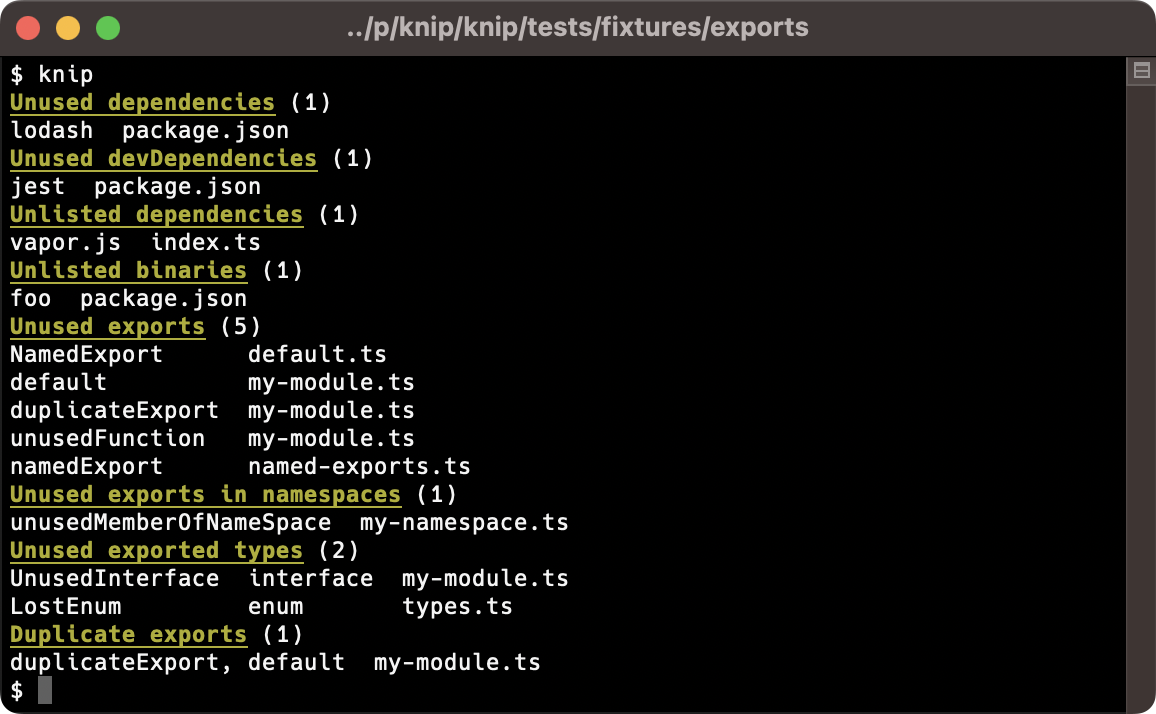
Demo Knip
I think the best way to understand Knip is to get your hands on it. So, I’ve created a CodeSandbox template that you can fork and spin up Knip in a new terminal with npm run knip.
Conclusion
Knip aims to help you maintain your JavaScript or TypeScript repositories, and I’m very happy lots of projects are already cut by Knip daily.
There is lots of room for improvement, bugs to fix, documentation to improve, and plugins to add! Your ideas and contributions are absolutely welcome — and encouraged — over at github.com/webpro/knip.


