Designing For Agentic AI: Practical UX Patterns For Control, Consent, And Accountability

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Celebrating 10 million developers
Celebrating 10 million developers
 Try ProtoPie AI free →
Try ProtoPie AI free → SurveyJS: White-Label Survey Solution for Your JS App
SurveyJS: White-Label Survey Solution for Your JS App
 Register Free Now
Register Free Now
In the first part of this series, we established the fundamental shift from generative to agentic artificial intelligence. We explored why this leap from suggesting to acting demands a new psychological and methodological toolkit for UX researchers, product managers, and leaders. We defined a taxonomy of agentic behaviors, from suggesting to acting autonomously, outlined the essential research methods, defined the risks of agentic sludge, and established the accountability metrics required to navigate this new territory. We covered the what and the why.
Now, we move from the foundational to the functional. This article provides the how: the concrete design patterns, operational frameworks, and organizational practices essential for building agentic systems that are not only powerful but also transparent, controllable, and worthy of user trust. If our research is the diagnostic tool, these patterns are the treatment plan. They are the practical mechanisms through which we can give users a palpable sense of control, even as we grant AI unprecedented autonomy. The goal is to create an experience where autonomy feels like a privilege granted by the user, not a right seized by the system.
Core UX Patterns For Agentic Systems
Designing for agentic AI is designing for a relationship. This relationship, like any successful partnership, must be built on clear communication, mutual understanding, and established boundaries.
To manage the shift from suggestion to action, we utilize six patterns that follow the functional lifecycle of an agentic interaction:
- Pre-Action (Establishing Intent)
The Intent Preview and Autonomy Dial ensure the user defines the plan and the agent’s boundaries before anything happens. - In-Action (Providing Context)
The Explainable Rationale and Confidence Signal maintain transparency while the agent works, showing the “why” and “how certain.” - Post-Action (Safety and Recovery)
The Action Audit & Undo and Escalation Pathway provide a safety net for errors or high-ambiguity moments.
Below, we will cover each pattern in detail, including recommendations for metrics for success. These targets are representative benchmarks based on industry standards; adjust them based on your specific domain risk.
1. The Intent Preview: Clarifying the What and How
This pattern is the conversational equivalent of saying, “Here’s what I’m about to do. Are you okay with that?” It’s the foundational moment of seeking consent in the user-agent relationship.
Before an agent takes any significant action, the user must have a clear, unambiguous understanding of what is about to happen. The Intent Preview, or Plan Summary, establishes informed consent. It is the conversational pause before action, transforming a black box of autonomous processes into a transparent, reviewable plan.
Psychological Underpinning
Presenting a plan before action reduces cognitive load and eliminates surprise, giving users a moment to verify the agent truly understands their intent.
Anatomy of an Effective Intent Preview:
- Clarity and Conciseness
The preview must be immediately digestible. It should summarize the primary actions and outcomes in plain language, avoiding technical jargon. For instance, instead of “Executing API call to cancel_booking(id: 4A7B),” it should state, “Cancel flight AA123 to San Francisco.” - Sequential Steps
For multi-step operations, the preview should outline the key phases. This reveals the agent’s logic and allows users to spot potential issues in the proposed sequence. - Clear User Actions
The preview is a decision point, not just a notification. It must be accompanied by a clear set of choices. It’s a moment of intentional friction, a ‘speed bump’ in the process designed to ensure the user is making a conscious choice, particularly for irreversible or high-stakes actions.
Let’s revisit our travel assistant scenario from the first part of this series. We use this proactive assistant to illustrate how an agent handles a flight cancellation. The agent has detected a flight cancellation and has formulated a recovery plan.
The Intent Preview would look something like this:
Proposed Plan for Your Trip Disruption
I’ve detected that your 10:05 AM flight has been canceled. Here’s what I plan to do:[ Proceed with this Plan ] [ Edit Plan ] [ Handle it Myself ]
- Cancel Flight UA456
Process refund and confirm cancellation details.- Rebook on Flight DL789
Book a confirmed seat on a 2:30 PM non-stop flight, as this is the next available non-stop flight with a confirmed seat.- Update Hotel Reservation
Notify the Marriott that you will be arriving late.- Email Updated Itinerary
Send the new flight and hotel details to you and your assistant, Jane Doe.
This preview is effective because it provides a complete picture, from cancellation to communication, and offers three distinct paths forward: full consent (Proceed), a desire for modification (Edit Plan), or a full override (Handle it Myself). This multifaceted control is the bedrock of trust.
When to Prioritize This Pattern
This pattern is non-negotiable for any action that is irreversible (e.g., deleting user data), involves a financial transaction of any amount, shares information with other people or systems, or makes a significant change that a user cannot easily undo.
Risk of Omission
Without this, users feel ambushed by the agent’s actions and will disable the feature to regain control.
Metrics for Success:
- Acceptance Ratio
Plans Accepted Without Edit / Total Plans Displayed. Target > 85%. - Override Frequency
Total Handle it Myself Clicks / Total Plans Displayed. A rate > 10% triggers a model review. - Recall Accuracy
Percentage of test participants who can correctly list the plan’s steps 10 seconds after the preview is hidden.
Applying This to High-Stakes Domains
While travel plans are a relatable baseline, this pattern becomes indispensable in complex, high-stakes environments where an error results in more than an inconvenience for an individual traveling. Many of us work in settings where wrong decisions may result in a system outage, putting a patient’s safety at risk, or numerous other catastrophic outcomes that unreliable technology would introduce.
Consider a DevOps Release Agent tasked with managing cloud infrastructure. In this context, the Intent Preview acts as a safety barrier against accidental downtime.
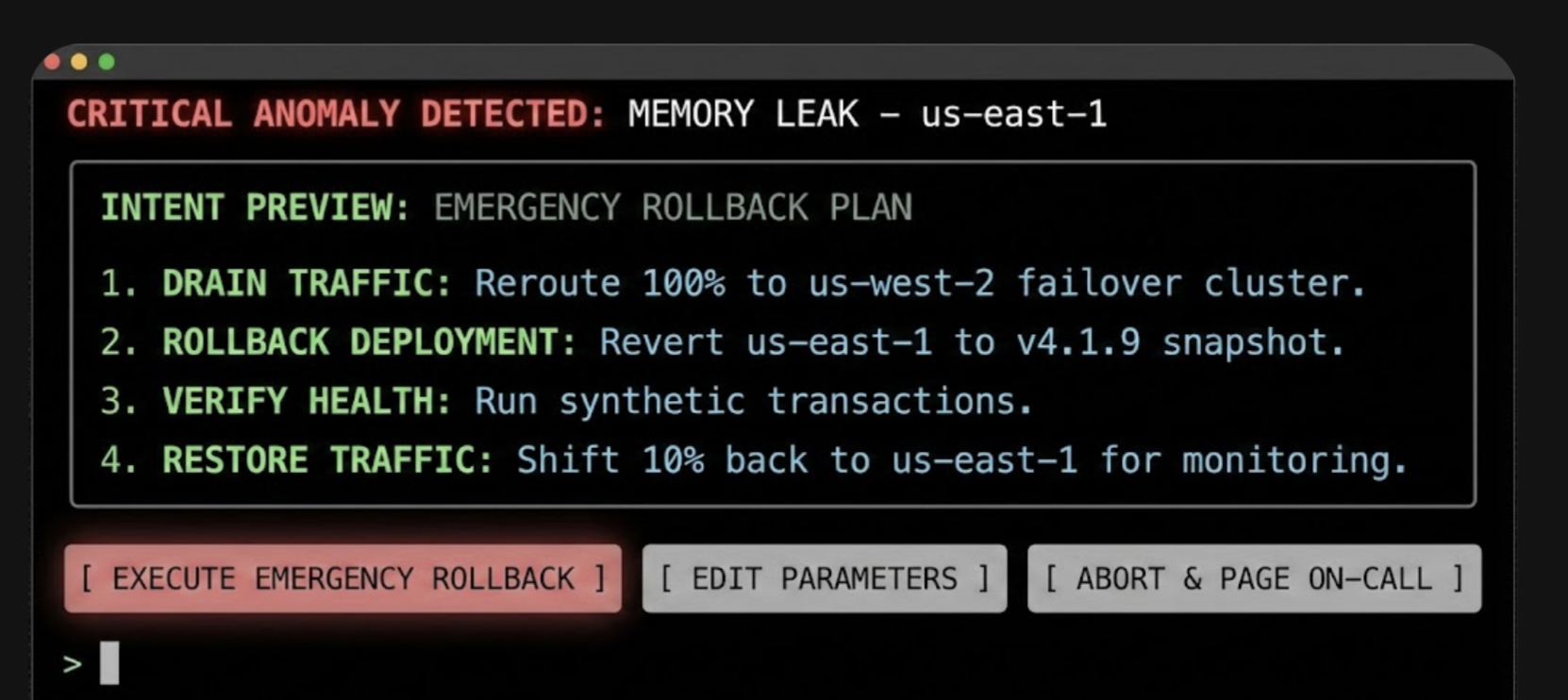
In this interface, the specific terminology (Drain Traffic, Rollback) replaces generalities, and the actions are binary and impactful. The user authorizes a major operational shift based on the agent’s logic, rather than approving a suggestion.
2. The Autonomy Dial: Calibrating Trust With Progressive Authorization
Every healthy relationship has boundaries. The Autonomy Dial is how the user establishes it with their agent, defining what they are comfortable with the agent handling on its own.
Trust is not a binary switch; it’s a spectrum. A user might trust an agent to handle low-stakes tasks autonomously but demand full confirmation for high-stakes decisions. The Autonomy Dial, a form of progressive authorization, allows users to set their preferred level of agent independence, making them active participants in defining the relationship.
Psychological Underpinning
Allowing users to tune the agent’s autonomy grants them a locus of control, letting them match the system’s behavior to their personal risk tolerance.
Implementation
This can be implemented as a simple, clear setting within the application, ideally on a per-task-type basis. Using the taxonomy from our first article, the settings could be:
- Observe & Suggest
I want to be notified of opportunities or issues, but the agent will never propose a plan. - Plan & Propose
The agent can create plans, but I must review every one before any action is taken. - Act with Confirmation
For familiar tasks, the agent can prepare actions, and I will give a final go/no-go confirmation. - Act Autonomously
For pre-approved tasks (e.g., disputing charges under $50), the agent can act independently and notify me after the fact.
An email assistant, for example, could have a separate autonomy dial for scheduling meetings versus sending emails on the user’s behalf. This granularity is key, as it reflects the nuanced reality of a user’s trust.
When to Prioritize This Pattern
Prioritize this in systems where tasks vary widely in risk and personal preference (e.g., financial management tools, communication platforms). It is essential for onboarding, allowing users to start with low autonomy and increase it as their confidence grows.
Risk of Omission
Without this, users who experience a single failure will abandon the agent completely rather than simply dialing back its permissions.
Metrics for Success:
- Trust Density
Percentage breakdown of users per setting (e.g., 20% Suggest, 50% Confirm, 30% Auto). - Setting Churn
Number of Setting Changes / Total Active Users per month. High churn indicates trust volatility.
3. The Explainable Rationale: Answering Why?
After taking an action, a good partner explains their reasoning. This pattern is the open communication that follows an action, answering Why? before it’s even asked. “I did that because you’ve told me in the past that you prefer X.”
When an agent acts, especially autonomously, the immediate question in the user’s mind is often, Why did it do that? The Explainable Rationale pattern proactively answers this question, providing a concise justification for the agent’s decisions. This is not a technical log file. In my first article of this series, we discussed translating system primitives into user-facing language to prevent deception. This pattern is the practical application of that principle. It transforms the raw logic into a human-readable explanation grounded in the user’s own stated preferences and prior inputs.
Psychological Underpinning
When an agent’s actions are explainable, they feel logical rather than random, helping the user build an accurate mental model of how the agent thinks.
Effective Rationales:
- Grounded in Precedent
The best explanations link back to a rule, preference, or prior action. - Simple and Direct
Avoid complex conditional logic. Use a simple “Because you said X, I did Y” structure.
Returning to the travel example, after the flight is rebooked autonomously, the user might see this in their notification feed:
I’ve rebooked your canceled flight.[ View New Itinerary ] [ Undo this Action ]
- New Flight: Delta 789, departing at 2:30 PM.
- Why I took this action:
- Your original flight was canceled by the airline.
- You’ve pre-approved autonomous rebooking for same-day, non-stop flights.
The rationale is clear, defensible, and reinforces the idea that the agent is operating within the boundaries the user established.
When to Prioritize This Pattern
Prioritize it for any autonomous action where the reasoning isn’t immediately obvious from the context, especially for actions that happen in the background or are triggered by an external event (like the flight cancellation example).
Risk of Omission
Without this, users interpret valid autonomous actions as random behavior or ‘bugs,’ preventing them from forming a correct mental model.
Metrics for Success:
- Why? Ticket Volume
Number of support tickets tagged “Agent Behavior — Unclear” per 1,000 active users. - Rationale Validation
Percentage of users who rate the explanation as ‘Helpful’ in post-interaction microsurveys.
4. The Confidence Signal
This pattern is about the agent being self-aware in the relationship. By communicating its own confidence, it helps the user decide when to trust its judgment and when to apply more scrutiny.
To help users calibrate their own trust, the agent should surface its own confidence in its plans and actions. This makes the agent’s internal state more legible and helps the user decide when to scrutinize a decision more closely.
Psychological Underpinning
Surfacing uncertainty helps prevent automation bias, encouraging users to scrutinize low-confidence plans rather than blindly accepting them.
Implementation:
- Confidence Score
A simple percentage (e.g., Confidence: 95%) can be a quick, scannable indicator. - Scope Declaration
A clear statement of the agent’s area of expertise (e.g., Scope: Travel bookings only) helps manage user expectations and prevents them from asking the agent to perform tasks it’s not designed for. - Visual Cues
A green checkmark can denote high confidence, while a yellow question mark can indicate uncertainty, prompting the user to review more carefully.
When to Prioritize This Pattern
Prioritize when the agent’s performance can vary significantly based on the quality of input data or the ambiguity of the task. It is especially valuable in expert systems (e.g., medical aids, code assistants) where a human must critically evaluate the AI’s output.
Risk of Omission
Without this, users will fall victim to automation bias, blindly accepting low-confidence hallucinations, or anxiously double-check high-confidence work.
Metrics for Success:
- Calibration Score
Pearson correlation between Model Confidence Score and User Acceptance Rate. Target > 0.8. - Scrutiny Delta
Difference between the average review time of low-confidence plans and high-confidence plans. Expected to be positive (e.g., +12 seconds).
5. The Action Audit & Undo: The Ultimate Safety Net
Trust requires knowing you can recover from a mistake. The Undo function is the ultimate relationship safety net, assuring the user that even if the agent misunderstands, the consequences are not catastrophic.
The single most powerful mechanism for building user confidence is the ability to easily reverse an agent’s action. A persistent, easy-to-read Action Audit log, with a prominent Undo button for every possible action, is the ultimate safety net. It dramatically lowers the perceived risk of granting autonomy.
Psychological Underpinning
Knowing that a mistake can be easily undone creates psychological safety, encouraging users to delegate tasks without fear of irreversible consequences.
Design Best Practices:
- Timeline View
A chronological log of all agent-initiated actions is the most intuitive format. - Clear Status Indicators
Show whether an action was successful, is in progress, or has been undone. - Time-Limited Undos
For actions that become irreversible after a certain point (e.g., a non-refundable booking), the UI must clearly communicate this time window (e.g., Undo available for 15 minutes). This transparency about the system’s limitations is just as important as the undo capability itself. Being honest about when an action becomes permanent builds trust.
When to Prioritize This Pattern
This is a foundational pattern that should be implemented in nearly all agentic systems. It is absolutely non-negotiable when introducing autonomous features or when the cost of an error (financial, social, or data-related) is high.
Risk of Omission
Without this, one error permanently destroys trust, as users realize they have no safety net.
Metrics for Success:
- Reversion Rate
Undone Actions / Total Actions Performed. If the Reversion Rate > 5% for a specific task, disable automation for that task. - Safety Net Conversion
Percentage of users who upgrade to Act Autonomously within 7 days of successfully using Undo.
6. The Escalation Pathway: Handling Uncertainty Gracefully
A smart partner knows when to ask for help instead of guessing. This pattern allows the agent to handle ambiguity gracefully by escalating to the user, demonstrating a humility that builds, rather than erodes, trust.
Even the most advanced agent will encounter situations where it is uncertain about the user’s intent or the best course of action. How it handles this uncertainty is a defining moment. A well-designed agent doesn’t guess; it escalates.
Psychological Underpinning
When an agent acknowledges its limits rather than guessing, it builds trust by respecting the user’s authority in ambiguous situations.
Escalation Patterns Include:
- Requesting Clarification
“You mentioned ‘next Tuesday.’ Do you mean September 30th or October 7th?” - Presenting Options
“I found three flights that match your criteria. Which one looks best to you?” - Requesting Human Intervention
For high-stakes or highly ambiguous tasks, the agent should have a clear pathway to loop in a human expert or support agent. The prompt might be: “This transaction seems unusual, and I’m not confident about how to proceed. Would you like me to flag this for a human agent to review?”
When to Prioritize This Pattern
Prioritize in domains where user intent can be ambiguous or highly context-dependent (e.g., natural language interactions, complex data queries). Use this whenever the agent operates with incomplete information or when multiple correct paths exist.
Risk of Omission
Without this, the agent will eventually make a confident, catastrophic guess that alienates the user.
Metrics for Success:
- Escalation Frequency
Agent Requests for Help / Total Tasks. Healthy range: 5-15%. - Recovery Success Rate
Tasks Completed Post-Escalation / Total Escalations. Target > 90%.
| Pattern | Best For | Primary Risk | Key Metric |
|---|---|---|---|
| Intent Preview | Irreversible or financial actions | User feels ambushed | >85% Acceptance Rate |
| Autonomy Dial | Tasks with variable risk levels | Total feature abandonment | Setting Churn |
| Explainable Rationale | Background or autonomous tasks | User perceives bugs | “Why?” Ticket Volume |
| Confidence Signal | Expert or high-stakes systems | Automation bias | Scrutiny Delta |
| Action Audit & Undo | All agentic systems | Permanent loss of trust | <5% Reversion Rate |
| Escalation Pathway | Ambiguous user intent | Confident, catastrophic guesses | >90% Recovery Success |
Table 1: Summary of Agentic AI UX patterns. Remember to adjust the metrics based on your specific domain risk and needs.
Designing for Repair and Redress
This is learning how to apologize effectively. A good apology acknowledges the mistake, fixes the damage, and promises to learn from it.
Errors are not a possibility; they are an inevitability.
“
Empathic Apologies and Clear Remediation
When an agent makes a mistake, the error message is the apology. It must be designed with psychological precision. This moment is a critical opportunity to demonstrate accountability. From a service design perspective, this is where companies can use the service recovery paradox: the phenomenon where a customer who experiences a service failure, followed by a successful and empathetic recovery, can actually become more loyal than a customer who never experienced a failure at all. A well-handled mistake can be a more powerful trust-building event than a long history of flawless execution.
The key is treating the error as a relationship rupture that needs to be mended. This involves:
- Acknowledge the Error
The message should state clearly and simply that a mistake was made.
Example: I incorrectly transferred funds. - State the Immediate Correction
Immediately follow up with the remedial action.
Example: I have reversed the action, and the funds have been returned to your account. - Provide a Path for Further Help
Always offer a clear link to human support. This de-escalates frustration and shows that there is a system of accountability beyond the agent itself.
A well-designed repair UI might look like this:
We made a mistake on your recent transfer.
I apologize. I transferred $250 to the wrong account.
✔ Corrective Action: The transfer has been reversed, and your $250 has been refunded.
✔ Next Steps: The incident has been flagged for internal review to prevent it from happening again.
Need further help? [ Contact Support ]
Building the Governance Engine for Safe Innovation
The design patterns described above are the user-facing controls, but they cannot function effectively without a robust internal support structure. This is not about creating bureaucratic hurdles; it is about building a strategic advantage. An organization with a mature governance framework can ship more ambitious agentic features with greater speed and confidence, knowing that the necessary guardrails are in place to mitigate brand risk. This governance engine turns safety from a checklist into a competitive asset.
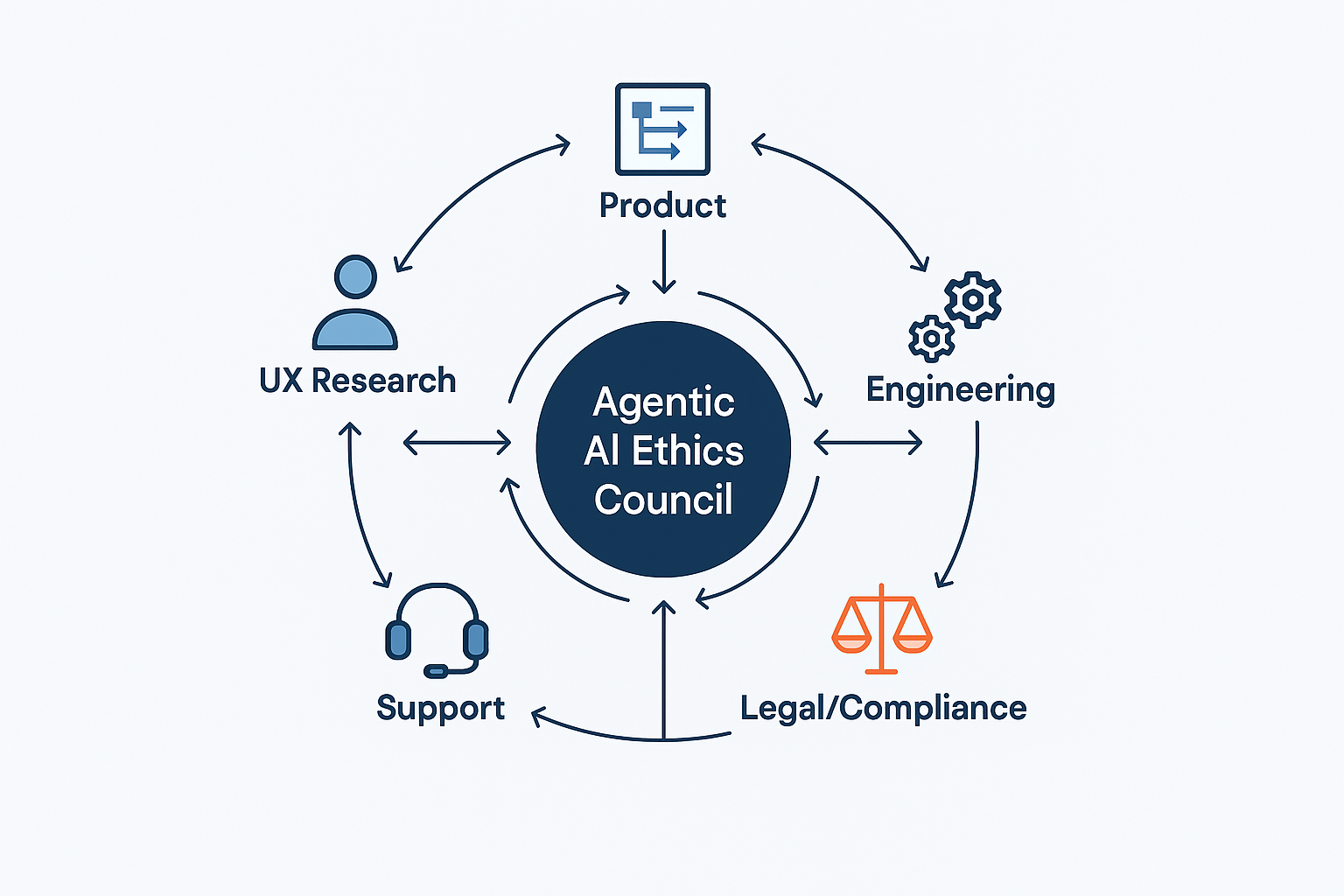
This engine should function as a formal governance body, an Agentic AI Ethics Council, comprising a cross-functional alliance of UX, Product, and Engineering, with vital support from Legal, Compliance, and Support. In smaller organizations, these ‘Council’ roles often collapse into a single triad of Product, Engineering, and Design leads.
A Checklist for Governance
- Legal/Compliance
This team is the first line of defense, ensuring the agent’s potential actions stay within regulatory and legal boundaries. They help define the hard no-go zones for autonomous action. - Product
The product manager is the steward of the agent’s purpose. They define and monitor its operational boundaries through a formal autonomy policy that documents what the agent is and is not allowed to do. They own the Agent Risk Register. - UX Research
This team is the voice of the user’s trust and anxiety. They are responsible for a recurring process for running trust calibration studies, simulated misbehavior tests, and qualitative interviews to understand the user’s evolving mental model of the agent. - Engineering
This team builds the technical underpinnings of trust. They must architect the system for robust logging, one-click undo functionality, and the hooks needed to generate clear, explainable rationales. - Support
These teams are on the front lines of failure. They must be trained and equipped to handle incidents caused by agent errors, and they must have a direct feedback loop to the Ethics Council to report on real-world failure patterns.
This governance structure should maintain a set of living documents, including an Agent Risk Register that proactively identifies potential failure modes, Action Audit Logs that are regularly reviewed, and the formal Autonomy Policy Documentation.
Where to Start: A Phased Approach for Product Leaders
For product managers and executives, integrating agentic AI can feel like a monumental task. The key is to approach it not as a single launch, but as a phased journey of building both technical capability and user trust in parallel. This roadmap allows your organization to learn and adapt, ensuring each step is built on a solid foundation.
Phase 1: Foundational Safety (Suggest & Propose)
The initial goal is to build the bedrock of trust without taking significant autonomous risks. In this phase, the agent’s power is limited to analysis and suggestion.
- Implement a rock-solid Intent Preview: This is your core interaction model. Get users comfortable with the idea of the agent formulating plans, while keeping the user in full control of execution.
- Build the Action Audit & Undo infrastructure: Even if the agent isn’t acting autonomously yet, build the technical scaffolding for logging and reversal. This prepares your system for the future and builds user confidence that a safety net exists.
Phase 2: Calibrated Autonomy (Act with Confirmation)
Once users are comfortable with the agent’s proposals, you can begin to introduce low-risk autonomy. This phase is about teaching users how the agent thinks and letting them set their own pace.
- Introduce the Autonomy Dial with limited settings: Start by allowing users to grant the agent the power to Act with Confirmation.
- Deploy the Explainable Rationale: For every action the agent prepares, provide a clear explanation. This demystifies the agent’s logic and reinforces that it is operating based on the user’s own preferences.
Phase 3: Proactive Delegation (Act Autonomously)
This is the final step, taken only after you have clear data from the previous phases demonstrating that users trust the system.
- Enable Act Autonomously for specific, pre-approved tasks: Use the data from Phase 2 (e.g., high Proceed rates, low Undo rates) to identify the first set of low-risk tasks that can be fully automated.
- Monitor and Iterate: The launch of autonomous features is not the end, but the beginning of a continuous cycle of monitoring performance, gathering user feedback, and refining the agent’s scope and behavior based on real-world data.
Design As The Ultimate Safety Lever
The emergence of agentic AI represents a new frontier in human-computer interaction. It promises a future where technology can proactively reduce our burdens and streamline our lives. But this power comes with profound responsibility.
“
As UX professionals, product managers, and leaders, our role is to act as the stewards of that trust. By implementing clear design patterns for control and consent, designing thoughtful pathways for repair, and building robust governance frameworks, we create the essential safety levers that make agentic AI viable. We are not just designing interfaces; we are architecting relationships. The future of AI’s utility and acceptance rests on our ability to design these complex systems with wisdom, foresight, and a deep-seated respect for the user’s ultimate authority.


